 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting to Delays and Data in Adversarial Multi-Armed Bandits
Oct 12, 2020We consider the adversarial multi-armed bandit problem under delayed feedback. We analyze variants of the Exp3 algorithm that tune their step-size using only information (about the losses and delays) available at the time of the decisions, and obtain regret guarantees that adapt to the observed (rather than the worst-case) sequences of delays and/or losses. First, through a remarkably simple proof technique, we show that with proper tuning of the step size, the algorithm achieves an optimal (up to logarithmic factors) regret of order $\sqrt{\log(K)(TK + D)}$ both in expectation and in high probability, where $K$ is the number of arms, $T$ is the time horizon, and $D$ is the cumulative delay. The high-probability version of the bound, which is the first high-probability delay-adaptive bound in the literature, crucially depends on the use of implicit exploration in estimating the losses. Then, following Zimmert and Seldin [2019], we extend these results so that the algorithm can "skip" rounds with large delays, resulting in regret bounds of order $\sqrt{TK\log(K)} + |R| + \sqrt{D_{\bar{R}}\log(K)}$, where $R$ is an arbitrary set of rounds (which are skipped) and $D_{\bar{R}}$ is the cumulative delay of the feedback for other rounds. Finally, we present another, data-adaptive (AdaGrad-style) version of the algorithm for which the regret adapts to the observed (delayed) losses instead of only adapting to the cumulative delay (this algorithm requires an a priori upper bound on the maximum delay, or the advance knowledge of the delay for each decision when it is made). The resulting bound can be orders of magnitude smaller on benign problems, and it can be shown that the delay only affects the regret through the loss of the best arm.
Provably Efficient Adaptive Approximate Policy Iteration
Mar 15, 2020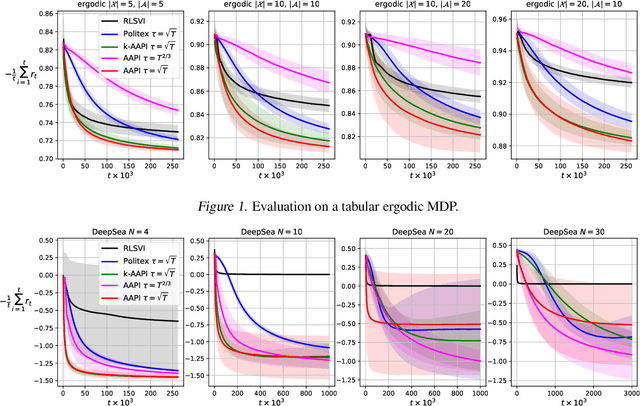
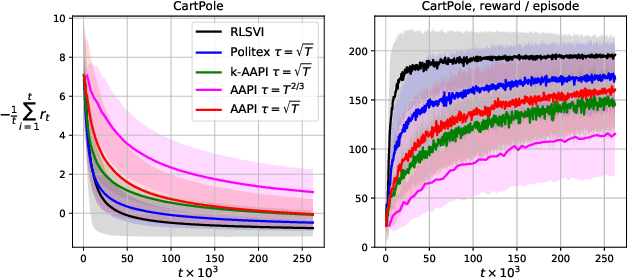
Model-free reinforcement learning algorithms combined with value function approximation have recently achieved impressive performance in a variety of application domains, including games and robotics. However, the theoretical understanding of such algorithms is limited, and existing results are largely focused on episodic or discounted Markov decision processes (MDPs). In this work, we present adaptive approximate policy iteration (AAPI), a learning scheme which enjoys a O(T^{2/3}) regret bound for undiscounted, continuing learning in uniformly ergodic MDPs. This is an improvement over the best existing bound of O(T^{3/4}) for the average-reward case with function approximation. Our algorithm and analysis rely on adversarial online learning techniques, where value functions are treated as losses. The main technical novelty is the use of a data-dependent adaptive learning rate coupled with a so-called optimistic prediction of upcoming losses. In addition to theoretical guarantees, we demonstrate the advantages of our approach empirically on several environments.
A Modular Analysis of Adaptive (Non-)Convex Optimization: Optimism, Composite Objectives, and Variational Bounds
Sep 08, 2017
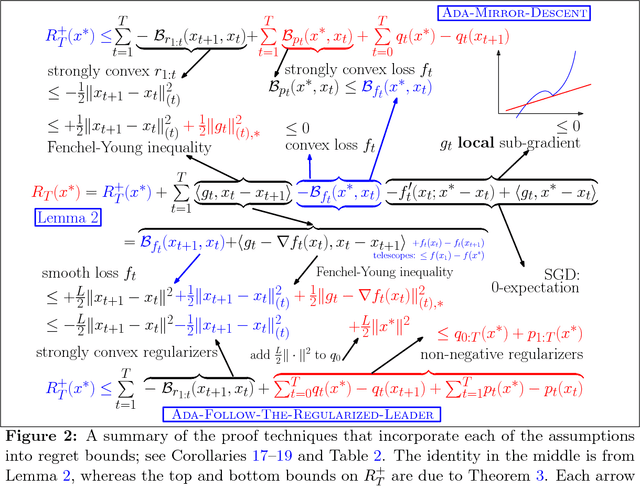
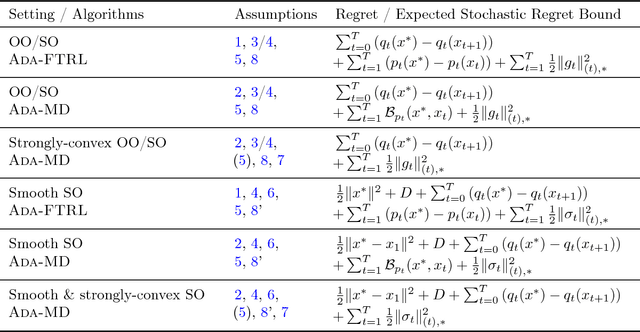
Recently, much work has been done on extending the scope of online learning and incremental stochastic optimization algorithms. In this paper we contribute to this effort in two ways: First, based on a new regret decomposition and a generalization of Bregman divergences, we provide a self-contained, modular analysis of the two workhorses of online learning: (general) adaptive versions of Mirror Descent (MD) and the Follow-the-Regularized-Leader (FTRL) algorithms. The analysis is done with extra care so as not to introduce assumptions not needed in the proofs and allows to combine, in a straightforward way, different algorithmic ideas (e.g., adaptivity, optimism, implicit updates) and learning settings (e.g., strongly convex or composite objectives). This way we are able to reprove, extend and refine a large body of the literature, while keeping the proofs concise. The second contribution is a byproduct of this careful analysis: We present algorithms with improved variational bounds for smooth, composite objectives, including a new family of optimistic MD algorithms with only one projection step per round. Furthermore, we provide a simple extension of adaptive regret bounds to practically relevant non-convex problem settings with essentially no extra effort.
Fast Cross-Validation for Incremental Learning
Jun 30, 2015
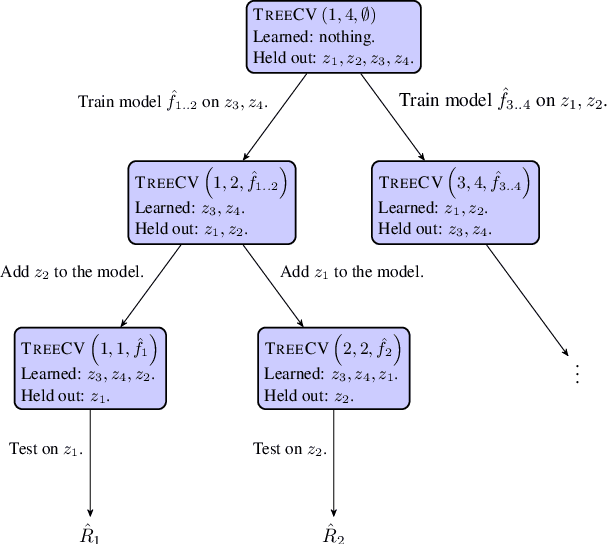
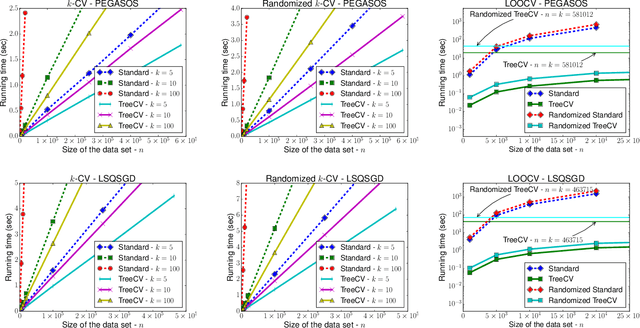
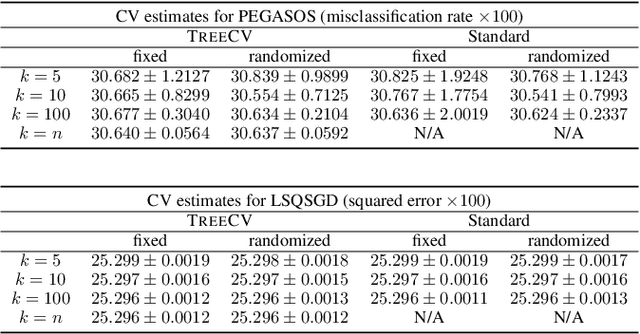
Cross-validation (CV) is one of the main tools for performance estimation and parameter tuning in machine learning. The general recipe for computing CV estimate is to run a learning algorithm separately for each CV fold, a computationally expensive process. In this paper, we propose a new approach to reduce the computational burden of CV-based performance estimation. As opposed to all previous attempts, which are specific to a particular learning model or problem domain, we propose a general method applicable to a large class of incremental learning algorithms, which are uniquely fitted to big data problems. In particular, our method applies to a wide range of supervised and unsupervised learning tasks with different performance criteria, as long as the base learning algorithm is incremental. We show that the running time of the algorithm scales logarithmically, rather than linearly, in the number of CV folds. Furthermore, the algorithm has favorable properties for parallel and distributed implementation. Experiments with state-of-the-art incremental learning algorithms confirm the practicality of the proposed method.
Online Learning under Delayed Feedback
Jun 05, 2013
Online learning with delayed feedback has received increasing attention recently due to its several applications in distributed, web-based learning problems. In this paper we provide a systematic study of the topic, and analyze the effect of delay on the regret of online learning algorithms. Somewhat surprisingly, it turns out that delay increases the regret in a multiplicative way in adversarial problems, and in an additive way in stochastic problems. We give meta-algorithms that transform, in a black-box fashion, algorithms developed for the non-delayed case into ones that can handle the presence of delays in the feedback loop. Modifications of the well-known UCB algorithm are also developed for the bandit problem with delayed feedback, with the advantage over the meta-algorithms that they can be implemented with lower complexity.