 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIITKGP-ABSP Submission to LRE22: Language Recognition in Low-Resource Settings
Jan 15, 2025This is the detailed system description of the IITKGP-ABSP lab's submission to the NIST language recognition evaluation (LRE) 2022. The objective of this LRE (LRE22) is focused on recognizing 14 low-resourced African languages. Even though NIST has provided additional training and development data, we develop our systems with additional constraints of extreme low-resource. Our primary fixed-set submission ensures the usage of only the LRE 22 development data that contains the utterances of 14 target languages. We further restrict our system from using any pre-trained models for feature extraction or classifier fine-tuning. To address the issue of low-resource, our system relies on diverse audio augmentations followed by classifier fusions. Abiding by all the constraints, the proposed methods achieve an EER of 11.43% and cost metric of 0.41 in the LRE22 development set. For users with limited computational resources or limited storage/network capabilities, the proposed system will help achieve efficient LID performance.
Wavelet Scattering Transform for Improving Generalization in Low-Resourced Spoken Language Identification
Oct 03, 2023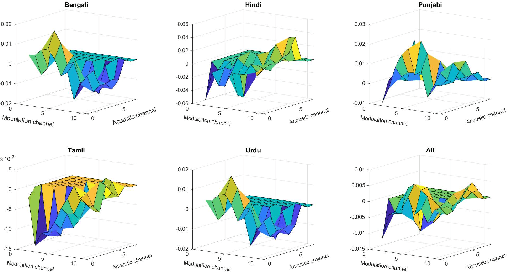

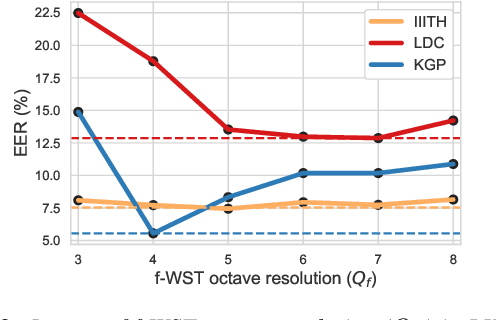

Commonly used features in spoken language identification (LID), such as mel-spectrogram or MFCC, lose high-frequency information due to windowing. The loss further increases for longer temporal contexts. To improve generalization of the low-resourced LID systems, we investigate an alternate feature representation, wavelet scattering transform (WST), that compensates for the shortcomings. To our knowledge, WST is not explored earlier in LID tasks. We first optimize WST features for multiple South Asian LID corpora. We show that LID requires low octave resolution and frequency-scattering is not useful. Further, cross-corpora evaluations show that the optimal WST hyper-parameters depend on both train and test corpora. Hence, we develop fused ECAPA-TDNN based LID systems with different sets of WST hyper-parameters to improve generalization for unknown data. Compared to MFCC, EER is reduced upto 14.05% and 6.40% for same-corpora and blind VoxLingua107 evaluations, respectively.
Cross-Corpora Spoken Language Identification with Domain Diversification and Generalization
Feb 10, 2023



This work addresses the cross-corpora generalization issue for the low-resourced spoken language identification (LID) problem. We have conducted the experiments in the context of Indian LID and identified strikingly poor cross-corpora generalization due to corpora-dependent non-lingual biases. Our contribution to this work is twofold. First, we propose domain diversification, which diversifies the limited training data using different audio data augmentation methods. We then propose the concept of maximally diversity-aware cascaded augmentations and optimize the augmentation fold-factor for effective diversification of the training data. Second, we introduce the idea of domain generalization considering the augmentation methods as pseudo-domains. Towards this, we investigate both domain-invariant and domain-aware approaches. Our LID system is based on the state-of-the-art emphasized channel attention, propagation, and aggregation based time delay neural network (ECAPA-TDNN) architecture. We have conducted extensive experiments with three widely used corpora for Indian LID research. In addition, we conduct a final blind evaluation of our proposed methods on the Indian subset of VoxLingua107 corpus collected in the wild. Our experiments demonstrate that the proposed domain diversification is more promising over commonly used simple augmentation methods. The study also reveals that domain generalization is a more effective solution than domain diversification. We also notice that domain-aware learning performs better for same-corpora LID, whereas domain-invariant learning is more suitable for cross-corpora generalization. Compared to basic ECAPA-TDNN, its proposed domain-invariant extensions improve the cross-corpora EER up to 5.23%. In contrast, the proposed domain-aware extensions also improve performance for same-corpora test scenarios.
An Overview of Indian Spoken Language Recognition from Machine Learning Perspective
Nov 30, 2022Automatic spoken language identification (LID) is a very important research field in the era of multilingual voice-command-based human-computer interaction (HCI). A front-end LID module helps to improve the performance of many speech-based applications in the multilingual scenario. India is a populous country with diverse cultures and languages. The majority of the Indian population needs to use their respective native languages for verbal interaction with machines. Therefore, the development of efficient Indian spoken language recognition systems is useful for adapting smart technologies in every section of Indian society. The field of Indian LID has started gaining momentum in the last two decades, mainly due to the development of several standard multilingual speech corpora for the Indian languages. Even though significant research progress has already been made in this field, to the best of our knowledge, there are not many attempts to analytically review them collectively. In this work, we have conducted one of the very first attempts to present a comprehensive review of the Indian spoken language recognition research field. In-depth analysis has been presented to emphasize the unique challenges of low-resource and mutual influences for developing LID systems in the Indian contexts. Several essential aspects of the Indian LID research, such as the detailed description of the available speech corpora, the major research contributions, including the earlier attempts based on statistical modeling to the recent approaches based on different neural network architectures, and the future research trends are discussed. This review work will help assess the state of the present Indian LID research by any active researcher or any research enthusiasts from related fields.
* Accepted for publication in ACM Transactions on Asian and Low-Resource Language Information Processing
Cross-Corpora Language Recognition: A Preliminary Investigation with Indian Languages
May 12, 2021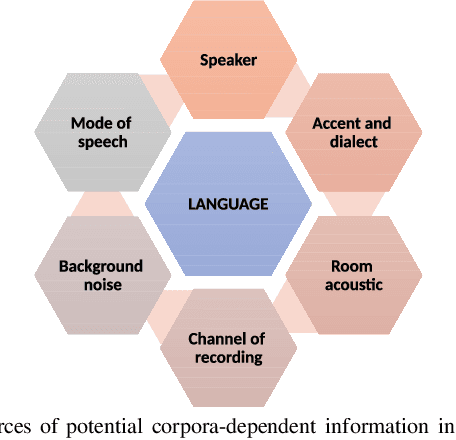
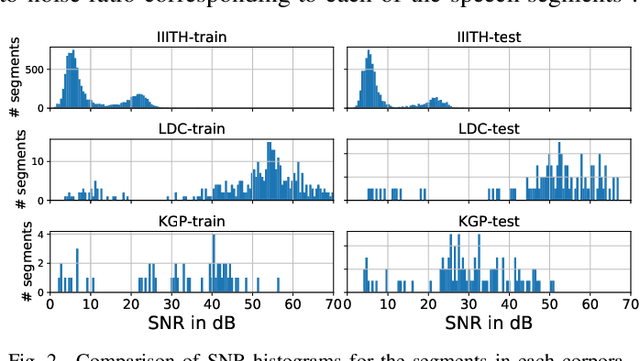
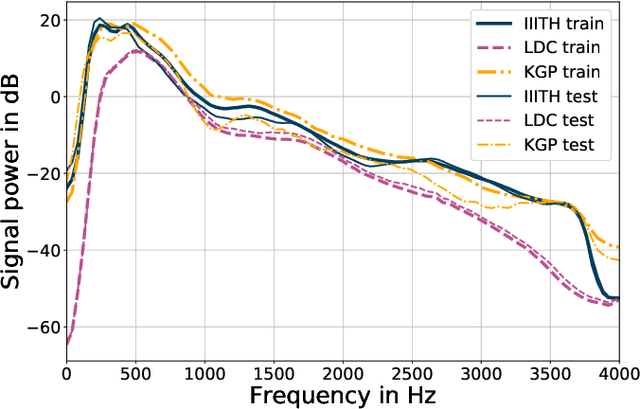
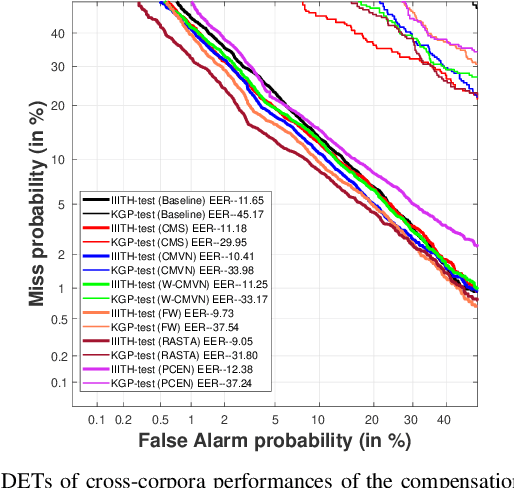
In this paper, we conduct one of the very first studies for cross-corpora performance evaluation in the spoken language identification (LID) problem. Cross-corpora evaluation was not explored much in LID research, especially for the Indian languages. We have selected three Indian spoken language corpora: IIITH-ILSC, LDC South Asian, and IITKGP-MLILSC. For each of the corpus, LID systems are trained on the state-of-the-art time-delay neural network (TDNN) based architecture with MFCC features. We observe that the LID performance degrades drastically for cross-corpora evaluation. For example, the system trained on the IIITH-ILSC corpus shows an average EER of 11.80 % and 43.34 % when evaluated with the same corpora and LDC South Asian corpora, respectively. Our preliminary analysis shows the significant differences among these corpora in terms of mismatch in the long-term average spectrum (LTAS) and signal-to-noise ratio (SNR). Subsequently, we apply different feature level compensation methods to reduce the cross-corpora acoustic mismatch. Our results indicate that these feature normalization schemes can help to achieve promising LID performance on cross-corpora experiments.