 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgei-WiViG: Interpretable Window Vision GNN
Mar 11, 2025Deep learning models based on graph neural networks have emerged as a popular approach for solving computer vision problems. They encode the image into a graph structure and can be beneficial for efficiently capturing the long-range dependencies typically present in remote sensing imagery. However, an important drawback of these methods is their black-box nature which may hamper their wider usage in critical applications. In this work, we tackle the self-interpretability of the graph-based vision models by proposing our Interpretable Window Vision GNN (i-WiViG) approach, which provides explanations by automatically identifying the relevant subgraphs for the model prediction. This is achieved with window-based image graph processing that constrains the node receptive field to a local image region and by using a self-interpretable graph bottleneck that ranks the importance of the long-range relations between the image regions. We evaluate our approach to remote sensing classification and regression tasks, showing it achieves competitive performance while providing inherent and faithful explanations through the identified relations. Further, the quantitative evaluation reveals that our model reduces the infidelity of post-hoc explanations compared to other Vision GNN models, without sacrificing explanation sparsity.
A Self-Adaptive Synthetic Over-Sampling Technique for Imbalanced Classification
Nov 25, 2019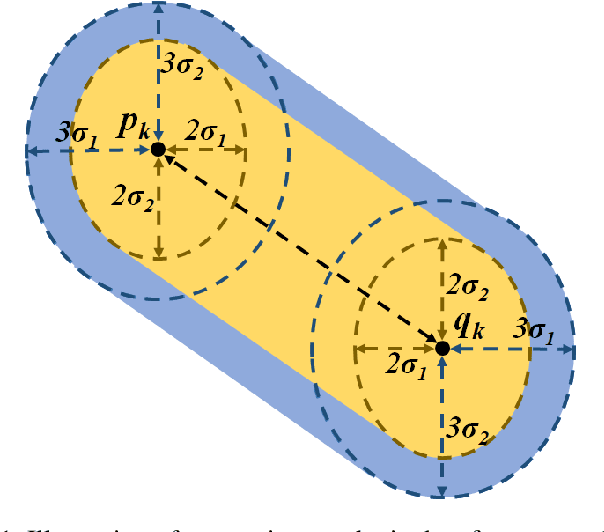



Traditionally, in supervised machine learning, (a significant) part of the available data (usually 50% to 80%) is used for training and the rest for validation. In many problems, however, the data is highly imbalanced in regard to different classes or does not have good coverage of the feasible data space which, in turn, creates problems in validation and usage phase. In this paper, we propose a technique for synthesising feasible and likely data to help balance the classes as well as to boost the performance in terms of confusion matrix as well as overall. The idea, in a nutshell, is to synthesise data samples in close vicinity to the actual data samples specifically for the less represented (minority) classes. This has also implications to the so-called fairness of machine learning. In this paper, we propose a specific method for synthesising data in a way to balance the classes and boost the performance, especially of the minority classes. It is generic and can be applied to different base algorithms, e.g. support vector machine, k-nearest neighbour, deep networks, rule-based classifiers, decision trees, etc. The results demonstrated that: i) a significantly more balanced (and fair) classification results can be achieved; ii) that the overall performance as well as the performance per class measured by confusion matrix can be boosted. In addition, this approach can be very valuable for the cases when the number of actual available labelled data is small which itself is one of the problems of the contemporary machine learning.