 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotion Recognition in Low-Resource Settings: An Evaluation of Automatic Feature Selection Methods
Paper and Code
Aug 28, 2019

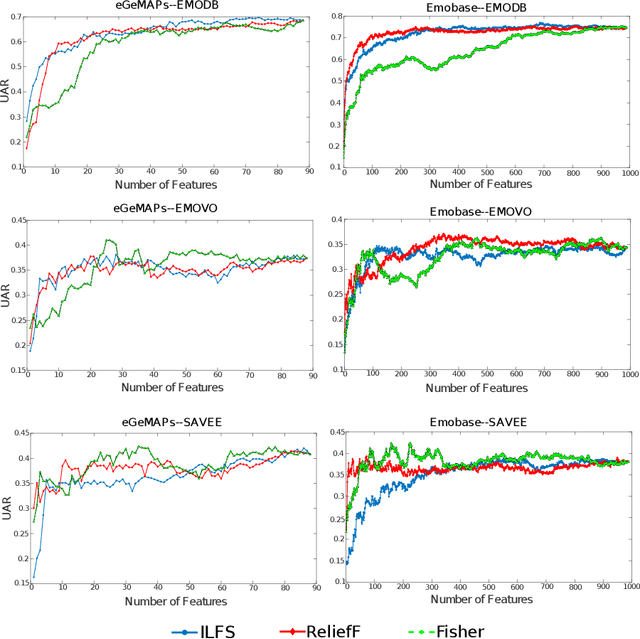
Research in automatic emotion recognition has seldom addressed the issue of computational resource utilization. With the advent of ambient technology, which employs a variety of low-power, resource constrained devices, this issue is increasingly gaining interest. This is especially the case in the context of health and elderly care technologies, where interventions aim at maintaining the user's independence as unobtrusively as possible. In this context, efforts are being made to model human social signals such as emotions, which can aid health monitoring. This paper focuses on emotion recognition from speech data. In order to minimize the system's memory and computational needs, a minimum number of features should be extracted for use in machine learning models. A number of feature set reduction methods exist which seek to find minimal sets of relevant features. We evaluate three different state of the art feature selection methods: Infinite Latent Feature Selection (ILFS), ReliefF and Fisher (generalized Fisher score), and compare them to our recently proposed feature selection method named 'Active Feature Selection' (AFS). The evaluation is performed on three emotion recognition data sets (EmoDB, SAVEE and EMOVO) using two standard speech feature sets (i.e. eGeMAPs and emobase). The results show that similar or better accuracy can be achieved using subsets of features substantially smaller than entire feature set. A machine learning model trained on a smaller feature set will reduce the memory and computational resources of an emotion recognition system which can result in lowering the barriers for use of health monitoring technology.