 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePost-Decision State-Based Online Learning for Delay-Energy-Aware Flow Allocation in Wireless Systems
Jan 06, 2026We develop a structure-aware reinforcement learning (RL) approach for delay- and energy-aware flow allocation in 5G User Plane Functions (UPFs). We consider a dynamic system with $K$ heterogeneous UPFs of varying capacities that handle stochastic arrivals of $M$ flow types, each with distinct rate requirements. We model the system as a Markov decision process (MDP) to capture the stochastic nature of flow arrivals and departures (possibly unknown), as well as the impact of flow allocation in the system. To solve this problem, we propose a post-decision state (PDS) based value iteration algorithm that exploits the underlying structure of the MDP. By separating action-controlled dynamics from exogenous factors, PDS enables faster convergence and efficient adaptive flow allocation, even in the absence of statistical knowledge about exogenous variables. Simulation results demonstrate that the proposed method converges faster and achieves lower long-term cost than standard Q-learning, highlighting the effectiveness of PDS-based RL for resource allocation in wireless networks.
Joint User and Beam Selection in Millimeter Wave Networks
Feb 12, 2024


We study the problem of selecting a user equipment (UE) and a beam for each access point (AP) for concurrent transmissions in a millimeter wave (mmWave) network, such that the sum of weighted rates of UEs is maximized. We prove that this problem is NP-complete. We propose two algorithms -- Markov Chain Monte Carlo (MCMC) based and local interaction game (LIG) based UE and beam selection -- and prove that both of them asymptotically achieve the optimal solution. Also, we propose two fast greedy algorithms -- NGUB1 and NGUB2 -- for UE and beam selection. Through extensive simulations, we show that our proposed greedy algorithms outperform the most relevant algorithms proposed in prior work and perform close to the asymptotically optimal algorithms.
Efficient Coding Approach Towards Non-Linear Spectro-Temporal Receptive Fields
Oct 21, 2021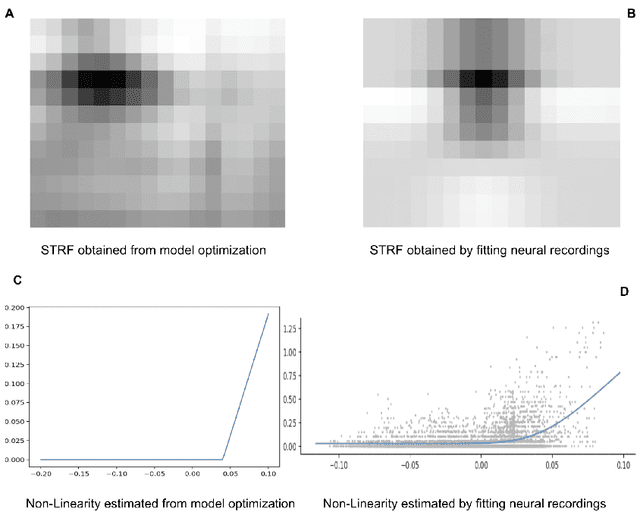
Linear Non-Linear(LN) models are widely used to characterize the receptive fields of early-stage auditory processing. We apply the principle of efficient coding to the LN model of Spectro-Temporal Receptive Fields(STRFs) of the neurons in primary auditory cortex. The Efficient Coding Principle has been previously used to understand early visual receptive fields and linear STRFs in auditory processing. Efficient coding is realized by jointly optimizing the mutual information between stimuli and neural responses subjected to the metabolic cost of firing spikes. We compare the predictions of the efficient coding principle with the physiological observations, which match qualitatively under realistic conditions of noise in stimuli and the spike generation process.
Online Reinforcement Learning of Optimal Threshold Policies for Markov Decision Processes
Dec 21, 2019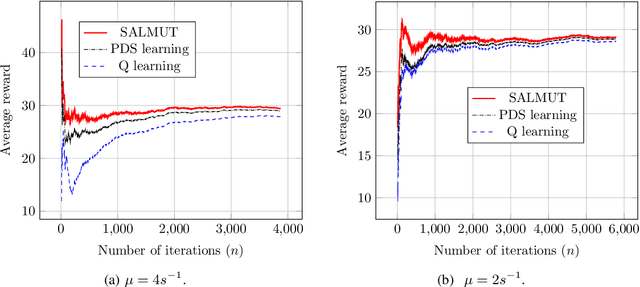
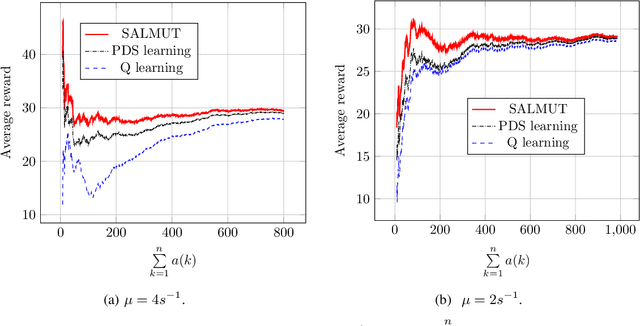

Markov Decision Process (MDP) problems can be solved using Dynamic Programming (DP) methods which suffer from the curse of dimensionality and the curse of modeling. To overcome these issues, Reinforcement Learning (RL) methods are adopted in practice. In this paper, we aim to obtain the optimal admission control policy in a system where different classes of customers are present. Using DP techniques, we prove that it is optimal to admit the $i$ th class of customers only upto a threshold $\tau(i)$ which is a non-increasing function of $i$. Contrary to traditional RL algorithms which do not take into account the structural properties of the optimal policy while learning, we propose a structure-aware learning algorithm which exploits the threshold structure of the optimal policy. We prove the asymptotic convergence of the proposed algorithm to the optimal policy. Due to the reduction in the policy space, the structure-aware learning algorithm provides remarkable improvements in storage and computational complexities over classical RL algorithms. Simulation results also establish the gain in the convergence rate of the proposed algorithm over other RL algorithms. The techniques presented in the paper can be applied to any general MDP problem covering various applications such as inventory management, financial planning and communication networking.
MIST: A Novel Training Strategy for Low-latencyScalable Neural Net Decoders
May 22, 2019
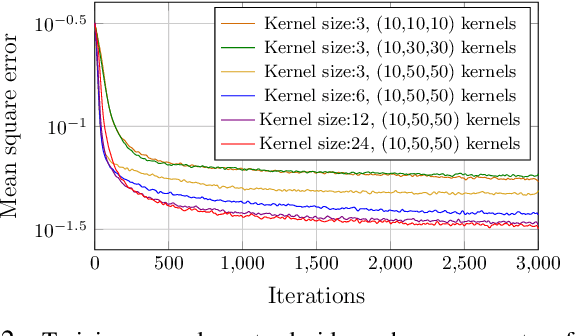


In this paper, we propose a low latency, robust and scalable neural net based decoder for convolutional and low-density parity-check (LPDC) coding schemes. The proposed decoders are demonstrated to have bit error rate (BER) and block error rate (BLER) performances at par with the state-of-the-art neural net based decoders while achieving more than 8 times higher decoding speed. The enhanced decoding speed is due to the use of convolutional neural network (CNN) as opposed to recurrent neural network (RNN) used in the best known neural net based decoders. This contradicts existing doctrine that only RNN based decoders can provide a performance close to the optimal ones. The key ingredient to our approach is a novel Mixed-SNR Independent Samples based Training (MIST), which allows for training of CNN with only 1\% of possible datawords, even for block length as high as 1000. The proposed decoder is robust as, once trained, the same decoder can be used for a wide range of SNR values. Finally, in the presence of channel outages, the proposed decoders outperform the best known decoders, {\it viz.} unquantized Viterbi decoder for convolutional code, and belief propagation for LDPC. This gives the CNN decoder a significant advantage in 5G millimeter wave systems, where channel outages are prevalent.
KLUCB Approach to Copeland Bandits
Feb 07, 2019Multi-armed bandit(MAB) problem is a reinforcement learning framework where an agent tries to maximise her profit by proper selection of actions through absolute feedback for each action. The dueling bandits problem is a variation of MAB problem in which an agent chooses a pair of actions and receives relative feedback for the chosen action pair. The dueling bandits problem is well suited for modelling a setting in which it is not possible to provide quantitative feedback for each action, but qualitative feedback for each action is preferred as in the case of human feedback. The dueling bandits have been successfully applied in applications such as online rank elicitation, information retrieval, search engine improvement and clinical online recommendation. We propose a new method called Sup-KLUCB for K-armed dueling bandit problem specifically Copeland bandit problem by converting it into a standard MAB problem. Instead of using MAB algorithm independently for each action in a pair as in Sparring and in Self-Sparring algorithms, we combine a pair of action and use it as one action. Previous UCB algorithms such as Relative Upper Confidence Bound(RUCB) can be applied only in case of Condorcet dueling bandits, whereas this algorithm applies to general Copeland dueling bandits, including Condorcet dueling bandits as a special case. Our empirical results outperform state of the art Double Thompson Sampling(DTS) in case of Copeland dueling bandits.
A Structure-aware Online Learning Algorithm for Markov Decision Processes
Nov 28, 2018


To overcome the curse of dimensionality and curse of modeling in Dynamic Programming (DP) methods for solving classical Markov Decision Process (MDP) problems, Reinforcement Learning (RL) algorithms are popular. In this paper, we consider an infinite-horizon average reward MDP problem and prove the optimality of the threshold policy under certain conditions. Traditional RL techniques do not exploit the threshold nature of optimal policy while learning. In this paper, we propose a new RL algorithm which utilizes the known threshold structure of the optimal policy while learning by reducing the feasible policy space. We establish that the proposed algorithm converges to the optimal policy. It provides a significant improvement in convergence speed and computational and storage complexity over traditional RL algorithms. The proposed technique can be applied to a wide variety of optimization problems that include energy efficient data transmission and management of queues. We exhibit the improvement in convergence speed of the proposed algorithm over other RL algorithms through simulations.