 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning for Low-Latency, Quantum-Ready RF Sensing
Apr 27, 2024Recent work has shown the promise of applying deep learning to enhance software processing of radio frequency (RF) signals. In parallel, hardware developments with quantum RF sensors based on Rydberg atoms are breaking longstanding barriers in frequency range, resolution, and sensitivity. In this paper, we describe our implementations of quantum-ready machine learning approaches for RF signal classification. Our primary objective is latency: while deep learning offers a more powerful computational paradigm, it also traditionally incurs latency overheads that hinder wider scale deployment. Our work spans three axes. (1) A novel continuous wavelet transform (CWT) based recurrent neural network (RNN) architecture that enables flexible online classification of RF signals on-the-fly with reduced sampling time. (2) Low-latency inference techniques for both GPU and CPU that span over 100x reductions in inference time, enabling real-time operation with sub-millisecond inference. (3) Quantum-readiness validated through application of our models to physics-based simulation of Rydberg atom QRF sensors. Altogether, our work bridges towards next-generation RF sensors that use quantum technology to surpass previous physical limits, paired with latency-optimized AI/ML software that is suitable for real-time deployment.
Training Quantum Boltzmann Machines with Coresets
Jul 26, 2023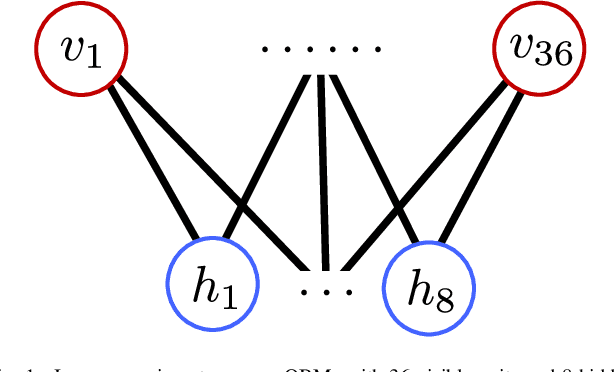
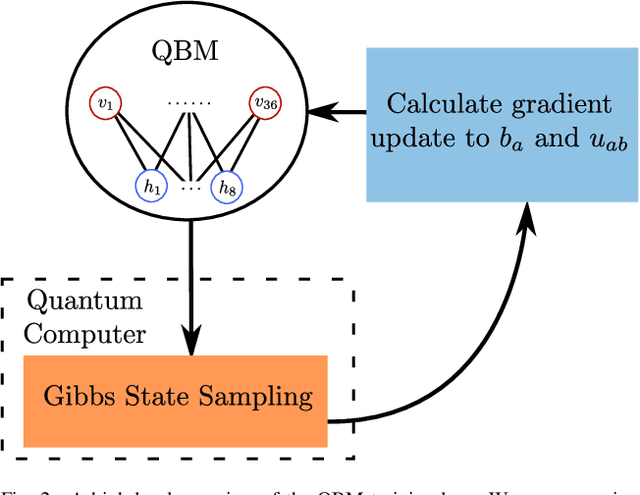
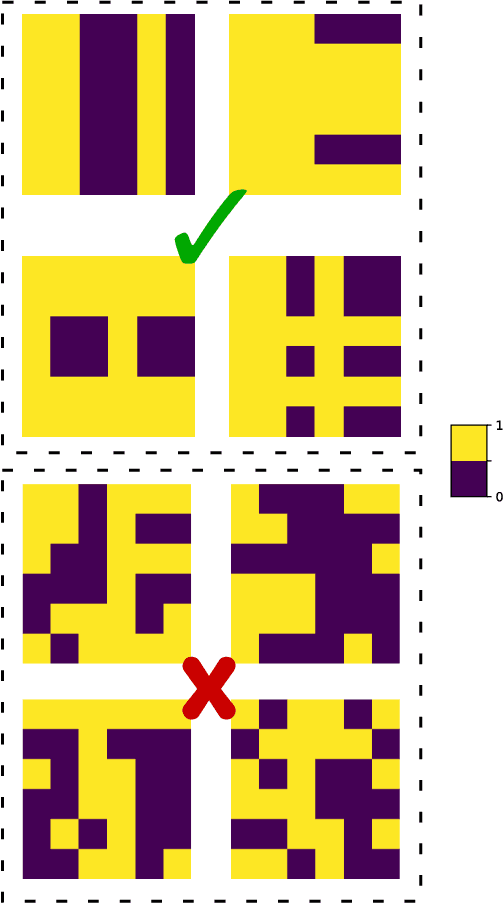
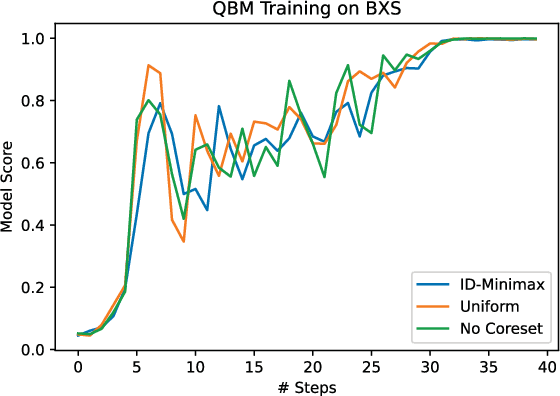
Recent work has proposed and explored using coreset techniques for quantum algorithms that operate on classical data sets to accelerate the applicability of these algorithms on near-term quantum devices. We apply these ideas to Quantum Boltzmann Machines (QBM) where gradient-based steps which require Gibbs state sampling are the main computational bottleneck during training. By using a coreset in place of the full data set, we try to minimize the number of steps needed and accelerate the overall training time. In a regime where computational time on quantum computers is a precious resource, we propose this might lead to substantial practical savings. We evaluate this approach on 6x6 binary images from an augmented bars and stripes data set using a QBM with 36 visible units and 8 hidden units. Using an Inception score inspired metric, we compare QBM training times with and without using coresets.
Coreset Clustering on Small Quantum Computers
Apr 30, 2020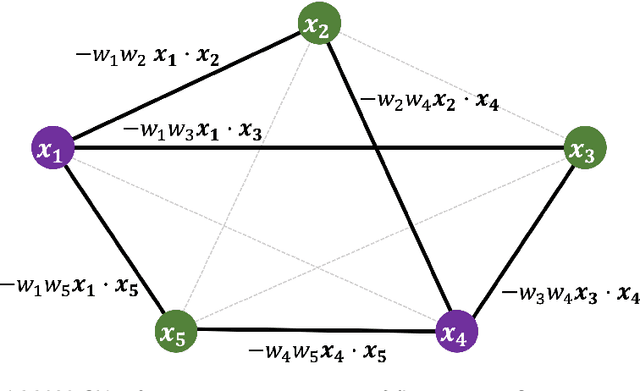
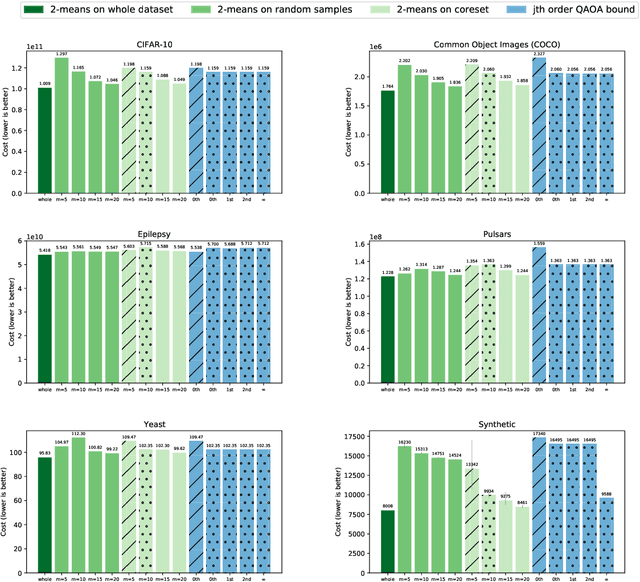
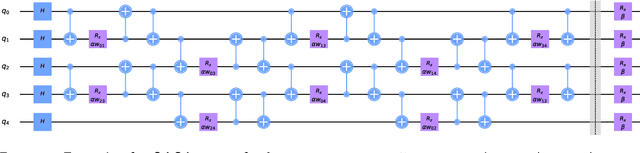
Many quantum algorithms for machine learning require access to classical data in superposition. However, for many natural data sets and algorithms, the overhead required to load the data set in superposition can erase any potential quantum speedup over classical algorithms. Recent work by Harrow introduces a new paradigm in hybrid quantum-classical computing to address this issue, relying on coresets to minimize the data loading overhead of quantum algorithms. We investigate using this paradigm to perform $k$-means clustering on near-term quantum computers, by casting it as a QAOA optimization instance over a small coreset. We compare the performance of this approach to classical $k$-means clustering both numerically and experimentally on IBM Q hardware. We are able to find data sets where coresets work well relative to random sampling and where QAOA could potentially outperform standard $k$-means on a coreset. However, finding data sets where both coresets and QAOA work well--which is necessary for a quantum advantage over $k$-means on the entire data set--appears to be challenging.
Optimized Compilation of Aggregated Instructions for Realistic Quantum Computers
Feb 17, 2019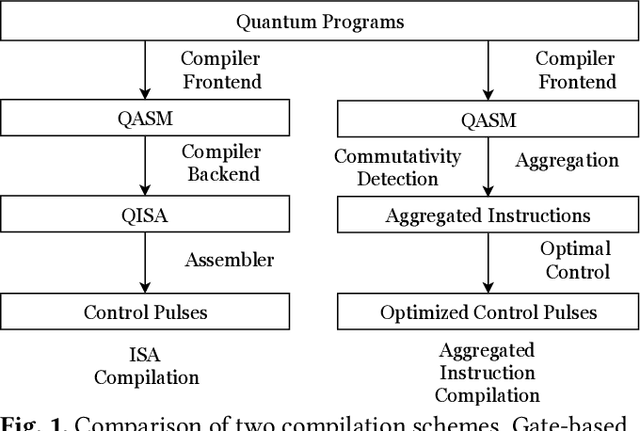
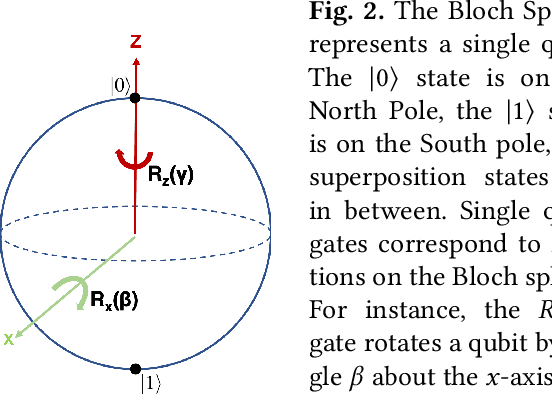
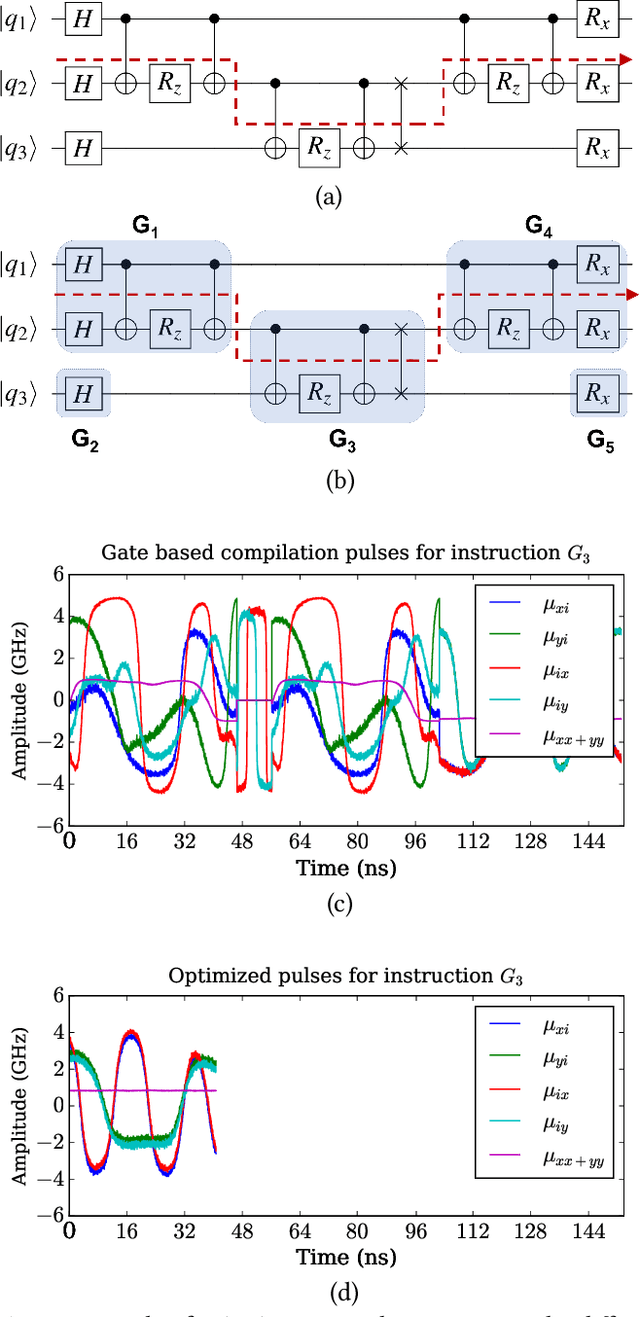
Recent developments in engineering and algorithms have made real-world applications in quantum computing possible in the near future. Existing quantum programming languages and compilers use a quantum assembly language composed of 1- and 2-qubit (quantum bit) gates. Quantum compiler frameworks translate this quantum assembly to electric signals (called control pulses) that implement the specified computation on specific physical devices. However, there is a mismatch between the operations defined by the 1- and 2-qubit logical ISA and their underlying physical implementation, so the current practice of directly translating logical instructions into control pulses results in inefficient, high-latency programs. To address this inefficiency, we propose a universal quantum compilation methodology that aggregates multiple logical operations into larger units that manipulate up to 10 qubits at a time. Our methodology then optimizes these aggregates by (1) finding commutative intermediate operations that result in more efficient schedules and (2) creating custom control pulses optimized for the aggregate (instead of individual 1- and 2-qubit operations). Compared to the standard gate-based compilation, the proposed approach realizes a deeper vertical integration of high-level quantum software and low-level, physical quantum hardware. We evaluate our approach on important near-term quantum applications on simulations of superconducting quantum architectures. Our proposed approach provides a mean speedup of $5\times$, with a maximum of $10\times$. Because latency directly affects the feasibility of quantum computation, our results not only improve performance but also have the potential to enable quantum computation sooner than otherwise possible.