 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimation of population size based on capture recapture designs and evaluation of the estimation reliability
May 12, 2021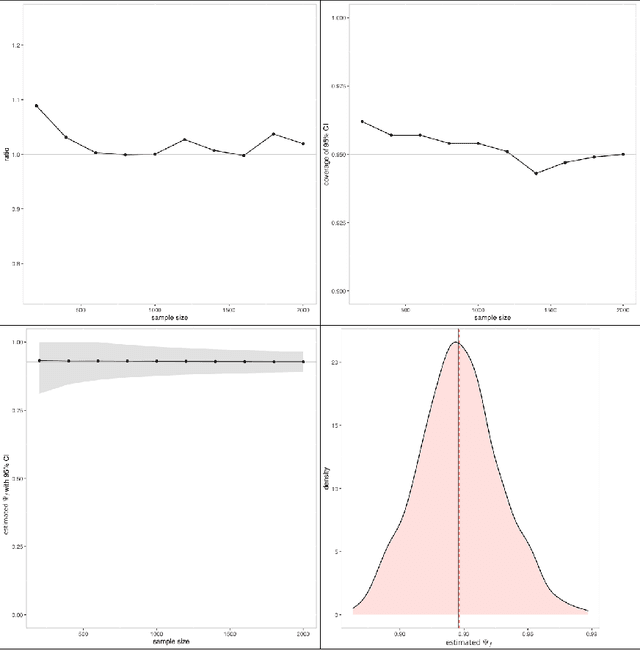
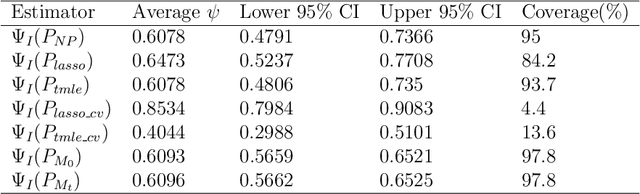
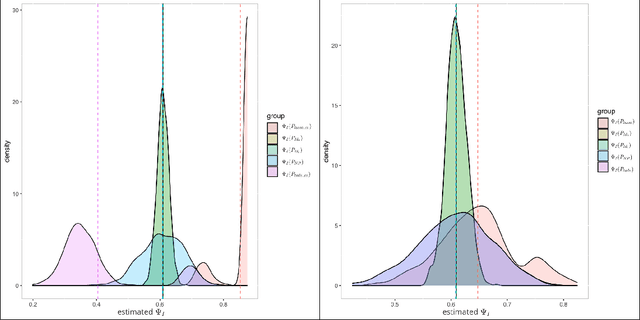
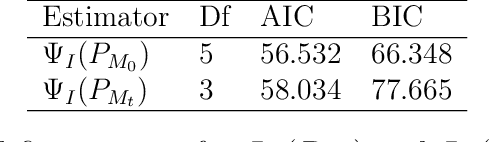
We propose a modern method to estimate population size based on capture-recapture designs of K samples. The observed data is formulated as a sample of n i.i.d. K-dimensional vectors of binary indicators, where the k-th component of each vector indicates the subject being caught by the k-th sample, such that only subjects with nonzero capture vectors are observed. The target quantity is the unconditional probability of the vector being nonzero across both observed and unobserved subjects. We cover models assuming a single constraint (identification assumption) on the K-dimensional distribution such that the target quantity is identified and the statistical model is unrestricted. We present solutions for linear and non-linear constraints commonly assumed to identify capture-recapture models, including no K-way interaction in linear and log-linear models, independence or conditional independence. We demonstrate that the choice of constraint has a dramatic impact on the value of the estimand, showing that it is crucial that the constraint is known to hold by design. For the commonly assumed constraint of no K-way interaction in a log-linear model, the statistical target parameter is only defined when each of the $2^K - 1$ observable capture patterns is present, and therefore suffers from the curse of dimensionality. We propose a targeted MLE based on undersmoothed lasso model to smooth across the cells while targeting the fit towards the single valued target parameter of interest. For each identification assumption, we provide simulated inference and confidence intervals to assess the performance on the estimator under correct and incorrect identifying assumptions. We apply the proposed method, alongside existing estimators, to estimate prevalence of a parasitic infection using multi-source surveillance data from a region in southwestern China, under the four identification assumptions.
Machine-learning classifiers for logographic name matching in public health applications: approaches for incorporating phonetic, visual, and keystroke similarity in large-scale probabilistic record linkage
Jan 07, 2020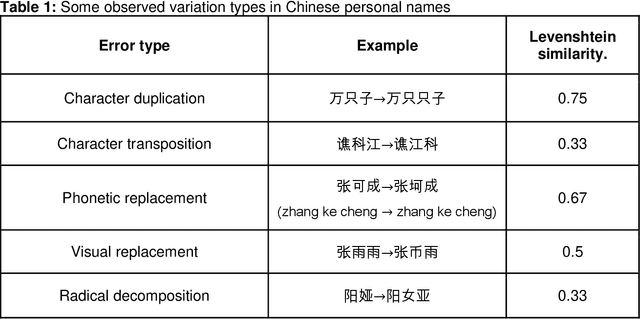
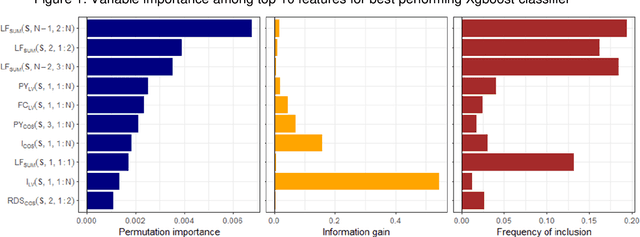

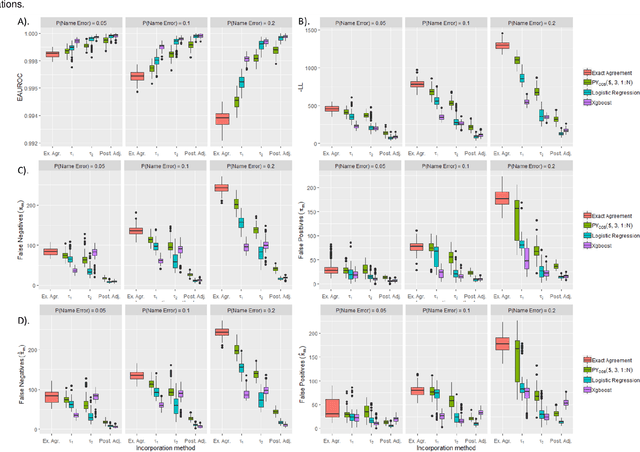
Approximate string-matching methods to account for complex variation in highly discriminatory text fields, such as personal names, can enhance probabilistic record linkage. However, discriminating between matching and non-matching strings is challenging for logographic scripts, where similarities in pronunciation, appearance, or keystroke sequence are not directly encoded in the string data. We leverage a large Chinese administrative dataset with known match status to develop logistic regression and Xgboost classifiers integrating measures of visual, phonetic, and keystroke similarity to enhance identification of potentially-matching name pairs. We evaluate three methods of leveraging name similarity scores in large-scale probabilistic record linkage, which can adapt to varying match prevalence and information in supporting fields: (1) setting a threshold score based on predicted quality of name-matching across all record pairs; (2) setting a threshold score based on predicted discriminatory power of the linkage model; and (3) using empirical score distributions among matches and nonmatches to perform Bayesian adjustment of matching probabilities estimated from exact-agreement linkage. In experiments on holdout data, as well as data simulated with varying name error rates and supporting fields, a logistic regression classifier incorporated via the Bayesian method demonstrated marked improvements over exact-agreement linkage with respect to discriminatory power, match probability estimation, and accuracy, reducing the total number of misclassified record pairs by 21% in test data and up to an average of 93% in simulated datasets. Our results demonstrate the value of incorporating visual, phonetic, and keystroke similarity for logographic name matching, as well as the promise of our Bayesian approach to leverage name-matching within large-scale record linkage.