 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJaxDecompiler: Redefining Gradient-Informed Software Design
Mar 14, 2024


Among numerical libraries capable of computing gradient descent optimization, JAX stands out by offering more features, accelerated by an intermediate representation known as Jaxpr language. However, editing the Jaxpr code is not directly possible. This article introduces JaxDecompiler, a tool that transforms any JAX function into an editable Python code, especially useful for editing the JAX function generated by the gradient function. JaxDecompiler simplifies the processes of reverse engineering, understanding, customizing, and interoperability of software developed by JAX. We highlight its capabilities, emphasize its practical applications especially in deep learning and more generally gradient-informed software, and demonstrate that the decompiled code speed performance is similar to the original.
Deep Learning Inference Frameworks Benchmark
Oct 09, 2022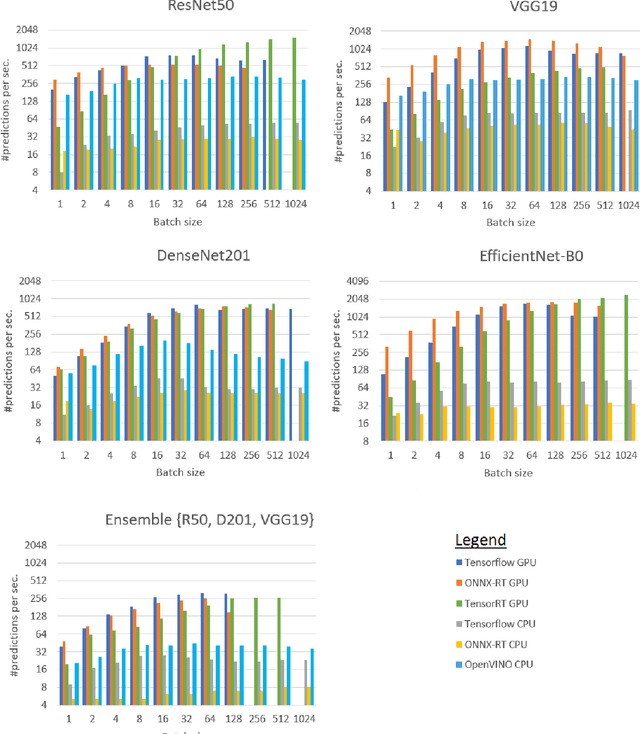
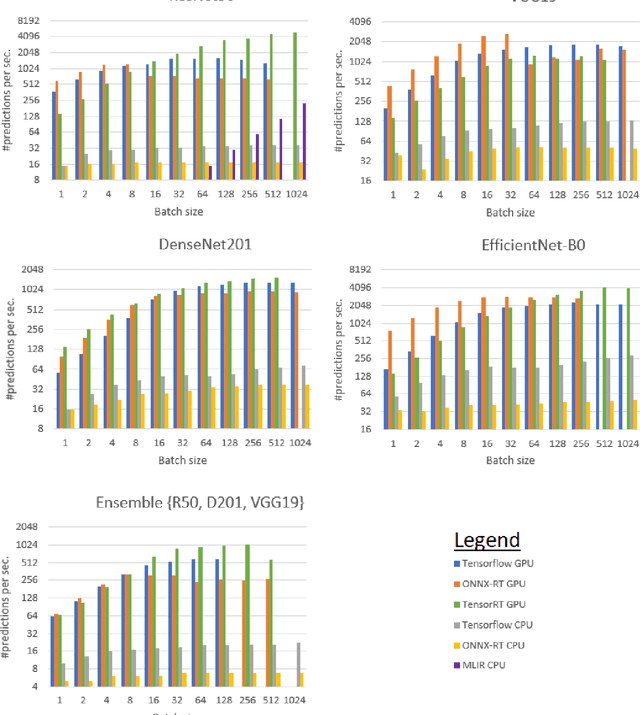
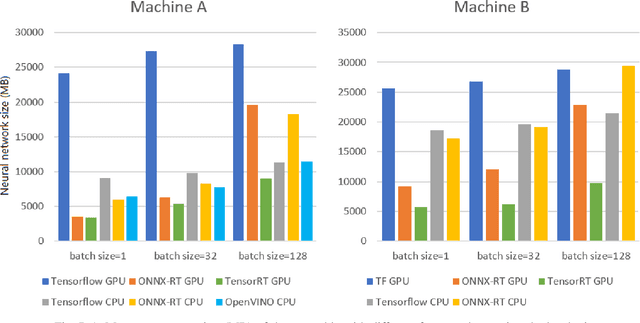
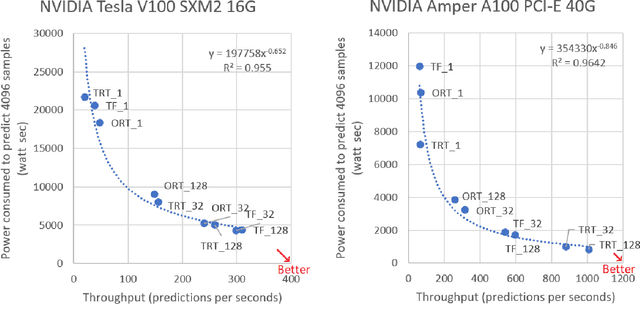
Deep learning (DL) has been widely adopted those last years but they are computing-intensive method. Therefore, scientists proposed diverse optimization to accelerate their predictions for end-user applications. However, no single inference framework currently dominates in terms of performance. This paper takes a holistic approach to conduct an empirical comparison and analysis of four representative DL inference frameworks. First, given a selection of CPU-GPU configurations, we show that for a specific DL framework, different configurations of its settings may have a significant impact on the prediction speed, memory, and computing power. Second, to the best of our knowledge, this study is the first to identify the opportunities for accelerating the ensemble of co-localized models in the same GPU. This measurement study provides an in-depth empirical comparison and analysis of four representative DL frameworks and offers practical guidance for service providers to deploy and deliver DL predictions.
Distributed Ensembles of Reinforcement Learning Agents for Electricity Control
Aug 30, 2022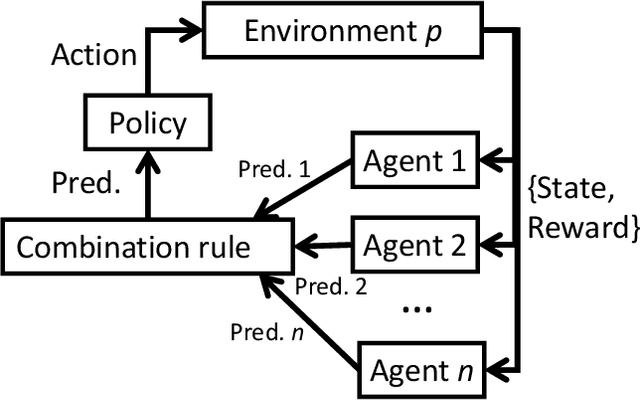
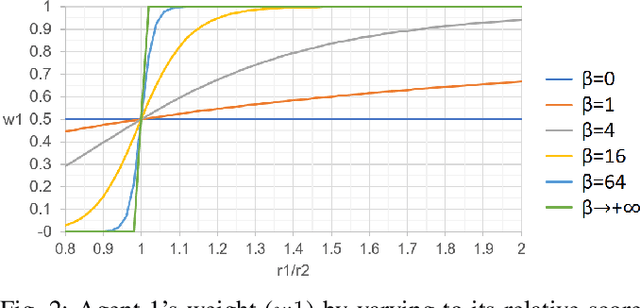
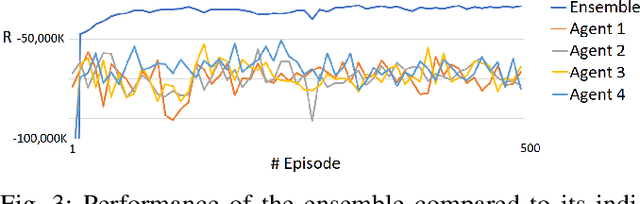
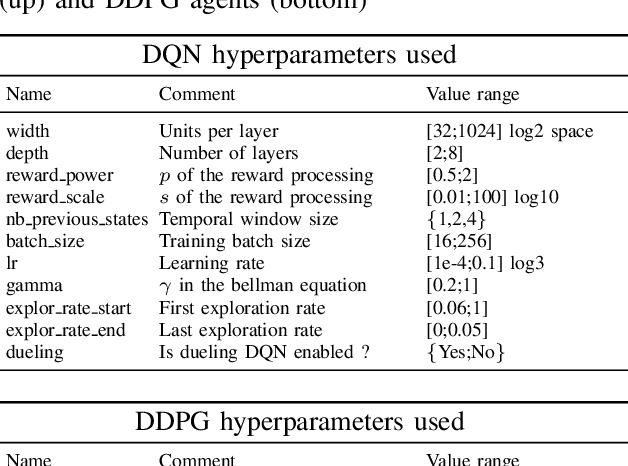
Deep Reinforcement Learning (or just "RL") is gaining popularity for industrial and research applications. However, it still suffers from some key limits slowing down its widespread adoption. Its performance is sensitive to initial conditions and non-determinism. To unlock those challenges, we propose a procedure for building ensembles of RL agents to efficiently build better local decisions toward long-term cumulated rewards. For the first time, hundreds of experiments have been done to compare different ensemble constructions procedures in 2 electricity control environments. We discovered an ensemble of 4 agents improves accumulated rewards by 46%, improves reproducibility by a factor of 3.6, and can naturally and efficiently train and predict in parallel on GPUs and CPUs.
Weakly Supervised Faster-RCNN+FPN to classify animals in camera trap images
Aug 30, 2022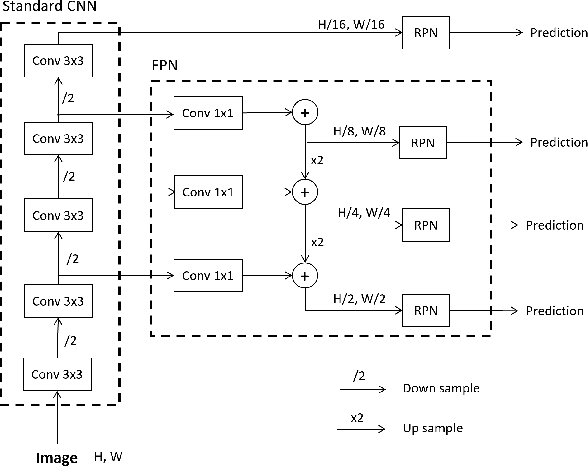
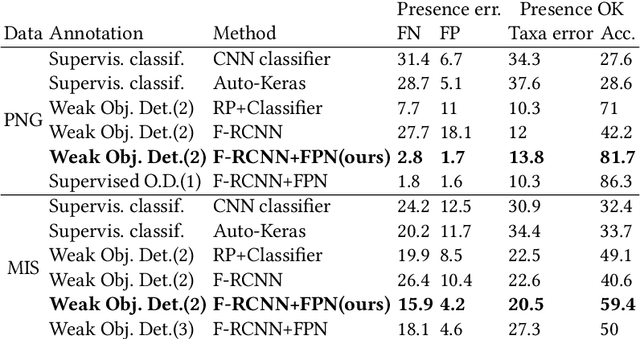
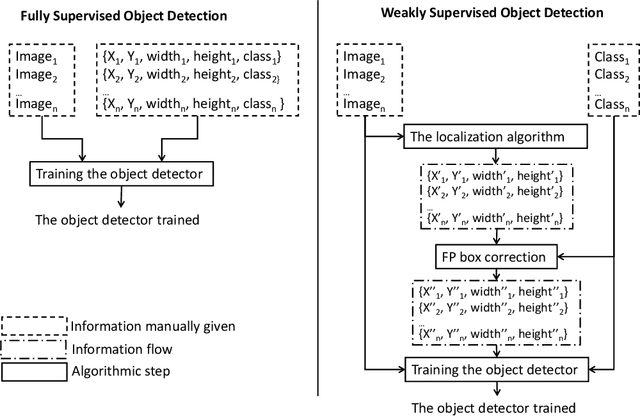
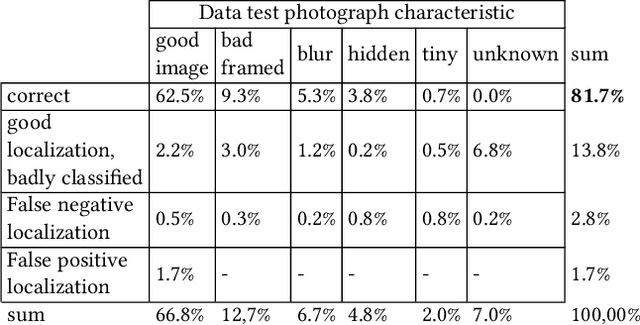
Camera traps have revolutionized the animal research of many species that were previously nearly impossible to observe due to their habitat or behavior. They are cameras generally fixed to a tree that take a short sequence of images when triggered. Deep learning has the potential to overcome the workload to automate image classification according to taxon or empty images. However, a standard deep neural network classifier fails because animals often represent a small portion of the high-definition images. That is why we propose a workflow named Weakly Object Detection Faster-RCNN+FPN which suits this challenge. The model is weakly supervised because it requires only the animal taxon label per image but doesn't require any manual bounding box annotations. First, it automatically performs the weakly-supervised bounding box annotation using the motion from multiple frames. Then, it trains a Faster-RCNN+FPN model using this weak supervision. Experimental results have been obtained with two datasets from a Papua New Guinea and Missouri biodiversity monitoring campaign, then on an easily reproducible testbed.
An efficient and flexible inference system for serving heterogeneous ensembles of deep neural networks
Aug 30, 2022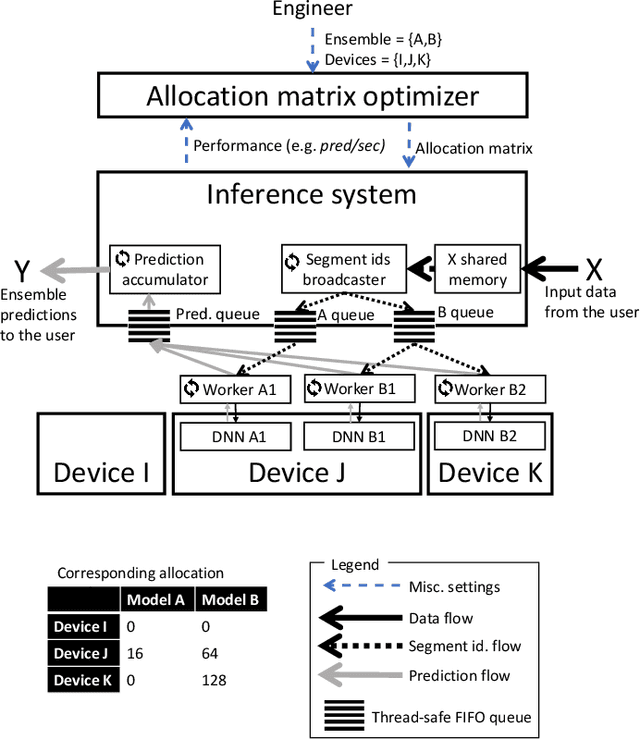
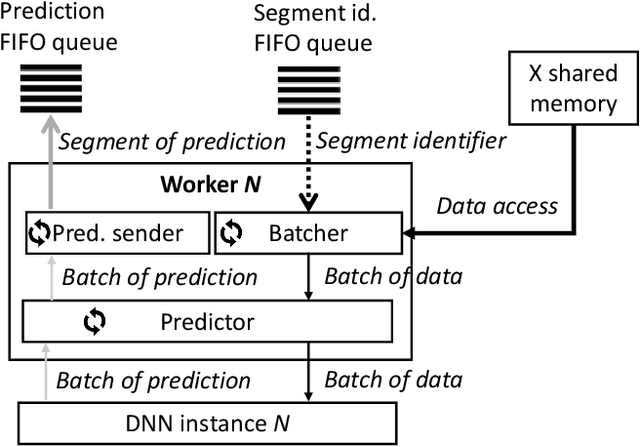
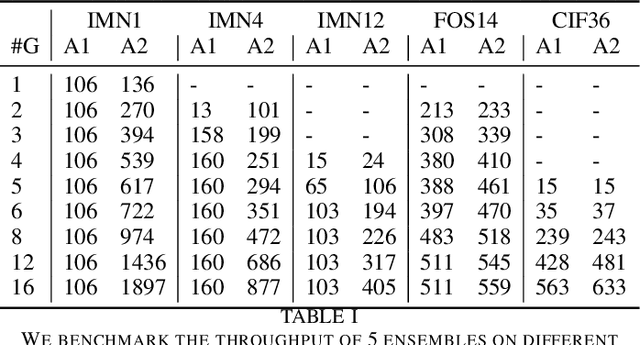
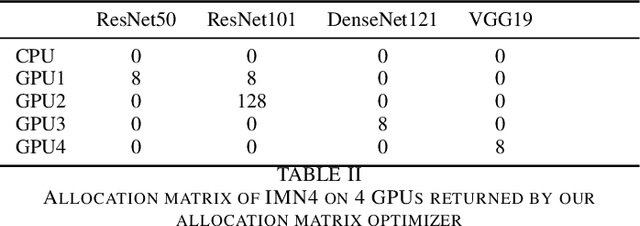
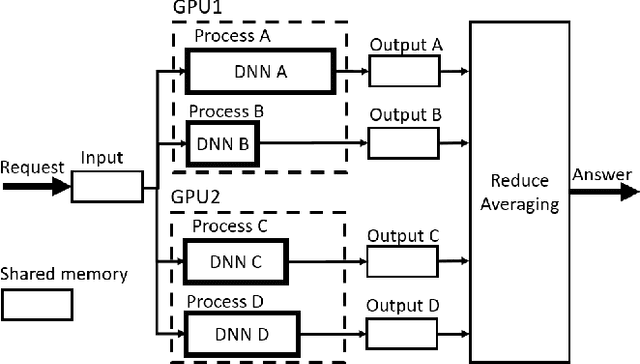
Ensembles of Deep Neural Networks (DNNs) have achieved qualitative predictions but they are computing and memory intensive. Therefore, the demand is growing to make them answer a heavy workload of requests with available computational resources. Unlike recent initiatives on inference servers and inference frameworks, which focus on the prediction of single DNNs, we propose a new software layer to serve with flexibility and efficiency ensembles of DNNs. Our inference system is designed with several technical innovations. First, we propose a novel procedure to find a good allocation matrix between devices (CPUs or GPUs) and DNN instances. It runs successively a worst-fit to allocate DNNs into the memory devices and a greedy algorithm to optimize allocation settings and speed up the ensemble. Second, we design the inference system based on multiple processes to run asynchronously: batching, prediction, and the combination rule with an efficient internal communication scheme to avoid overhead. Experiments show the flexibility and efficiency under extreme scenarios: It successes to serve an ensemble of 12 heavy DNNs into 4 GPUs and at the opposite, one single DNN multi-threaded into 16 GPUs. It also outperforms the simple baseline consisting of optimizing the batch size of DNNs by a speedup up to 2.7X on the image classification task.
A Deep Neural Networks ensemble workflow from hyperparameter search to inference leveraging GPU clusters
Aug 30, 2022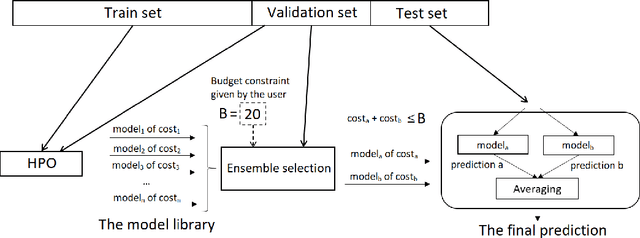

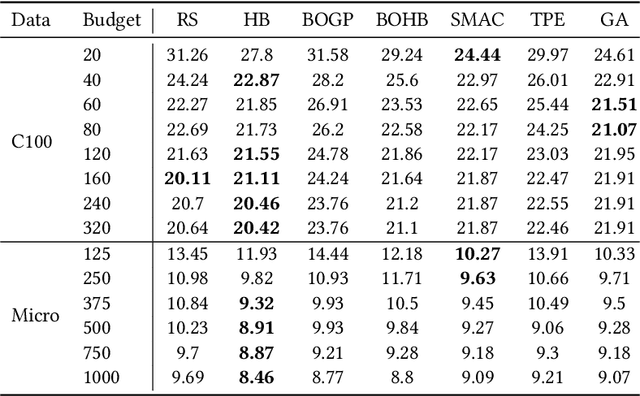
Automated Machine Learning with ensembling (or AutoML with ensembling) seeks to automatically build ensembles of Deep Neural Networks (DNNs) to achieve qualitative predictions. Ensemble of DNNs are well known to avoid over-fitting but they are memory and time consuming approaches. Therefore, an ideal AutoML would produce in one single run time different ensembles regarding accuracy and inference speed. While previous works on AutoML focus to search for the best model to maximize its generalization ability, we rather propose a new AutoML to build a larger library of accurate and diverse individual models to then construct ensembles. First, our extensive benchmarks show asynchronous Hyperband is an efficient and robust way to build a large number of diverse models to combine them. Then, a new ensemble selection method based on a multi-objective greedy algorithm is proposed to generate accurate ensembles by controlling their computing cost. Finally, we propose a novel algorithm to optimize the inference of the DNNs ensemble in a GPU cluster based on allocation optimization. The produced AutoML with ensemble method shows robust results on two datasets using efficiently GPU clusters during both the training phase and the inference phase.