 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of constant-Q filterbank based representations for speech emotion recognition
Nov 29, 2022This work analyzes the constant-Q filterbank-based time-frequency representations for speech emotion recognition (SER). Constant-Q filterbank provides non-linear spectro-temporal representation with higher frequency resolution at low frequencies. Our investigation reveals how the increased low-frequency resolution benefits SER. The time-domain comparative analysis between short-term mel-frequency spectral coefficients (MFSCs) and constant-Q filterbank-based features, namely constant-Q transform (CQT) and continuous wavelet transform (CWT), reveals that constant-Q representations provide higher time-invariance at low-frequencies. This provides increased robustness against emotion irrelevant temporal variations in pitch, especially for low-arousal emotions. The corresponding frequency-domain analysis over different emotion classes shows better resolution of pitch harmonics in constant-Q-based time-frequency representations than MFSC. These advantages of constant-Q representations are further consolidated by SER performance in the extensive evaluation of features over four publicly available databases with six advanced deep neural network architectures as the back-end classifiers. Our inferences in this study hint toward the suitability and potentiality of constant-Q features for SER.
* Accepted for publication in Elsevier's Digital Signal Processing Journal
Robust Acoustic Domain Identification with its Application to Speaker Diarization
Aug 08, 2022With the rise in multimedia content over the years, more variety is observed in the recording environments of audio. An audio processing system might benefit when it has a module to identify the acoustic domain at its front-end. In this paper, we demonstrate the idea of \emph{acoustic domain identification} (ADI) for \emph{speaker diarization}. For this, we first present a detailed study of the various domains of the third DIHARD challenge highlighting the factors that differentiated them from each other. Our main contribution is to develop a simple and efficient solution for ADI. In the present work, we explore speaker embeddings for this task. Next, we integrate the ADI module with the speaker diarization framework of the DIHARD III challenge. The performance substantially improved over that of the baseline when the thresholds for agglomerative hierarchical clustering were optimized according to the respective domains. We achieved a relative improvement of more than $5\%$ and $8\%$ in DER for core and full conditions, respectively, on Track 1 of the DIHARD III evaluation set.
ABSP System for The Third DIHARD Challenge
Feb 10, 2021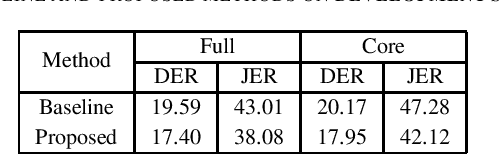
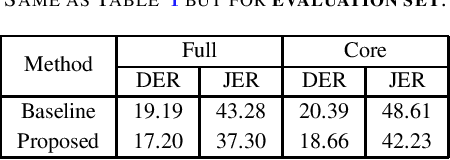
This report describes the speaker diarization system developed by the ABSP Laboratory team for the third DIHARD speech diarization challenge. Our primary contribution is to develop acoustic domain identification (ADI) system for speaker diarization. We investigate speaker embeddings based ADI system. We apply a domain-dependent threshold for agglomerative hierarchical clustering. Besides, we optimize the parameters for PCA-based dimensionality reduction in a domain-dependent way. Our method of integrating domain-based processing schemes in the baseline system of the challenge achieved a relative improvement of $9.63\%$ and $10.64\%$ in DER for core and full conditions, respectively, for Track 1 of the DIHARD III evaluation set.
Domain-Dependent Speaker Diarization for the Third DIHARD Challenge
Jan 25, 2021
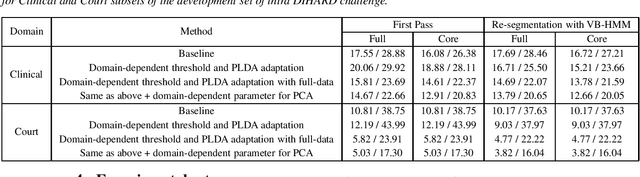

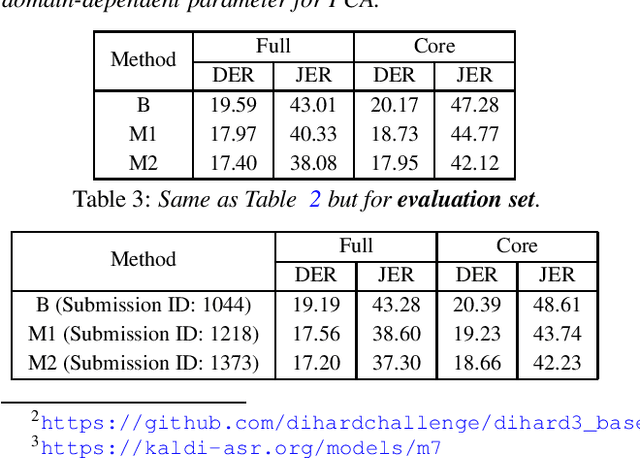
This report presents the system developed by the ABSP Laboratory team for the third DIHARD speech diarization challenge. Our main contribution in this work is to develop a simple and efficient solution for acoustic domain dependent speech diarization. We explore speaker embeddings for \emph{acoustic domain identification} (ADI) task. Our study reveals that i-vector based method achieves considerably better performance than x-vector based approach in the third DIHARD challenge dataset. Next, we integrate the ADI module with the diarization framework. The performance substantially improved over that of the baseline when we optimized the thresholds for agglomerative hierarchical clustering and the parameters for dimensionality reduction during scoring for individual acoustic domains. We achieved a relative improvement of $9.63\%$ and $10.64\%$ in DER for core and full conditions, respectively, for Track 1 of the DIHARD III evaluation set.