 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Activity Recognition on a Large Scale in Short Videos - Moments in Time Dataset
Sep 13, 2018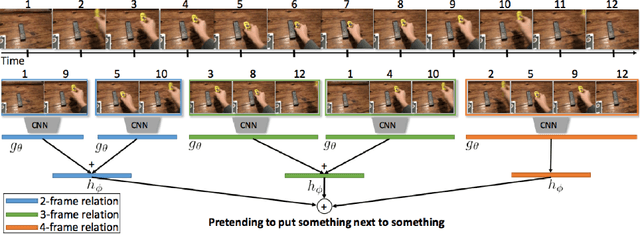

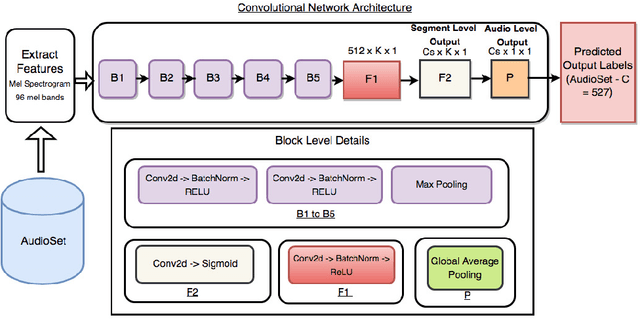
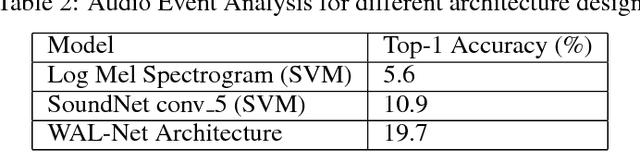
Moments capture a huge part of our lives. Accurate recognition of these moments is challenging due to the diverse and complex interpretation of the moments. Action recognition refers to the act of classifying the desired action/activity present in a given video. In this work, we perform experiments on Moments in Time dataset to recognize accurately activities occurring in 3 second clips. We use state of the art techniques for visual, auditory and spatio temporal localization and develop method to accurately classify the activity in the Moments in Time dataset. Our novel approach of using Visual Based Textual features and fusion techniques performs well providing an overall 89.23 % Top - 5 accuracy on the 20 classes - a significant improvement over the Baseline TRN model.