 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn to Synchronize, Synchronize to Learn
Oct 06, 2020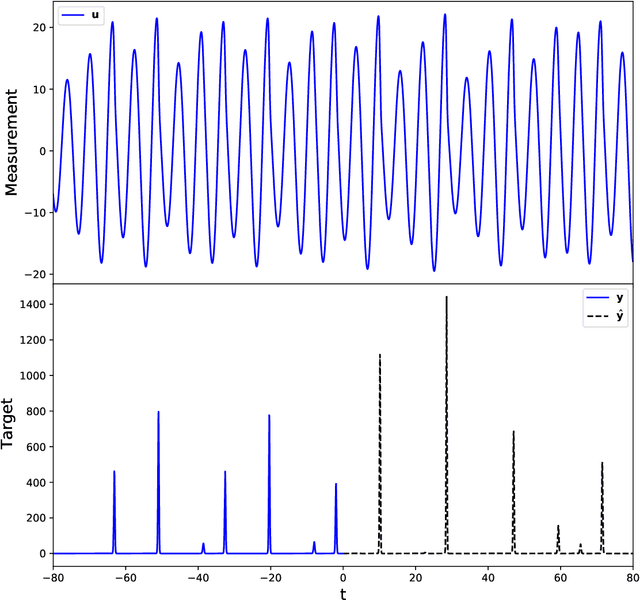

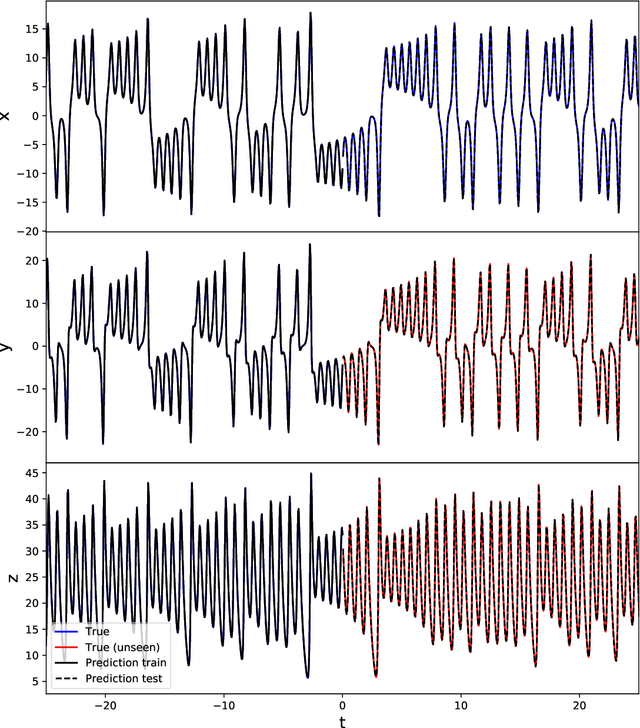

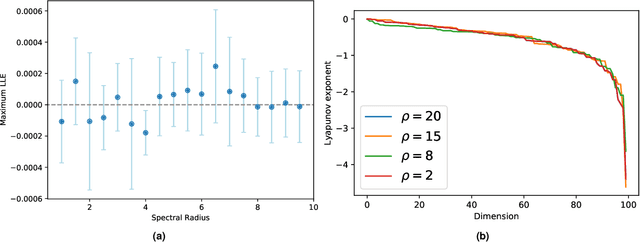
In recent years, the machine learning community has seen a continuous growing interest in research aimed at investigating dynamical aspects of both training procedures and perfected models. Of particular interest among recurrent neural networks, we have the Reservoir Computing (RC) paradigm for its conceptual simplicity and fast training scheme. Yet, the guiding principles under which RC operates are only partially understood. In this work, we study the properties behind learning dynamical systems with RC and propose a new guiding principle based on Generalized Synchronization (GS) granting its feasibility. We show that the well-known Echo State Property (ESP) implies and is implied by GS, so that theoretical results derived from the ESP still hold when GS does. However, by using GS one can profitably study the RC learning procedure by linking the reservoir dynamics with the readout training. Notably, this allows us to shed light on the interplay between the input encoding performed by the reservoir and the output produced by the readout optimized for the task at hand. In addition, we show that - as opposed to the ESP - satisfaction of the GS can be measured by means of the Mutual False Nearest Neighbors index, which makes effective to practitioners theoretical derivations.
Input representation in recurrent neural networks dynamics
Mar 24, 2020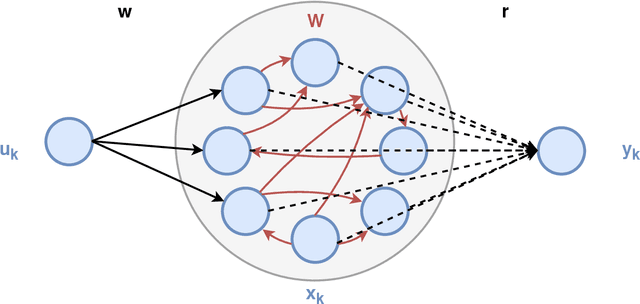
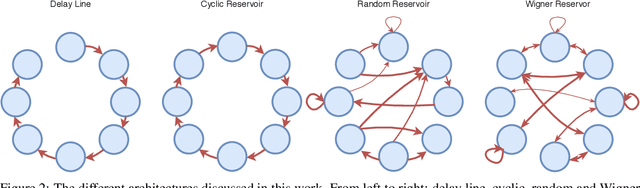
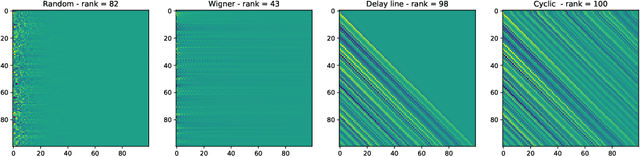
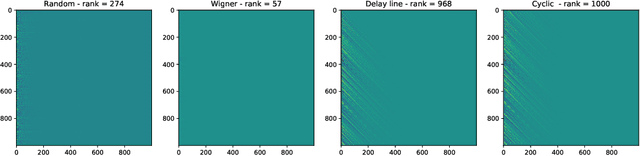
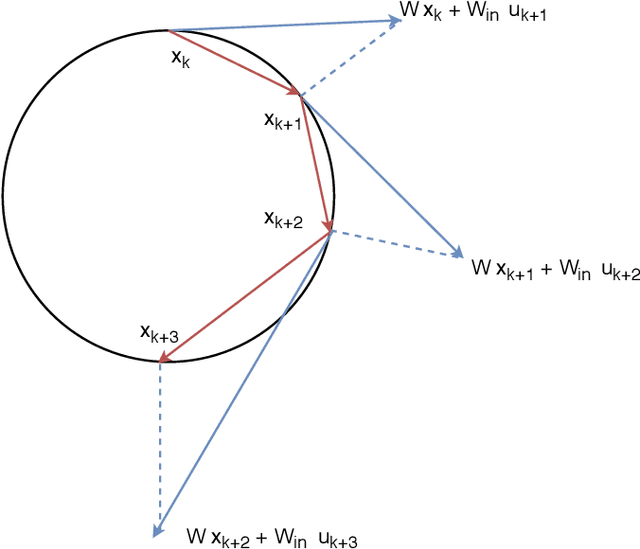
Reservoir computing is a popular approach to design recurrent neural networks, due to its training simplicity and its approximation performance. The recurrent part of these networks is not trained (e.g. via gradient descent), making them appealing for analytical studies, raising the interest of a vast community of researcher spanning from dynamical systems to neuroscience. It emerges that, even in the simple linear case, the working principle of these networks is not fully understood and the applied research is usually driven by heuristics. A novel analysis of the dynamics of such networks is proposed, which allows one to express the state evolution using the controllability matrix. Such a matrix encodes salient characteristics of the network dynamics: in particular, its rank can be used as an input-indepedent measure of the memory of the network. Using the proposed approach, it is possible to compare different architectures and explain why a cyclic topology achieves favourable results.
Echo State Networks with Self-Normalizing Activations on the Hyper-Sphere
Mar 27, 2019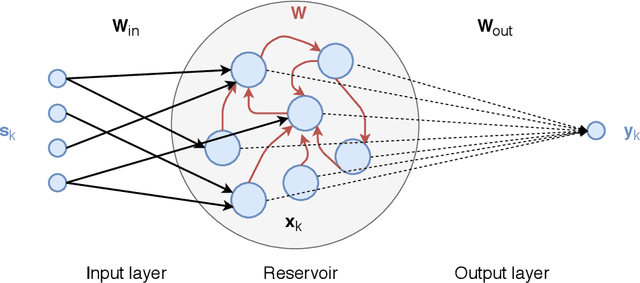

Among the various architectures of Recurrent Neural Networks, Echo State Networks (ESNs) emerged due to their simplified and inexpensive training procedure. These networks are known to be sensitive to the setting of hyper-parameters, which critically affect their behaviour. Results show that their performance is usually maximized in a narrow region of hyper-parameter space called edge of chaos. Finding such a region requires searching in hyper-parameter space in a sensible way: hyper-parameter configurations marginally outside such a region might yield networks exhibiting fully developed chaos, hence producing unreliable computations. The performance gain due to optimizing hyper-parameters can be studied by considering the memory--nonlinearity trade-off, i.e., the fact that increasing the nonlinear behavior of the network degrades its ability to remember past inputs, and vice-versa. In this paper, we propose a model of ESNs that eliminates critical dependence on hyper-parameters, resulting in networks that provably cannot enter a chaotic regime and, at the same time, denotes nonlinear behaviour in phase space characterised by a large memory of past inputs, comparable to the one of linear networks. Our contribution is supported by experiments corroborating our theoretical findings, showing that the proposed model displays dynamics that are rich-enough to approximate many common nonlinear systems used for benchmarking.
A characterization of the Edge of Criticality in Binary Echo State Networks
Oct 03, 2018



Echo State Networks (ESNs) are simplified recurrent neural network models composed of a reservoir and a linear, trainable readout layer. The reservoir is tunable by some hyper-parameters that control the network behaviour. ESNs are known to be effective in solving tasks when configured on a region in (hyper-)parameter space called \emph{Edge of Criticality} (EoC), where the system is maximally sensitive to perturbations hence affecting its behaviour. In this paper, we propose binary ESNs, which are architecturally equivalent to standard ESNs but consider binary activation functions and binary recurrent weights. For these networks, we derive a closed-form expression for the EoC in the autonomous case and perform simulations in order to assess their behavior in the case of noisy neurons and in the presence of a signal. We propose a theoretical explanation for the fact that the variance of the input plays a major role in characterizing the EoC.