 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEthically Collecting Multi-Modal Spontaneous Conversations with People that have Cognitive Impairments
Sep 30, 2020



In order to make spoken dialogue systems (such as Amazon Alexa or Google Assistant) more accessible and naturally interactive for people with cognitive impairments, appropriate data must be obtainable. Recordings of multi-modal spontaneous conversations with vulnerable user groups are scarce however and this valuable data is challenging to collect. Researchers that call for this data are commonly inexperienced in ethical and legal issues around working with vulnerable participants. Additionally, standard recording equipment is insecure and should not be used to capture sensitive data. We spent a year consulting experts on how to ethically capture and share recordings of multi-modal spontaneous conversations with vulnerable user groups. In this paper we provide guidance, collated from these experts, on how to ethically collect such data and we present a new system - "CUSCO" - to capture, transport and exchange sensitive data securely. This framework is intended to be easily followed and implemented to encourage further publications of similar corpora. Using this guide and secure recording system, researchers can review and refine their ethical measures.
* Published at LREC's Workshop on Legal and Ethical Issues in Human Language Technologies 2020
Emotion Recognition in Low-Resource Settings: An Evaluation of Automatic Feature Selection Methods
Aug 28, 2019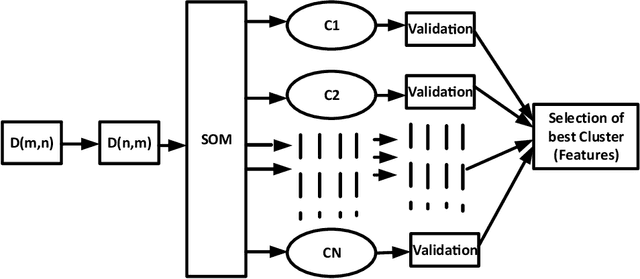
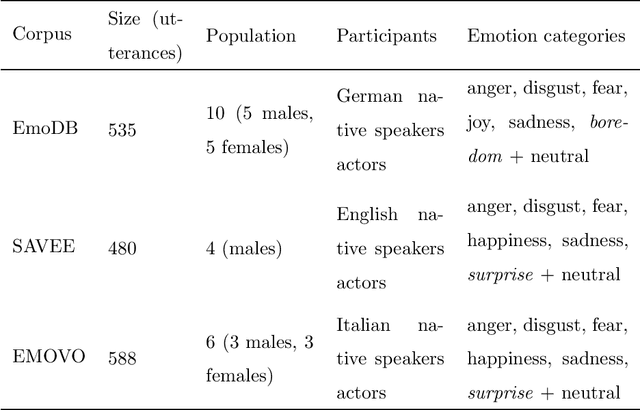

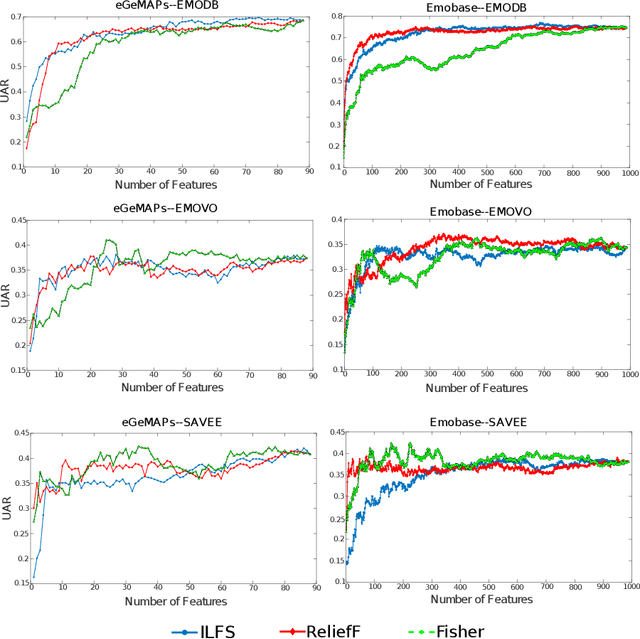
Research in automatic emotion recognition has seldom addressed the issue of computational resource utilization. With the advent of ambient technology, which employs a variety of low-power, resource constrained devices, this issue is increasingly gaining interest. This is especially the case in the context of health and elderly care technologies, where interventions aim at maintaining the user's independence as unobtrusively as possible. In this context, efforts are being made to model human social signals such as emotions, which can aid health monitoring. This paper focuses on emotion recognition from speech data. In order to minimize the system's memory and computational needs, a minimum number of features should be extracted for use in machine learning models. A number of feature set reduction methods exist which seek to find minimal sets of relevant features. We evaluate three different state of the art feature selection methods: Infinite Latent Feature Selection (ILFS), ReliefF and Fisher (generalized Fisher score), and compare them to our recently proposed feature selection method named 'Active Feature Selection' (AFS). The evaluation is performed on three emotion recognition data sets (EmoDB, SAVEE and EMOVO) using two standard speech feature sets (i.e. eGeMAPs and emobase). The results show that similar or better accuracy can be achieved using subsets of features substantially smaller than entire feature set. A machine learning model trained on a smaller feature set will reduce the memory and computational resources of an emotion recognition system which can result in lowering the barriers for use of health monitoring technology.
A Method for Analysis of Patient Speech in Dialogue for Dementia Detection
Nov 25, 2018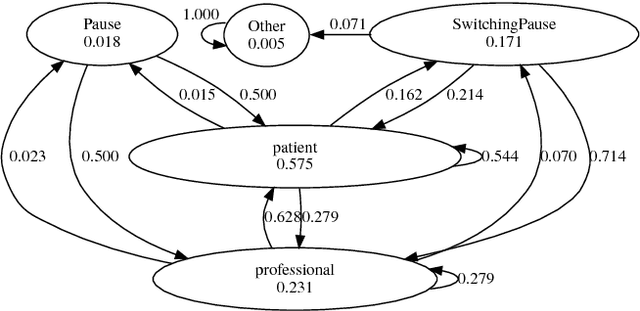
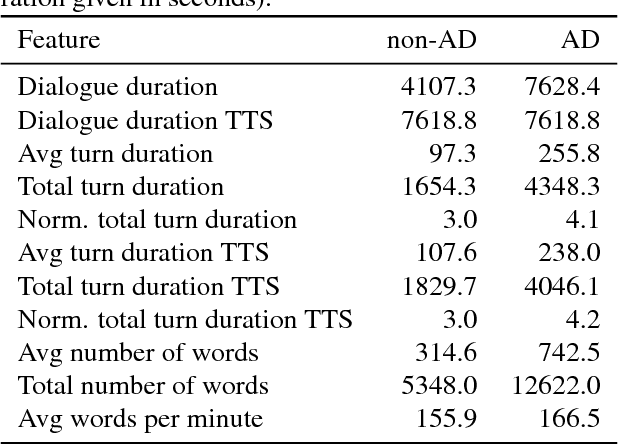
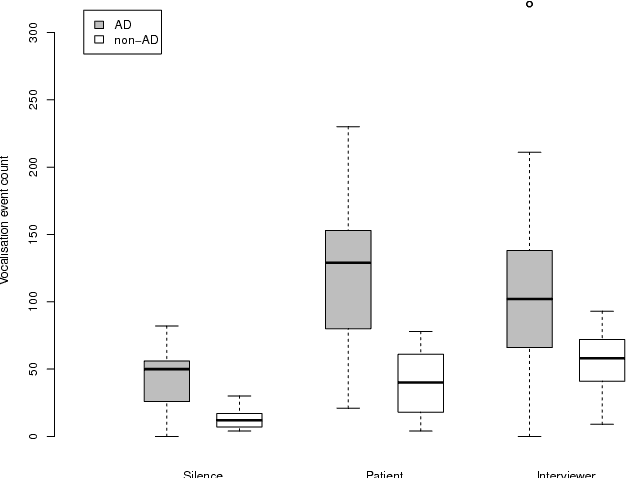
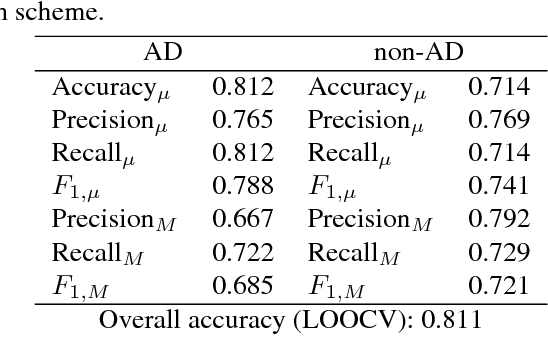
We present an approach to automatic detection of Alzheimer's type dementia based on characteristics of spontaneous spoken language dialogue consisting of interviews recorded in natural settings. The proposed method employs additive logistic regression (a machine learning boosting method) on content-free features extracted from dialogical interaction to build a predictive model. The model training data consisted of 21 dialogues between patients with Alzheimer's and interviewers, and 17 dialogues between patients with other health conditions and interviewers. Features analysed included speech rate, turn-taking patterns and other speech parameters. Despite relying solely on content-free features, our method obtains overall accuracy of 86.5\%, a result comparable to those of state-of-the-art methods that employ more complex lexical, syntactic and semantic features. While further investigation is needed, the fact that we were able to obtain promising results using only features that can be easily extracted from spontaneous dialogues suggests the possibility of designing non-invasive and low-cost mental health monitoring tools for use at scale.