 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine-learning classifiers for logographic name matching in public health applications: approaches for incorporating phonetic, visual, and keystroke similarity in large-scale probabilistic record linkage
Jan 07, 2020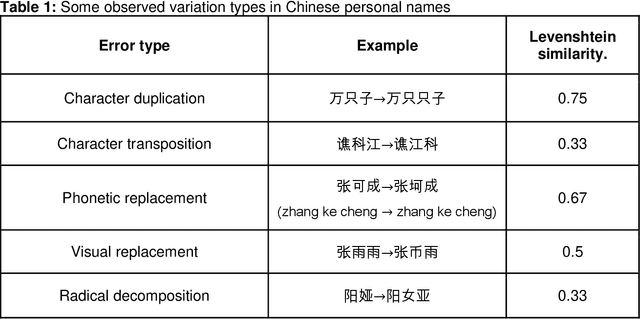
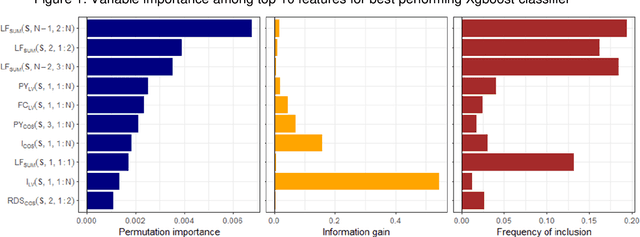

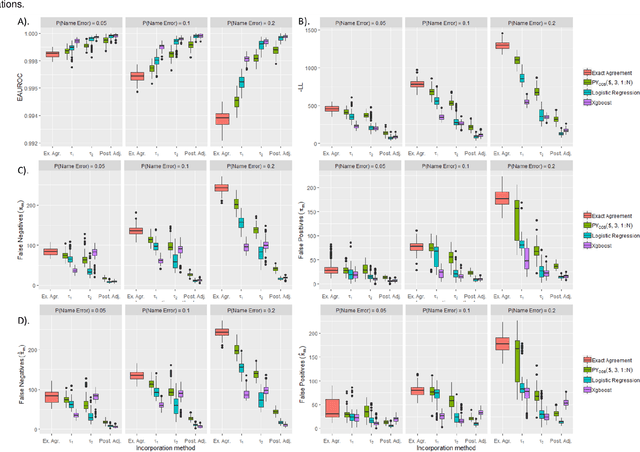
Approximate string-matching methods to account for complex variation in highly discriminatory text fields, such as personal names, can enhance probabilistic record linkage. However, discriminating between matching and non-matching strings is challenging for logographic scripts, where similarities in pronunciation, appearance, or keystroke sequence are not directly encoded in the string data. We leverage a large Chinese administrative dataset with known match status to develop logistic regression and Xgboost classifiers integrating measures of visual, phonetic, and keystroke similarity to enhance identification of potentially-matching name pairs. We evaluate three methods of leveraging name similarity scores in large-scale probabilistic record linkage, which can adapt to varying match prevalence and information in supporting fields: (1) setting a threshold score based on predicted quality of name-matching across all record pairs; (2) setting a threshold score based on predicted discriminatory power of the linkage model; and (3) using empirical score distributions among matches and nonmatches to perform Bayesian adjustment of matching probabilities estimated from exact-agreement linkage. In experiments on holdout data, as well as data simulated with varying name error rates and supporting fields, a logistic regression classifier incorporated via the Bayesian method demonstrated marked improvements over exact-agreement linkage with respect to discriminatory power, match probability estimation, and accuracy, reducing the total number of misclassified record pairs by 21% in test data and up to an average of 93% in simulated datasets. Our results demonstrate the value of incorporating visual, phonetic, and keystroke similarity for logographic name matching, as well as the promise of our Bayesian approach to leverage name-matching within large-scale record linkage.