 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing n-aksaras to model Sanskrit and Sanskrit-adjacent texts
Jan 30, 2023Despite -- or perhaps because of -- their simplicity, n-grams, or contiguous sequences of tokens, have been used with great success in computational linguistics since their introduction in the late 20th century. Recast as k-mers, or contiguous sequences of monomers, they have also found applications in computational biology. When applied to the analysis of texts, n-grams usually take the form of sequences of words. But if we try to apply this model to the analysis of Sanskrit texts, we are faced with the arduous task of, firstly, resolving sandhi to split a phrase into words, and, secondly, splitting long compounds into their components. This paper presents a simpler method of tokenizing a Sanskrit text for n-grams, by using n-aksaras, or contiguous sequences of aksaras. This model reduces the need for sandhi resolution, making it much easier to use on raw text. It is also possible to use this model on Sanskrit-adjacent texts, e.g., a Tamil commentary on a Sanskrit text. As a test case, the commentaries on Amarakosa 1.0.1 have been modelled as n-aksaras, showing patterns of text reuse across ten centuries and nine languages. Some initial observations are made concerning Buddhist commentarial practices.
Machine-learning classifiers for logographic name matching in public health applications: approaches for incorporating phonetic, visual, and keystroke similarity in large-scale probabilistic record linkage
Jan 07, 2020
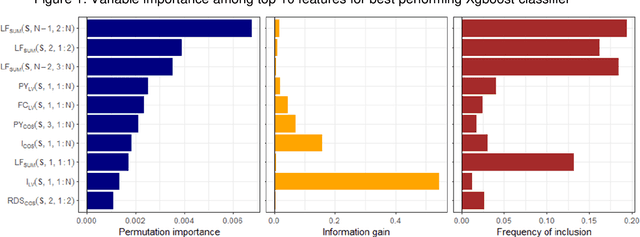

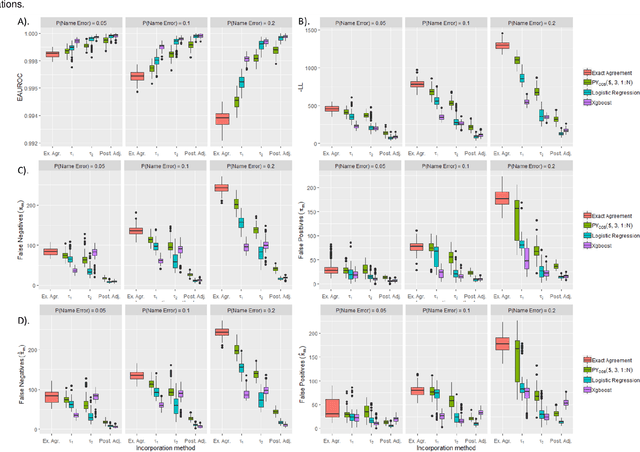
Approximate string-matching methods to account for complex variation in highly discriminatory text fields, such as personal names, can enhance probabilistic record linkage. However, discriminating between matching and non-matching strings is challenging for logographic scripts, where similarities in pronunciation, appearance, or keystroke sequence are not directly encoded in the string data. We leverage a large Chinese administrative dataset with known match status to develop logistic regression and Xgboost classifiers integrating measures of visual, phonetic, and keystroke similarity to enhance identification of potentially-matching name pairs. We evaluate three methods of leveraging name similarity scores in large-scale probabilistic record linkage, which can adapt to varying match prevalence and information in supporting fields: (1) setting a threshold score based on predicted quality of name-matching across all record pairs; (2) setting a threshold score based on predicted discriminatory power of the linkage model; and (3) using empirical score distributions among matches and nonmatches to perform Bayesian adjustment of matching probabilities estimated from exact-agreement linkage. In experiments on holdout data, as well as data simulated with varying name error rates and supporting fields, a logistic regression classifier incorporated via the Bayesian method demonstrated marked improvements over exact-agreement linkage with respect to discriminatory power, match probability estimation, and accuracy, reducing the total number of misclassified record pairs by 21% in test data and up to an average of 93% in simulated datasets. Our results demonstrate the value of incorporating visual, phonetic, and keystroke similarity for logographic name matching, as well as the promise of our Bayesian approach to leverage name-matching within large-scale record linkage.