 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Scalable Tool For Analyzing Genomic Variants Of Humans Using Knowledge Graphs and Machine Learning
Jul 30, 2024



The integration of knowledge graphs and graph machine learning (GML) in genomic data analysis offers several opportunities for understanding complex genetic relationships, especially at the RNA level. We present a comprehensive approach for leveraging these technologies to analyze genomic variants, specifically in the context of RNA sequencing (RNA-seq) data from COVID-19 patient samples. The proposed method involves extracting variant-level genetic information, annotating the data with additional metadata using SnpEff, and converting the enriched Variant Call Format (VCF) files into Resource Description Framework (RDF) triples. The resulting knowledge graph is further enhanced with patient metadata and stored in a graph database, facilitating efficient querying and indexing. We utilize the Deep Graph Library (DGL) to perform graph machine learning tasks, including node classification with GraphSAGE and Graph Convolutional Networks (GCNs). Our approach demonstrates significant utility using our proposed tool, VariantKG, in three key scenarios: enriching graphs with new VCF data, creating subgraphs based on user-defined features, and conducting graph machine learning for node classification.
Scalable Knowledge Graph Construction and Inference on Human Genome Variants
Dec 07, 2023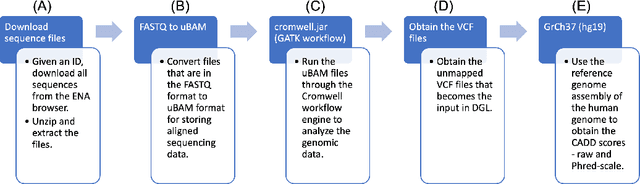



Real-world knowledge can be represented as a graph consisting of entities and relationships between the entities. The need for efficient and scalable solutions arises when dealing with vast genomic data, like RNA-sequencing. Knowledge graphs offer a powerful approach for various tasks in such large-scale genomic data, such as analysis and inference. In this work, variant-level information extracted from the RNA-sequences of vaccine-na\"ive COVID-19 patients have been represented as a unified, large knowledge graph. Variant call format (VCF) files containing the variant-level information were annotated to include further information for each variant. The data records in the annotated files were then converted to Resource Description Framework (RDF) triples. Each VCF file obtained had an associated CADD scores file that contained the raw and Phred-scaled scores for each variant. An ontology was defined for the VCF and CADD scores files. Using this ontology and the extracted information, a large, scalable knowledge graph was created. Available graph storage was then leveraged to query and create datasets for further downstream tasks. We also present a case study using the knowledge graph and perform a classification task using graph machine learning. We also draw comparisons between different Graph Neural Networks (GNNs) for the case study.