 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeeDrop: Self-supervised Shape Representation from Sparse Point Clouds using Needle Dropping
Dec 02, 2021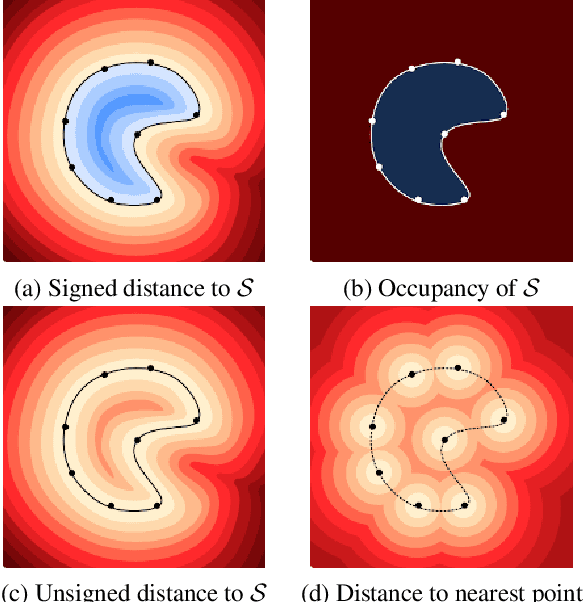

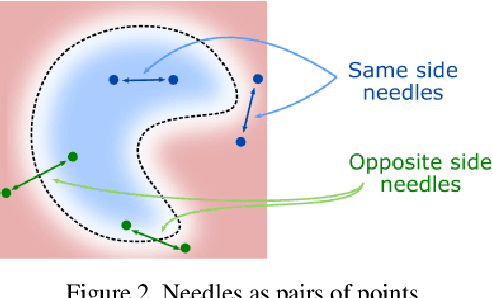
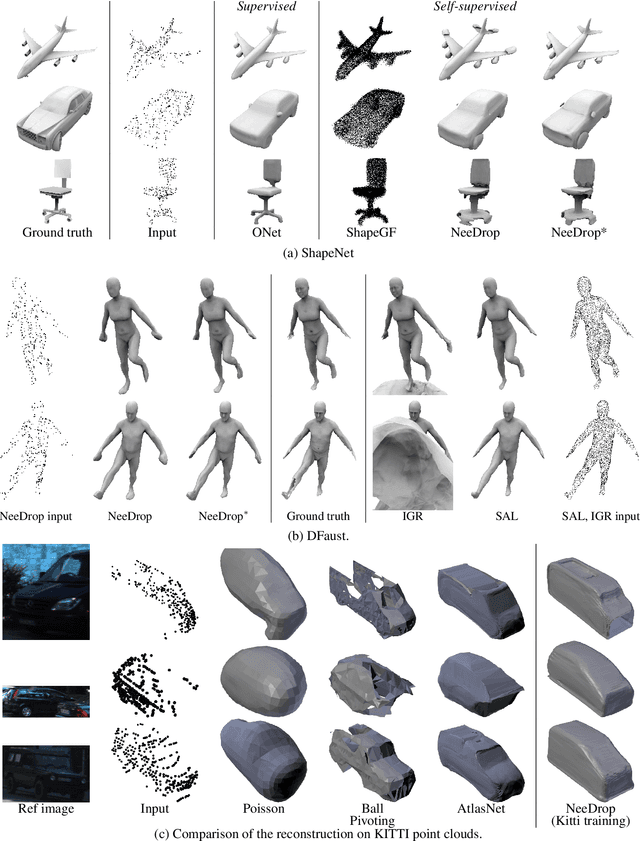
There has been recently a growing interest for implicit shape representations. Contrary to explicit representations, they have no resolution limitations and they easily deal with a wide variety of surface topologies. To learn these implicit representations, current approaches rely on a certain level of shape supervision (e.g., inside/outside information or distance-to-shape knowledge), or at least require a dense point cloud (to approximate well enough the distance-to-shape). In contrast, we introduce NeeDrop, a self-supervised method for learning shape representations from possibly extremely sparse point clouds. Like in Buffon's needle problem, we "drop" (sample) needles on the point cloud and consider that, statistically, close to the surface, the needle end points lie on opposite sides of the surface. No shape knowledge is required and the point cloud can be highly sparse, e.g., as lidar point clouds acquired by vehicles. Previous self-supervised shape representation approaches fail to produce good-quality results on this kind of data. We obtain quantitative results on par with existing supervised approaches on shape reconstruction datasets and show promising qualitative results on hard autonomous driving datasets such as KITTI.
* 22 pages
Surface Reconstruction from 3D Line Segments
Nov 01, 2019



In man-made environments such as indoor scenes, when point-based 3D reconstruction fails due to the lack of texture, lines can still be detected and used to support surfaces. We present a novel method for watertight piecewise-planar surface reconstruction from 3D line segments with visibility information. First, planes are extracted by a novel RANSAC approach for line segments that allows multiple shape support. Then, each 3D cell of a plane arrangement is labeled full or empty based on line attachment to planes, visibility and regularization. Experiments show the robustness to sparse input data, noise and outliers.
Pose from Shape: Deep Pose Estimation for Arbitrary 3D Objects
Jun 12, 2019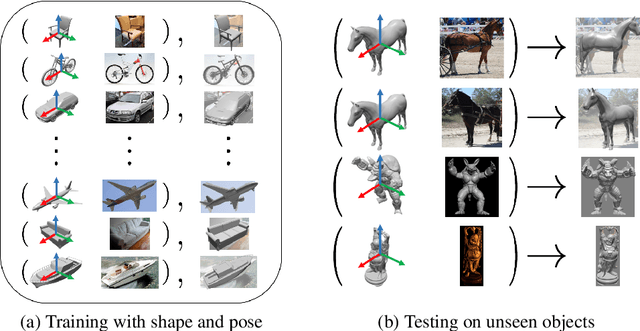

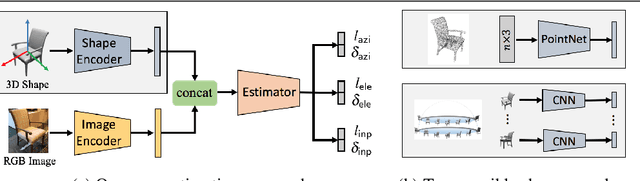
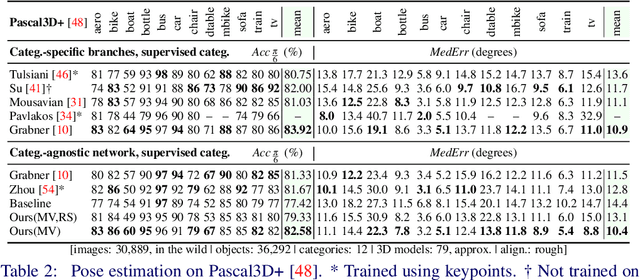
Most deep pose estimation methods need to be trained for specific object instances or categories. In this work we propose a completely generic deep pose estimation approach, which does not require the network to have been trained on relevant categories, nor objects in a category to have a canonical pose. We believe this is a crucial step to design robotic systems that can interact with new objects in the wild not belonging to a predefined category. Our main insight is to dynamically condition pose estimation with a representation of the 3D shape of the target object. More precisely, we train a Convolutional Neural Network that takes as input both a test image and a 3D model, and outputs the relative 3D pose of the object in the input image with respect to the 3D model. We demonstrate that our method boosts performances for supervised category pose estimation on standard benchmarks, namely Pascal3D+, ObjectNet3D and Pix3D, on which we provide results superior to the state of the art. More importantly, we show that our network trained on everyday man-made objects from ShapeNet generalizes without any additional training to completely new types of 3D objects by providing results on the LINEMOD dataset as well as on natural entities such as animals from ImageNet.