 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistency Conditions for Differentiable Surrogate Losses
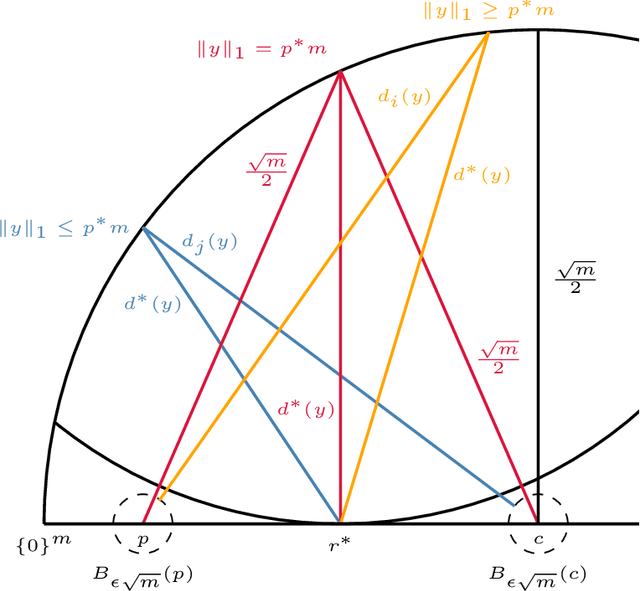
May 19, 2025The statistical consistency of surrogate losses for discrete prediction tasks is often checked via the condition of calibration. However, directly verifying calibration can be arduous. Recent work shows that for polyhedral surrogates, a less arduous condition, indirect elicitation (IE), is still equivalent to calibration. We give the first results of this type for non-polyhedral surrogates, specifically the class of convex differentiable losses. We first prove that under mild conditions, IE and calibration are equivalent for one-dimensional losses in this class. We construct a counter-example that shows that this equivalence fails in higher dimensions. This motivates the introduction of strong IE, a strengthened form of IE that is equally easy to verify. We establish that strong IE implies calibration for differentiable surrogates and is both necessary and sufficient for strongly convex, differentiable surrogates. Finally, we apply these results to a range of problems to demonstrate the power of IE and strong IE for designing and analyzing consistent differentiable surrogates.
Structured Prediction with Abstention via the Lovász Hinge
May 09, 2025The Lov\'asz hinge is a convex loss function proposed for binary structured classification, in which k related binary predictions jointly evaluated by a submodular function. Despite its prevalence in image segmentation and related tasks, the consistency of the Lov\'asz hinge has remained open. We show that the Lov\'asz hinge is inconsistent with its desired target unless the set function used for evaluation is modular. Leveraging the embedding framework of Finocchiaro et al. (2024), we find the target loss for which the Lov\'asz hinge is consistent. This target, which we call the structured abstain problem, is a variant of selective classification for structured prediction that allows one to abstain on any subset of the k binary predictions. We derive a family of link functions, each of which is simultaneously consistent for all polymatroids, a subset of submodular set functions. We then give sufficient conditions on the polymatroid for the structured abstain problem to be tightly embedded by the Lov\'asz hinge, meaning no target prediction is redundant. We experimentally demonstrate the potential of the structured abstain problem for interpretability in structured classification tasks. Finally, for the multiclass setting, we show that one can combine the binary encoding construction of Ramaswamy et al. (2018) with our link construction to achieve an efficient consistent surrogate for a natural multiclass generalization of the structured abstain problem.
Hedging and Approximate Truthfulness in Traditional Forecasting Competitions
Sep 28, 2024

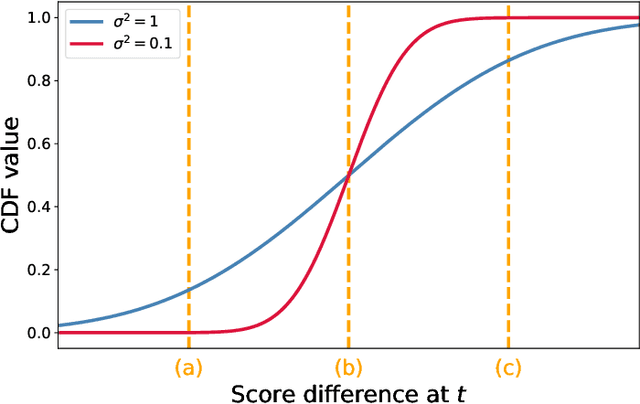
In forecasting competitions, the traditional mechanism scores the predictions of each contestant against the outcome of each event, and the contestant with the highest total score wins. While it is well-known that this traditional mechanism can suffer from incentive issues, it is folklore that contestants will still be roughly truthful as the number of events grows. Yet thus far the literature lacks a formal analysis of this traditional mechanism. This paper gives the first such analysis. We first demonstrate that the ''long-run truthfulness'' folklore is false: even for arbitrary numbers of events, the best forecaster can have an incentive to hedge, reporting more moderate beliefs to increase their win probability. On the positive side, however, we show that two contestants will be approximately truthful when they have sufficient uncertainty over the relative quality of their opponent and the outcomes of the events, a case which may arise in practice.
Forecasting Competitions with Correlated Events
Mar 24, 2023Beginning with Witkowski et al. [2022], recent work on forecasting competitions has addressed incentive problems with the common winner-take-all mechanism. Frongillo et al. [2021] propose a competition mechanism based on follow-the-regularized-leader (FTRL), an online learning framework. They show that their mechanism selects an $\epsilon$-optimal forecaster with high probability using only $O(\log(n)/\epsilon^2)$ events. These works, together with all prior work on this problem thus far, assume that events are independent. We initiate the study of forecasting competitions for correlated events. To quantify correlation, we introduce a notion of block correlation, which allows each event to be strongly correlated with up to $b$ others. We show that under distributions with this correlation, the FTRL mechanism retains its $\epsilon$-optimal guarantee using $O(b^2 \log(n)/\epsilon^2)$ events. Our proof involves a novel concentration bound for correlated random variables which may be of broader interest.
Proper losses for discrete generative models
Nov 07, 2022We initiate the study of proper losses for evaluating generative models in the discrete setting. Unlike traditional proper losses, we treat both the generative model and the target distribution as black-boxes, only assuming ability to draw i.i.d. samples. We define a loss to be black-box proper if the generative distribution that minimizes expected loss is equal to the target distribution. Using techniques from statistical estimation theory, we give a general construction and characterization of black-box proper losses: they must take a polynomial form, and the number of draws from the model and target distribution must exceed the degree of the polynomial. The characterization rules out a loss whose expectation is the cross-entropy between the target distribution and the model. By extending the construction to arbitrary sampling schemes such as Poisson sampling, however, we show that one can construct such a loss.
Consistent Polyhedral Surrogates for Top-$k$ Classification and Variants
Jul 18, 2022
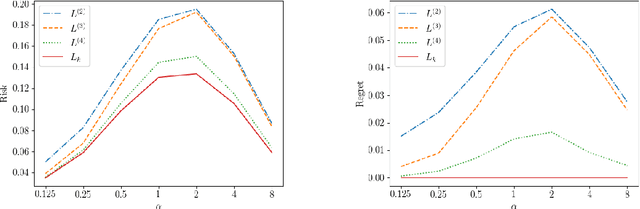

Top-$k$ classification is a generalization of multiclass classification used widely in information retrieval, image classification, and other extreme classification settings. Several hinge-like (piecewise-linear) surrogates have been proposed for the problem, yet all are either non-convex or inconsistent. For the proposed hinge-like surrogates that are convex (i.e., polyhedral), we apply the recent embedding framework of Finocchiaro et al. (2019; 2022) to determine the prediction problem for which the surrogate is consistent. These problems can all be interpreted as variants of top-$k$ classification, which may be better aligned with some applications. We leverage this analysis to derive constraints on the conditional label distributions under which these proposed surrogates become consistent for top-$k$. It has been further suggested that every convex hinge-like surrogate must be inconsistent for top-$k$. Yet, we use the same embedding framework to give the first consistent polyhedral surrogate for this problem.
The Structured Abstain Problem and the Lovász Hinge
Mar 17, 2022


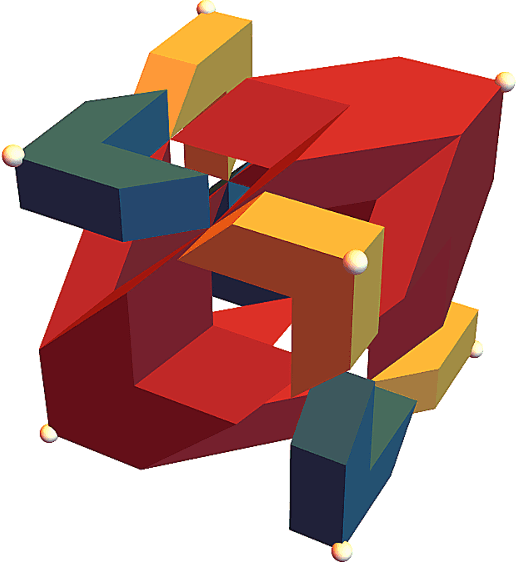
The Lov\'asz hinge is a convex surrogate recently proposed for structured binary classification, in which $k$ binary predictions are made simultaneously and the error is judged by a submodular set function. Despite its wide usage in image segmentation and related problems, its consistency has remained open. We resolve this open question, showing that the Lov\'asz hinge is inconsistent for its desired target unless the set function is modular. Leveraging a recent embedding framework, we instead derive the target loss for which the Lov\'asz hinge is consistent. This target, which we call the structured abstain problem, allows one to abstain on any subset of the $k$ predictions. We derive two link functions, each of which are consistent for all submodular set functions simultaneously.
No-Regret Learning in Games is Turing Complete
Feb 24, 2022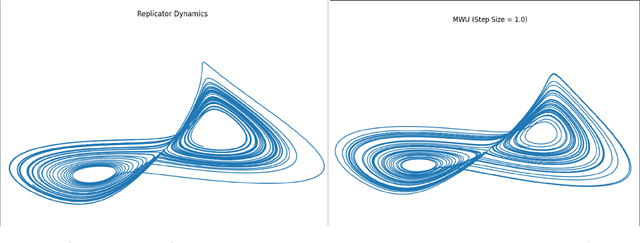
Games are natural models for multi-agent machine learning settings, such as generative adversarial networks (GANs). The desirable outcomes from algorithmic interactions in these games are encoded as game theoretic equilibrium concepts, e.g. Nash and coarse correlated equilibria. As directly computing an equilibrium is typically impractical, one often aims to design learning algorithms that iteratively converge to equilibria. A growing body of negative results casts doubt on this goal, from non-convergence to chaotic and even arbitrary behaviour. In this paper we add a strong negative result to this list: learning in games is Turing complete. Specifically, we prove Turing completeness of the replicator dynamic on matrix games, one of the simplest possible settings. Our results imply the undecicability of reachability problems for learning algorithms in games, a special case of which is determining equilibrium convergence.
Surrogate Regret Bounds for Polyhedral Losses
Oct 26, 2021Surrogate risk minimization is an ubiquitous paradigm in supervised machine learning, wherein a target problem is solved by minimizing a surrogate loss on a dataset. Surrogate regret bounds, also called excess risk bounds, are a common tool to prove generalization rates for surrogate risk minimization. While surrogate regret bounds have been developed for certain classes of loss functions, such as proper losses, general results are relatively sparse. We provide two general results. The first gives a linear surrogate regret bound for any polyhedral (piecewise-linear and convex) surrogate, meaning that surrogate generalization rates translate directly to target rates. The second shows that for sufficiently non-polyhedral surrogates, the regret bound is a square root, meaning fast surrogate generalization rates translate to slow rates for the target. Together, these results suggest polyhedral surrogates are optimal in many cases.
Learning in Matrix Games can be Arbitrarily Complex
Mar 05, 2021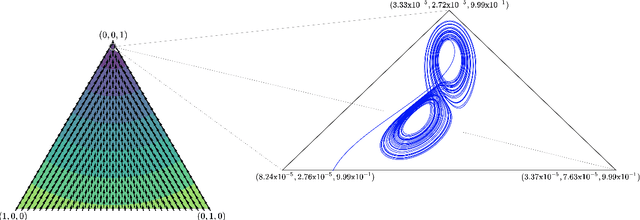
A growing number of machine learning architectures, such as Generative Adversarial Networks, rely on the design of games which implement a desired functionality via a Nash equilibrium. In practice these games have an implicit complexity (e.g. from underlying datasets and the deep networks used) that makes directly computing a Nash equilibrium impractical or impossible. For this reason, numerous learning algorithms have been developed with the goal of iteratively converging to a Nash equilibrium. Unfortunately, the dynamics generated by the learning process can be very intricate and instances of training failure hard to interpret. In this paper we show that, in a strong sense, this dynamic complexity is inherent to games. Specifically, we prove that replicator dynamics, the continuous-time analogue of Multiplicative Weights Update, even when applied in a very restricted class of games -- known as finite matrix games -- is rich enough to be able to approximate arbitrary dynamical systems. Our results are positive in the sense that they show the nearly boundless dynamic modelling capabilities of current machine learning practices, but also negative in implying that these capabilities may come at the cost of interpretability. As a concrete example, we show how replicator dynamics can effectively reproduce the well-known strange attractor of Lonrenz dynamics (the "butterfly effect") while achieving no regret.