 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-range Dependency based Multi-Layer Perceptron for Heterogeneous Information Networks
Jul 17, 2023

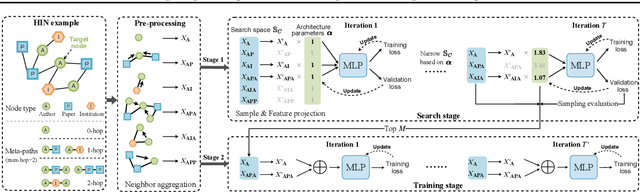
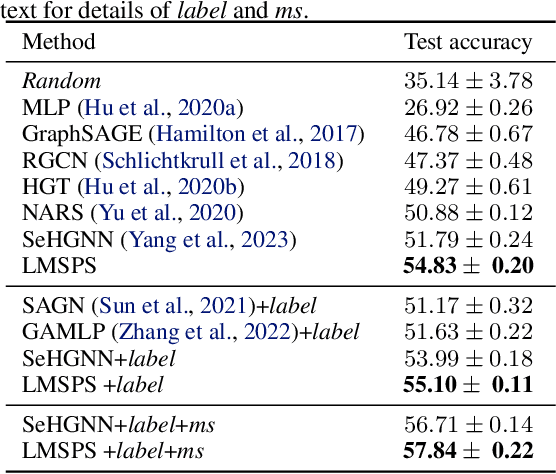
Existing heterogeneous graph neural networks (HGNNs) have achieved great success in utilizing the rich semantic information in heterogeneous information networks (HINs). However, few works have delved into the utilization of long-range dependencies in HINs, which is extremely valuable as many real-world HINs are sparse, and each node has only a few directly connected neighbors. Although some HGNNs can utilize distant neighbors by stacking multiple layers or leveraging long meta-paths, the exponentially increased number of nodes in the receptive field or the number of meta-paths incurs high computation and memory costs. To address these issues, we investigate the importance of different meta-paths and propose Long-range Dependency based Multi-Layer Perceptron (LDMLP). Specifically, to solve the high-cost problem of leveraging long-range dependencies, LDMLP adopts a search stage to discover effective meta-paths automatically, reducing the exponentially increased number of meta-paths to a constant. To avoid the influence of specific modules on search results, LDMLP utilizes a simple architecture with only multi-layer perceptions in the search stage, improving the generalization of searched meta-paths. As a result, the searched meta-paths not only perform well in LDMLP but also enable other HGNNs like HAN and SeHGNN to perform better. Extensive experiments on eight heterogeneous datasets demonstrate that LDMLP achieves state-of-the-art performance while enjoying high efficiency and generalization, especially on sparse HINs.
Propagation with Adaptive Mask then Training for Node Classification on Attributed Networks
Jun 23, 2022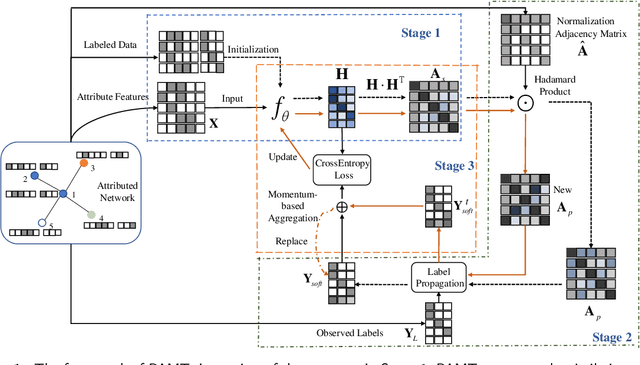
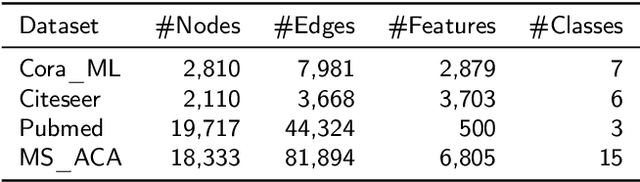
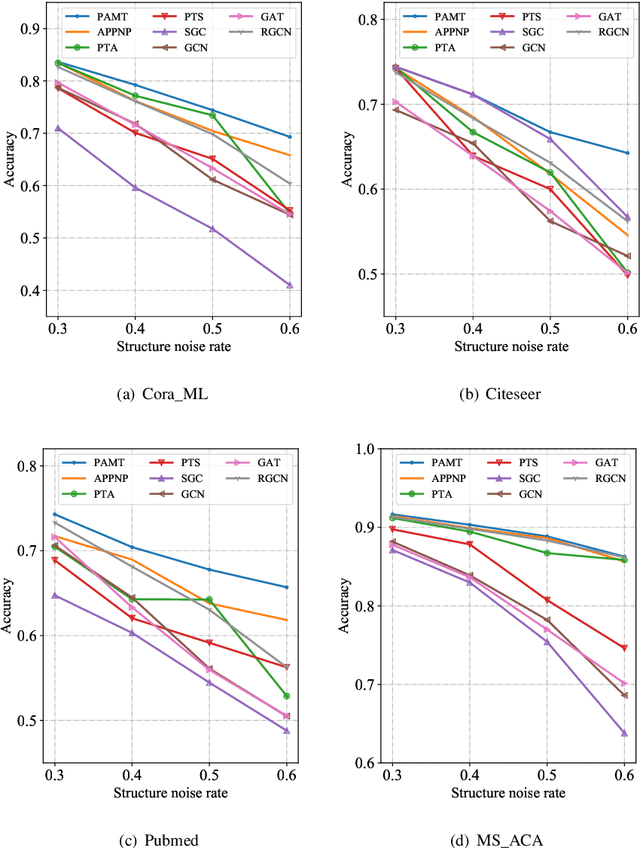
Node classification on attributed networks is a semi-supervised task that is crucial for network analysis. By decoupling two critical operations in Graph Convolutional Networks (GCNs), namely feature transformation and neighborhood aggregation, some recent works of decoupled GCNs could support the information to propagate deeper and achieve advanced performance. However, they follow the traditional structure-aware propagation strategy of GCNs, making it hard to capture the attribute correlation of nodes and sensitive to the structure noise described by edges whose two endpoints belong to different categories. To address these issues, we propose a new method called the itshape Propagation with Adaptive Mask then Training (PAMT). The key idea is to integrate the attribute similarity mask into the structure-aware propagation process. In this way, PAMT could preserve the attribute correlation of adjacent nodes during the propagation and effectively reduce the influence of structure noise. Moreover, we develop an iterative refinement mechanism to update the similarity mask during the training process for improving the training performance. Extensive experiments on four real-world datasets demonstrate the superior performance and robustness of PAMT.