 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModelisation of competition between times series
Sep 30, 2020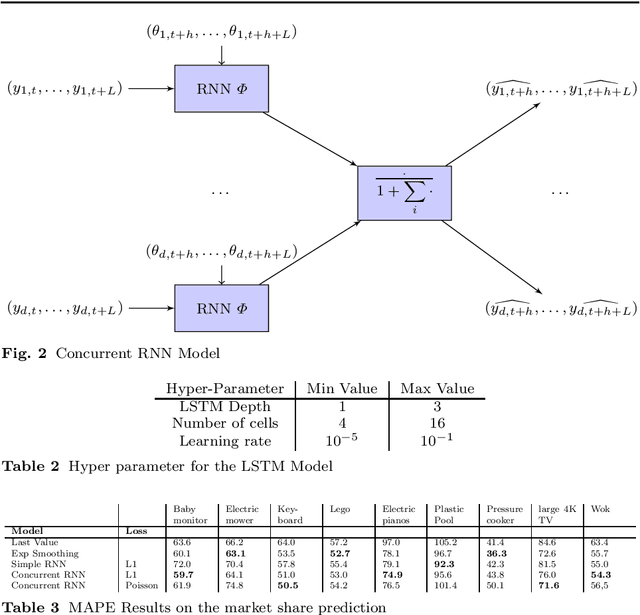
Competition between times series arises naturally in sales forecasting or in population modelisation. In this article, a model for the behavior of such high-dimensional time series is proposed. This model is based on the prerequisite that the total sum of the time series is distributed between its component following a 'competitiveness' factor inherent to each component. A confidence bound is proposed for the estimation of this model. Then, this model is applied to real-world E-commerce data using a recurrent neural network architecture to compute the model. It improves the results of standard RNN models in most cases.
Deviation bound for non-causal machine learning
Sep 18, 2020
Concentration inequality are widely used for analysing machines learning algorithms. However, current concentration inequalities cannot be applied to the most popular deep neural network, notably in NLP processing. This is mostly due to the non-causal nature of this data. In this paper, a framework for modelling non-causal random fields is provided. A McDiarmid-type concentration inequality is obtained for this framework. In order to do so, we introduce a local i.i.d approximation of the non-causal random field.
Hierarchical robust aggregation of sales forecasts at aggregated levels in e-commerce, based on exponential smoothing and Holt's linear trend method
Jun 05, 2020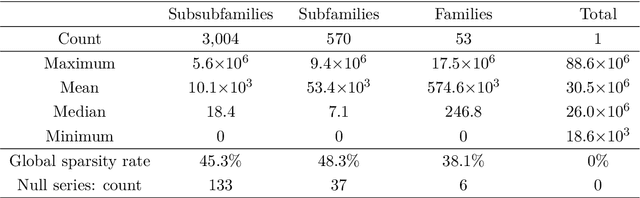
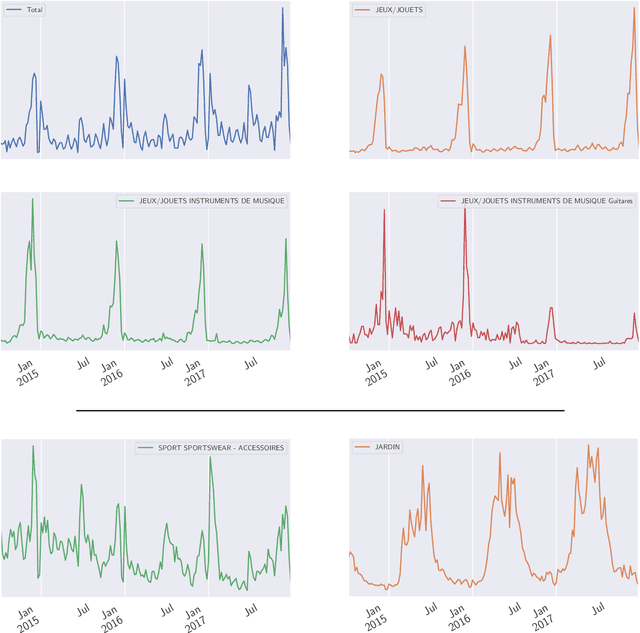
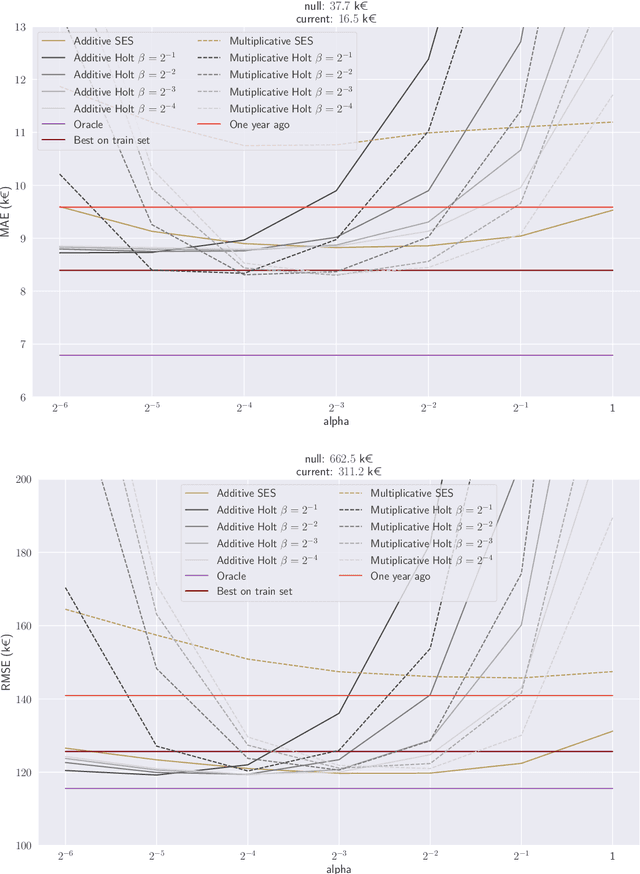
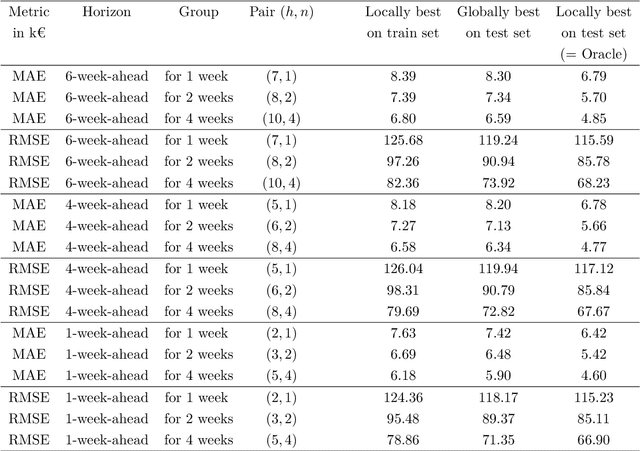
We revisit the interest of classical statistical techniques for sales forecasting like exponential smoothing and extensions thereof (as Holt's linear trend method). We do so by considering ensemble forecasts, given by several instances of these classical techniques tuned with different (sets of) parameters, and by forming convex combinations of the elements of ensemble forecasts over time, in a robust and sequential manner. The machine-learning theory behind this is called "robust online aggregation", or "prediction with expert advice", or "prediction of individual sequences" (see Cesa-Bianchi and Lugosi, 2006). We apply this methodology to a hierarchical data set of sales provided by the e-commerce company Cdiscount and output forecasts at the levels of subsubfamilies, subfamilies and families of items sold, for various forecasting horizons (up to 6-week-ahead). The performance achieved is better than what would be obtained by optimally tuning the classical techniques on a train set and using their forecasts on the test set. The performance is also good from an intrinsic point of view (in terms of mean absolute percentage of error). While getting these better forecasts of sales at the levels of subsubfamilies, subfamilies and families is interesting per se, we also suggest to use them as additional features when forecasting demand at the item level.
A multi-series framework for demand forecasts in E-commerce
May 31, 2019



Sales forecasts are crucial for the E-commerce business. State-of-the-art techniques typically apply only univariate methods to make prediction for each series independently. However, due to the short nature of sales times series in E-commerce, univariate methods don't apply well. In this article, we propose a global model which outperforms state-of-the-art models on real dataset. It is achieved by using Tree Boosting Methods that exploit non-linearity and cross-series information. We also proposed a preprocessing framework to overcome the inherent difficulties in the E-commerce data. In particular, we use different schemes to limit the impact of the volatility of the data.
High dimensional VAR with low rank transition
May 02, 2019



We propose a vector auto-regressive (VAR) model with a low-rank constraint on the transition matrix. This new model is well suited to predict high-dimensional series that are highly correlated, or that are driven by a small number of hidden factors. We study estimation, prediction, and rank selection for this model in a very general setting. Our method shows excellent performances on a wide variety of simulated datasets. On macro-economic data from Giannone et al. (2015), our method is competitive with state-of-the-art methods in small dimension, and even improves on them in high dimension.