 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance of Small Language Model Pretraining on FABRIC: An Empirical Study
Feb 02, 2026Large language models (LLMs) require enormous computing power to pretrain on massive datasets. When limited datasets are available, smaller-sized LLMs are better choice to pretrain (on user-specified datasets) by following the scaling laws of LLMs. Using pretrained models, vector embeddings can be generated for raw data and stored using vector databases to support modern AI applications and semantic search. In this work, we investigate the performance of pretraining techniques for smaller-sized LLMs on an experimental testbed (with commodity GPUs) available to academic users at no charge. We consider data parallelism, intra-operator parallelism, and inter-operator/pipeline parallelism, and their combinations for pretraining. We set up different GPU clusters with homogeneous and heterogeneous GPU hardware. Furthermore, we investigate the impact of network latency on pretraining performance especially when GPUs are geographically distributed. We used GPT-2 medium and large models and pretrained them using open-source packages, namely, Alpa and Ray. We observed that Alpa's execution plans that collectively optimized intra-operator and inter-operator/pipeline parallelism consistently performed the best when GPUs were geographically distributed. This was especially true when the network latencies were in 10's of milliseconds. Based on the insights gained from the experiments, we propose a systematic approach for selecting the appropriate pretraining technique to achieve high training performance/lower execution time as well as to reduce the number of GPUs used.
Observing Health Outcomes Using Remote Sensing Imagery and Geo-Context Guided Visual Transformer
Jan 26, 2026Visual transformers have driven major progress in remote sensing image analysis, particularly in object detection and segmentation. Recent vision-language and multimodal models further extend these capabilities by incorporating auxiliary information, including captions, question and answer pairs, and metadata, which broadens applications beyond conventional computer vision tasks. However, these models are typically optimized for semantic alignment between visual and textual content rather than geospatial understanding, and therefore are not suited for representing or reasoning with structured geospatial layers. In this study, we propose a novel model that enhances remote sensing imagery processing with guidance from auxiliary geospatial information. Our approach introduces a geospatial embedding mechanism that transforms diverse geospatial data into embedding patches that are spatially aligned with image patches. To facilitate cross-modal interaction, we design a guided attention module that dynamically integrates multimodal information by computing attention weights based on correlations with auxiliary data, thereby directing the model toward the most relevant regions. In addition, the module assigns distinct roles to individual attention heads, allowing the model to capture complementary aspects of the guidance information and improving the interpretability of its predictions. Experimental results demonstrate that the proposed framework outperforms existing pretrained geospatial foundation models in predicting disease prevalence, highlighting its effectiveness in multimodal geospatial understanding.
From Keywords to Clusters: AI-Driven Analysis of YouTube Comments to Reveal Election Issue Salience in 2024
Oct 09, 2025This paper aims to explore two competing data science methodologies to attempt answering the question, "Which issues contributed most to voters' choice in the 2024 presidential election?" The methodologies involve novel empirical evidence driven by artificial intelligence (AI) techniques. By using two distinct methods based on natural language processing and clustering analysis to mine over eight thousand user comments on election-related YouTube videos from one right leaning journal, Wall Street Journal, and one left leaning journal, New York Times, during pre-election week, we quantify the frequency of selected issue areas among user comments to infer which issues were most salient to potential voters in the seven days preceding the November 5th election. Empirically, we primarily demonstrate that immigration and democracy were the most frequently and consistently invoked issues in user comments on the analyzed YouTube videos, followed by the issue of identity politics, while inflation was significantly less frequently referenced. These results corroborate certain findings of post-election surveys but also refute the supposed importance of inflation as an election issue. This indicates that variations on opinion mining, with their analysis of raw user data online, can be more revealing than polling and surveys for analyzing election outcomes.
Evaluating the Performance of AI Text Detectors, Few-Shot and Chain-of-Thought Prompting Using DeepSeek Generated Text
Jul 23, 2025Large language models (LLMs) have rapidly transformed the creation of written materials. LLMs have led to questions about writing integrity, thereby driving the creation of artificial intelligence (AI) detection technologies. Adversarial attacks, such as standard and humanized paraphrasing, inhibit detectors' ability to detect machine-generated text. Previous studies have mainly focused on ChatGPT and other well-known LLMs and have shown varying accuracy across detectors. However, there is a clear gap in the literature about DeepSeek, a recently published LLM. Therefore, in this work, we investigate whether six generally accessible AI detection tools -- AI Text Classifier, Content Detector AI, Copyleaks, QuillBot, GPT-2, and GPTZero -- can consistently recognize text generated by DeepSeek. The detectors were exposed to the aforementioned adversarial attacks. We also considered DeepSeek as a detector by performing few-shot prompting and chain-of-thought reasoning (CoT) for classifying AI and human-written text. We collected 49 human-authored question-answer pairs from before the LLM era and generated matching responses using DeepSeek-v3, producing 49 AI-generated samples. Then, we applied adversarial techniques such as paraphrasing and humanizing to add 196 more samples. These were used to challenge detector robustness and assess accuracy impact. While QuillBot and Copyleaks showed near-perfect performance on original and paraphrased DeepSeek text, others -- particularly AI Text Classifier and GPT-2 -- showed inconsistent results. The most effective attack was humanization, reducing accuracy to 71% for Copyleaks, 58% for QuillBot, and 52% for GPTZero. Few-shot and CoT prompting showed high accuracy, with the best five-shot result misclassifying only one of 49 samples (AI recall 96%, human recall 100%).
HARPT: A Corpus for Analyzing Consumers' Trust and Privacy Concerns in Mobile Health Apps
Jun 24, 2025We present HARPT, a large-scale annotated corpus of mobile health app store reviews aimed at advancing research in user privacy and trust. The dataset comprises over 480,000 user reviews labeled into seven categories that capture critical aspects of trust in applications, trust in providers and privacy concerns. Creating HARPT required addressing multiple complexities, such as defining a nuanced label schema, isolating relevant content from large volumes of noisy data, and designing an annotation strategy that balanced scalability with accuracy. This strategy integrated rule-based filtering, iterative manual labeling with review, targeted data augmentation, and weak supervision using transformer-based classifiers to accelerate coverage. In parallel, a carefully curated subset of 7,000 reviews was manually annotated to support model development and evaluation. We benchmark a broad range of classification models, demonstrating that strong performance is achievable and providing a baseline for future research. HARPT is released as a public resource to support work in health informatics, cybersecurity, and natural language processing.
Predicting Survivability of Cancer Patients with Metastatic Patterns Using Explainable AI
Apr 07, 2025Cancer remains a leading global health challenge and a major cause of mortality. This study leverages machine learning (ML) to predict the survivability of cancer patients with metastatic patterns using the comprehensive MSK-MET dataset, which includes genomic and clinical data from 25,775 patients across 27 cancer types. We evaluated five ML models-XGBoost, Na\"ive Bayes, Decision Tree, Logistic Regression, and Random Fores using hyperparameter tuning and grid search. XGBoost emerged as the best performer with an area under the curve (AUC) of 0.82. To enhance model interpretability, SHapley Additive exPlanations (SHAP) were applied, revealing key predictors such as metastatic site count, tumor mutation burden, fraction of genome altered, and organ-specific metastases. Further survival analysis using Kaplan-Meier curves, Cox Proportional Hazards models, and XGBoost Survival Analysis identified significant predictors of patient outcomes, offering actionable insights for clinicians. These findings could aid in personalized prognosis and treatment planning, ultimately improving patient care.
A Scalable Tool For Analyzing Genomic Variants Of Humans Using Knowledge Graphs and Machine Learning
Jul 30, 2024



The integration of knowledge graphs and graph machine learning (GML) in genomic data analysis offers several opportunities for understanding complex genetic relationships, especially at the RNA level. We present a comprehensive approach for leveraging these technologies to analyze genomic variants, specifically in the context of RNA sequencing (RNA-seq) data from COVID-19 patient samples. The proposed method involves extracting variant-level genetic information, annotating the data with additional metadata using SnpEff, and converting the enriched Variant Call Format (VCF) files into Resource Description Framework (RDF) triples. The resulting knowledge graph is further enhanced with patient metadata and stored in a graph database, facilitating efficient querying and indexing. We utilize the Deep Graph Library (DGL) to perform graph machine learning tasks, including node classification with GraphSAGE and Graph Convolutional Networks (GCNs). Our approach demonstrates significant utility using our proposed tool, VariantKG, in three key scenarios: enriching graphs with new VCF data, creating subgraphs based on user-defined features, and conducting graph machine learning for node classification.
Seventeenth-Century Spanish American Notary Records for Fine-Tuning Spanish Large Language Models
Jun 09, 2024Large language models have gained tremendous popularity in domains such as e-commerce, finance, healthcare, and education. Fine-tuning is a common approach to customize an LLM on a domain-specific dataset for a desired downstream task. In this paper, we present a valuable resource for fine-tuning LLMs developed for the Spanish language to perform a variety of tasks such as classification, masked language modeling, clustering, and others. Our resource is a collection of handwritten notary records from the seventeenth century obtained from the National Archives of Argentina. This collection contains a combination of original images and transcribed text (and metadata) of 160+ pages that were handwritten by two notaries, namely, Estenban Agreda de Vergara and Nicolas de Valdivia y Brisuela nearly 400 years ago. Through empirical evaluation, we demonstrate that our collection can be used to fine-tune Spanish LLMs for tasks such as classification and masked language modeling, and can outperform pre-trained Spanish models and ChatGPT-3.5/ChatGPT-4o. Our resource will be an invaluable resource for historical text analysis and is publicly available on GitHub.
Scalable Knowledge Graph Construction and Inference on Human Genome Variants
Dec 07, 2023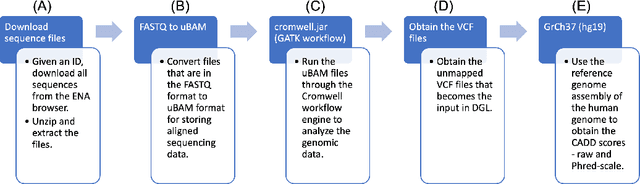



Real-world knowledge can be represented as a graph consisting of entities and relationships between the entities. The need for efficient and scalable solutions arises when dealing with vast genomic data, like RNA-sequencing. Knowledge graphs offer a powerful approach for various tasks in such large-scale genomic data, such as analysis and inference. In this work, variant-level information extracted from the RNA-sequences of vaccine-na\"ive COVID-19 patients have been represented as a unified, large knowledge graph. Variant call format (VCF) files containing the variant-level information were annotated to include further information for each variant. The data records in the annotated files were then converted to Resource Description Framework (RDF) triples. Each VCF file obtained had an associated CADD scores file that contained the raw and Phred-scaled scores for each variant. An ontology was defined for the VCF and CADD scores files. Using this ontology and the extracted information, a large, scalable knowledge graph was created. Available graph storage was then leveraged to query and create datasets for further downstream tasks. We also present a case study using the knowledge graph and perform a classification task using graph machine learning. We also draw comparisons between different Graph Neural Networks (GNNs) for the case study.
Zero Shot Learning for Predicting Energy Usage of Buildings in Sustainable Design
Feb 10, 2022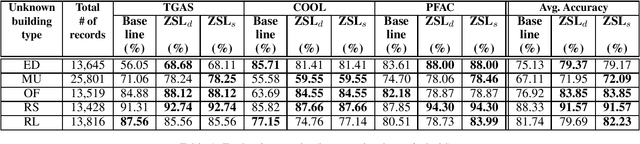
The 2030 Challenge is aimed at making all new buildings and major renovations carbon neutral by 2030. One of the potential solutions to meet this challenge is through innovative sustainable design strategies. For developing such strategies it is important to understand how the various building factors contribute to energy usage of a building, right at design time. The growth of artificial intelligence (AI) in recent years provides an unprecedented opportunity to advance sustainable design by learning complex relationships between building factors from available data. However, rich training datasets are needed for AI-based solutions to achieve good prediction accuracy. Unfortunately, obtaining training datasets are time consuming and expensive in many real-world applications. Motivated by these reasons, we address the problem of accurately predicting the energy usage of new or unknown building types, i.e., those building types that do not have any training data. We propose a novel approach based on zero-shot learning (ZSL) to solve this problem. Our approach uses side information from building energy modeling experts to predict the closest building types for a given new/unknown building type. We then obtain the predicted energy usage for the k-closest building types using the models learned during training and combine the predicted values using a weighted averaging function. We evaluated our approach on a dataset containing five building types generated using BuildSimHub, a popular platform for building energy modeling. Our approach achieved better average accuracy than a regression model (based on XGBoost) trained on the entire dataset of known building types.