 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWavelet Scattering Transform for Improving Generalization in Low-Resourced Spoken Language Identification
Oct 03, 2023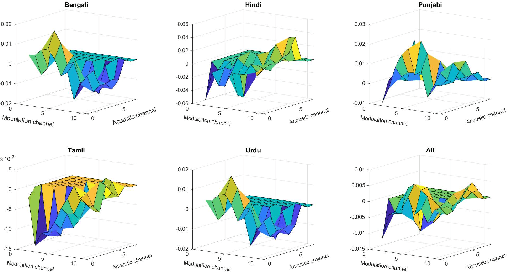

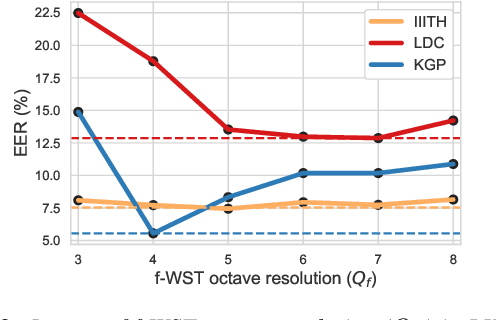

Commonly used features in spoken language identification (LID), such as mel-spectrogram or MFCC, lose high-frequency information due to windowing. The loss further increases for longer temporal contexts. To improve generalization of the low-resourced LID systems, we investigate an alternate feature representation, wavelet scattering transform (WST), that compensates for the shortcomings. To our knowledge, WST is not explored earlier in LID tasks. We first optimize WST features for multiple South Asian LID corpora. We show that LID requires low octave resolution and frequency-scattering is not useful. Further, cross-corpora evaluations show that the optimal WST hyper-parameters depend on both train and test corpora. Hence, we develop fused ECAPA-TDNN based LID systems with different sets of WST hyper-parameters to improve generalization for unknown data. Compared to MFCC, EER is reduced upto 14.05% and 6.40% for same-corpora and blind VoxLingua107 evaluations, respectively.
Modulation spectral features for speech emotion recognition using deep neural networks
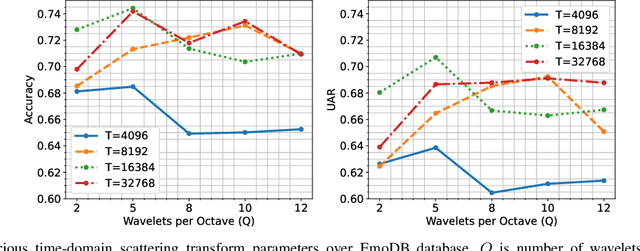
Jan 14, 2023This work explores the use of constant-Q transform based modulation spectral features (CQT-MSF) for speech emotion recognition (SER). The human perception and analysis of sound comprise of two important cognitive parts: early auditory analysis and cortex-based processing. The early auditory analysis considers spectrogram-based representation whereas cortex-based analysis includes extraction of temporal modulations from the spectrogram. This temporal modulation representation of spectrogram is called modulation spectral feature (MSF). As the constant-Q transform (CQT) provides higher resolution at emotion salient low-frequency regions of speech, we find that CQT-based spectrogram, together with its temporal modulations, provides a representation enriched with emotion-specific information. We argue that CQT-MSF when used with a 2-dimensional convolutional network can provide a time-shift invariant and deformation insensitive representation for SER. Our results show that CQT-MSF outperforms standard mel-scale based spectrogram and its modulation features on two popular SER databases, Berlin EmoDB and RAVDESS. We also show that our proposed feature outperforms the shift and deformation invariant scattering transform coefficients, hence, showing the importance of joint hand-crafted and self-learned feature extraction instead of reliance on complete hand-crafted features. Finally, we perform Grad-CAM analysis to visually inspect the contribution of constant-Q modulation features over SER.
* Accepted for publication in Elsevier's Speech Communication Journal
Analysis of constant-Q filterbank based representations for speech emotion recognition
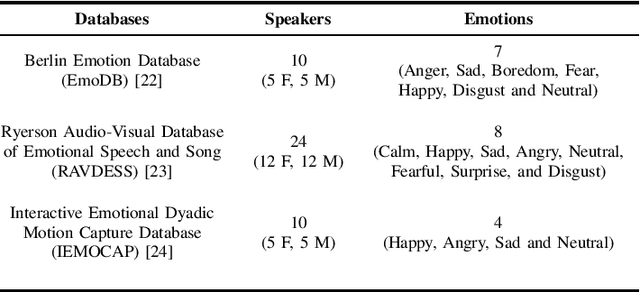
Nov 29, 2022This work analyzes the constant-Q filterbank-based time-frequency representations for speech emotion recognition (SER). Constant-Q filterbank provides non-linear spectro-temporal representation with higher frequency resolution at low frequencies. Our investigation reveals how the increased low-frequency resolution benefits SER. The time-domain comparative analysis between short-term mel-frequency spectral coefficients (MFSCs) and constant-Q filterbank-based features, namely constant-Q transform (CQT) and continuous wavelet transform (CWT), reveals that constant-Q representations provide higher time-invariance at low-frequencies. This provides increased robustness against emotion irrelevant temporal variations in pitch, especially for low-arousal emotions. The corresponding frequency-domain analysis over different emotion classes shows better resolution of pitch harmonics in constant-Q-based time-frequency representations than MFSC. These advantages of constant-Q representations are further consolidated by SER performance in the extensive evaluation of features over four publicly available databases with six advanced deep neural network architectures as the back-end classifiers. Our inferences in this study hint toward the suitability and potentiality of constant-Q features for SER.
* Accepted for publication in Elsevier's Digital Signal Processing Journal
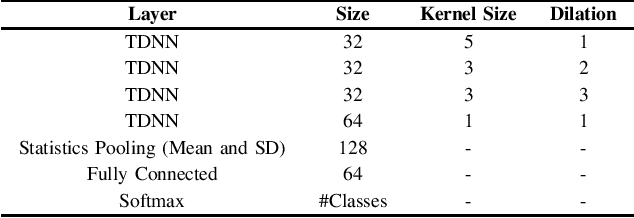
Deep scattering network for speech emotion recognition
May 11, 2021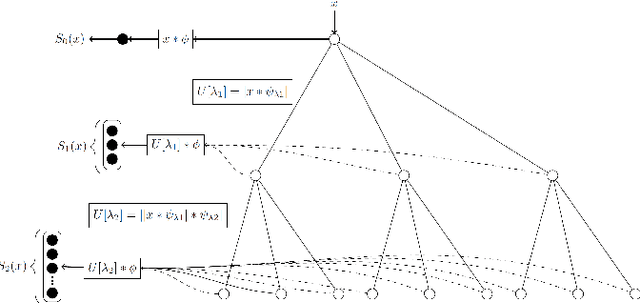

This paper introduces scattering transform for speech emotion recognition (SER). Scattering transform generates feature representations which remain stable to deformations and shifting in time and frequency without much loss of information. In speech, the emotion cues are spread across time and localised in frequency. The time and frequency invariance characteristic of scattering coefficients provides a representation robust against emotion irrelevant variations e.g., different speakers, language, gender etc. while preserving the variations caused by emotion cues. Hence, such a representation captures the emotion information more efficiently from speech. We perform experiments to compare scattering coefficients with standard mel-frequency cepstral coefficients (MFCCs) over different databases. It is observed that frequency scattering performs better than time-domain scattering and MFCCs. We also investigate layer-wise scattering coefficients to analyse the importance of time shift and deformation stable scalogram and modulation spectrum coefficients for SER. We observe that layer-wise coefficients taken independently also perform better than MFCCs.
Non-linear frequency warping using constant-Q transformation for speech emotion recognition
Feb 08, 2021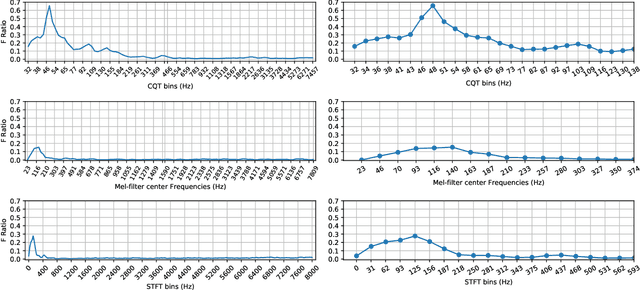


In this work, we explore the constant-Q transform (CQT) for speech emotion recognition (SER). The CQT-based time-frequency analysis provides variable spectro-temporal resolution with higher frequency resolution at lower frequencies. Since lower-frequency regions of speech signal contain more emotion-related information than higher-frequency regions, the increased low-frequency resolution of CQT makes it more promising for SER than standard short-time Fourier transform (STFT). We present a comparative analysis of short-term acoustic features based on STFT and CQT for SER with deep neural network (DNN) as a back-end classifier. We optimize different parameters for both features. The CQT-based features outperform the STFT-based spectral features for SER experiments. Further experiments with cross-corpora evaluation demonstrate that the CQT-based systems provide better generalization with out-of-domain training data.