 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time cortical simulations: energy and interconnect scaling on distributed systems
Dec 27, 2018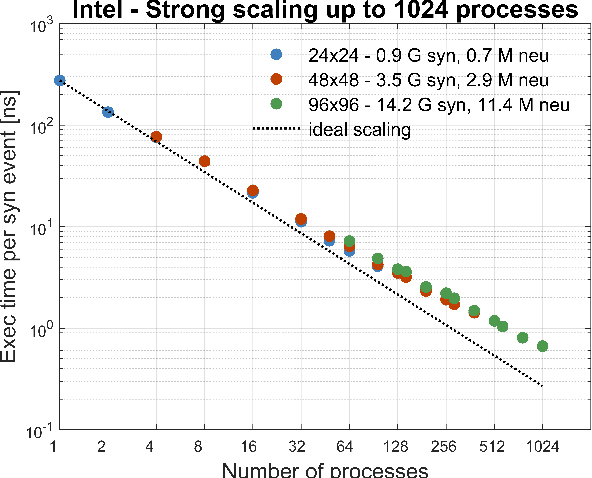
We profile the impact of computation and inter-processor communication on the energy consumption and on the scaling of cortical simulations approaching the real-time regime on distributed computing platforms. Also, the speed and energy consumption of processor architectures typical of standard HPC and embedded platforms are compared. We demonstrate the importance of the design of low-latency interconnect for speed and energy consumption. The cost of cortical simulations is quantified using the Joule per synaptic event metric on both architectures. Reaching efficient real-time on large scale cortical simulations is of increasing relevance for both future bio-inspired artificial intelligence applications and for understanding the cognitive functions of the brain, a scientific quest that will require to embed large scale simulations into highly complex virtual or real worlds. This work stands at the crossroads between the WaveScalES experiment in the Human Brain Project (HBP), which includes the objective of large scale thalamo-cortical simulations of brain states and their transitions, and the ExaNeSt and EuroExa projects, that investigate the design of an ARM-based, low-power High Performance Computing (HPC) architecture with a dedicated interconnect scalable to million of cores; simulation of deep sleep Slow Wave Activity (SWA) and Asynchronous aWake (AW) regimes expressed by thalamo-cortical models are among their benchmarks.
The Brain on Low Power Architectures - Efficient Simulation of Cortical Slow Waves and Asynchronous States
Apr 10, 2018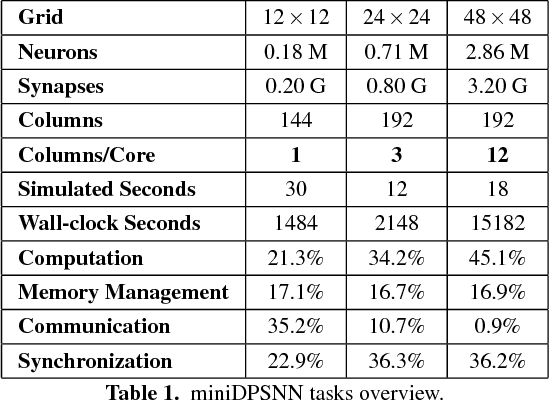
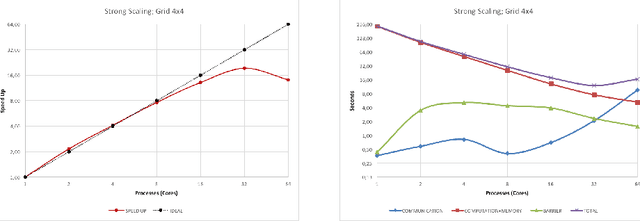
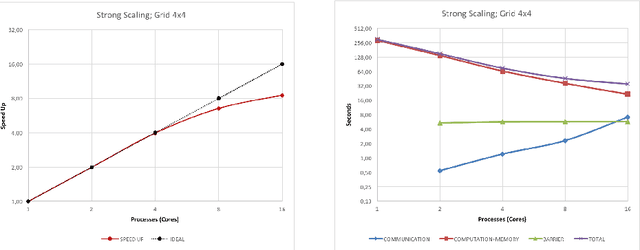
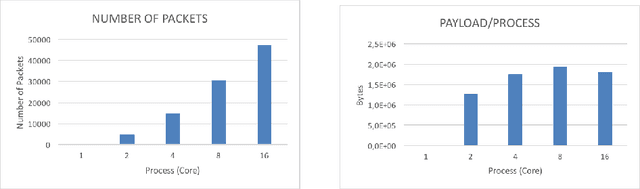
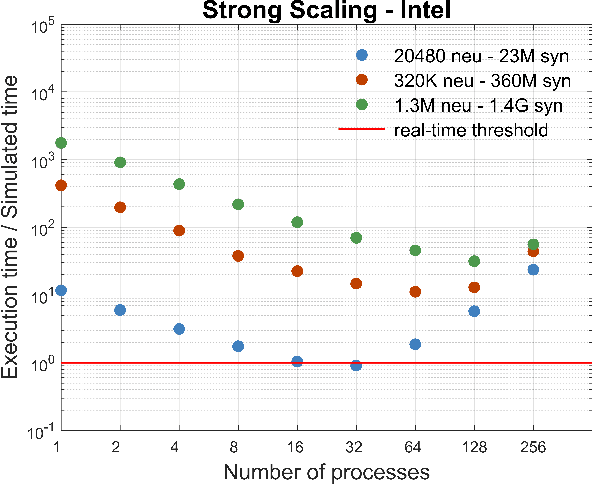
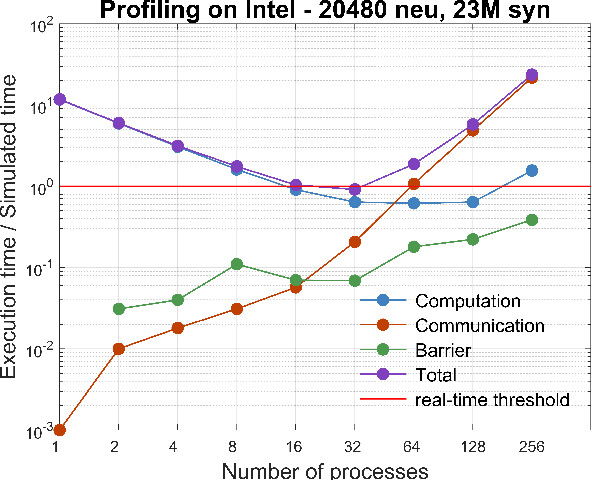
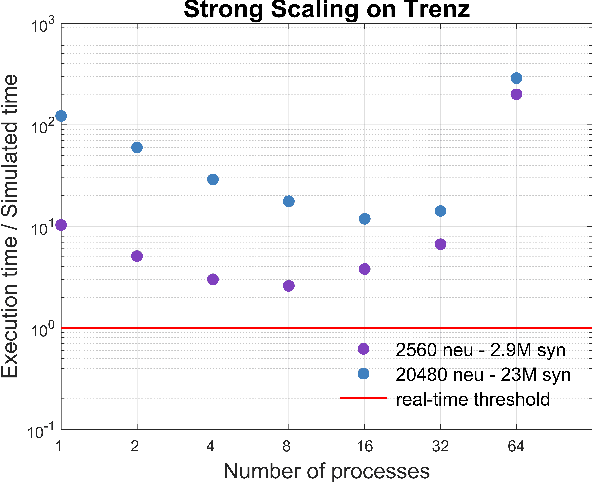
Efficient brain simulation is a scientific grand challenge, a parallel/distributed coding challenge and a source of requirements and suggestions for future computing architectures. Indeed, the human brain includes about 10^15 synapses and 10^11 neurons activated at a mean rate of several Hz. Full brain simulation poses Exascale challenges even if simulated at the highest abstraction level. The WaveScalES experiment in the Human Brain Project (HBP) has the goal of matching experimental measures and simulations of slow waves during deep-sleep and anesthesia and the transition to other brain states. The focus is the development of dedicated large-scale parallel/distributed simulation technologies. The ExaNeSt project designs an ARM-based, low-power HPC architecture scalable to million of cores, developing a dedicated scalable interconnect system, and SWA/AW simulations are included among the driving benchmarks. At the joint between both projects is the INFN proprietary Distributed and Plastic Spiking Neural Networks (DPSNN) simulation engine. DPSNN can be configured to stress either the networking or the computation features available on the execution platforms. The simulation stresses the networking component when the neural net - composed by a relatively low number of neurons, each one projecting thousands of synapses - is distributed over a large number of hardware cores. When growing the number of neurons per core, the computation starts to be the dominating component for short range connections. This paper reports about preliminary performance results obtained on an ARM-based HPC prototype developed in the framework of the ExaNeSt project. Furthermore, a comparison is given of instantaneous power, total energy consumption, execution time and energetic cost per synaptic event of SWA/AW DPSNN simulations when executed on either ARM- or Intel-based server platforms.
Gaussian and exponential lateral connectivity on distributed spiking neural network simulation
Mar 23, 2018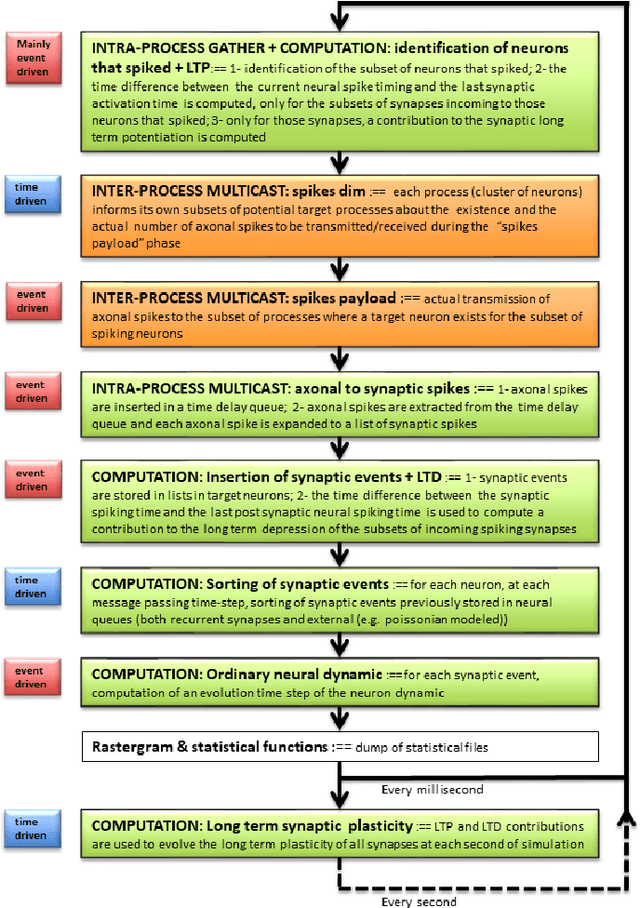
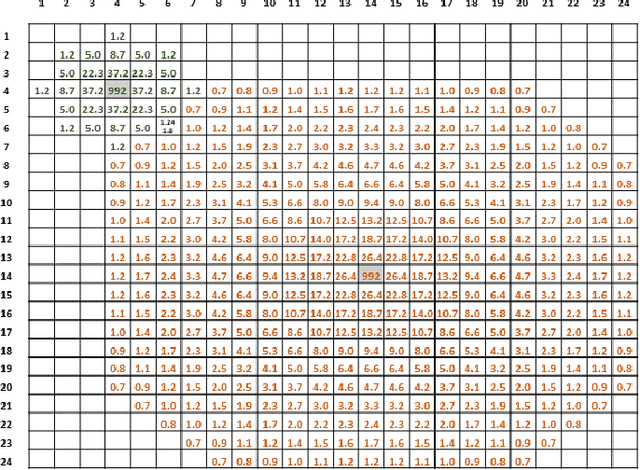
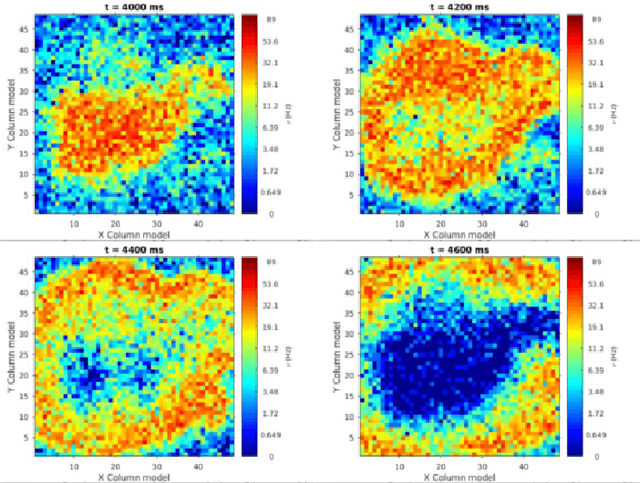
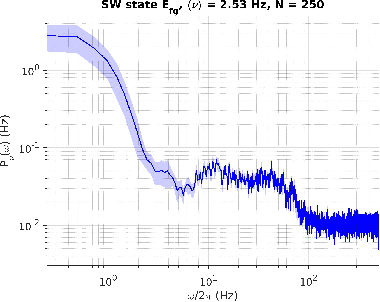
We measured the impact of long-range exponentially decaying intra-areal lateral connectivity on the scaling and memory occupation of a distributed spiking neural network simulator compared to that of short-range Gaussian decays. While previous studies adopted short-range connectivity, recent experimental neurosciences studies are pointing out the role of longer-range intra-areal connectivity with implications on neural simulation platforms. Two-dimensional grids of cortical columns composed by up to 11 M point-like spiking neurons with spike frequency adaption were connected by up to 30 G synapses using short- and long-range connectivity models. The MPI processes composing the distributed simulator were run on up to 1024 hardware cores, hosted on a 64 nodes server platform. The hardware platform was a cluster of IBM NX360 M5 16-core compute nodes, each one containing two Intel Xeon Haswell 8-core E5-2630 v3 processors, with a clock of 2.40 G Hz, interconnected through an InfiniBand network, equipped with 4x QDR switches.
EURETILE D7.3 - Dynamic DAL benchmark coding, measurements on MPI version of DPSNN-STDP (distributed plastic spiking neural net) and improvements to other DAL codes
Aug 20, 2014
The EURETILE project required the selection and coding of a set of dedicated benchmarks. The project is about the software and hardware architecture of future many-tile distributed fault-tolerant systems. We focus on dynamic workloads characterised by heavy numerical processing requirements. The ambition is to identify common techniques that could be applied to both the Embedded Systems and HPC domains. This document is the first public deliverable of Work Package 7: Challenging Tiled Applications.
EURETILE 2010-2012 summary: first three years of activity of the European Reference Tiled Experiment
May 07, 2013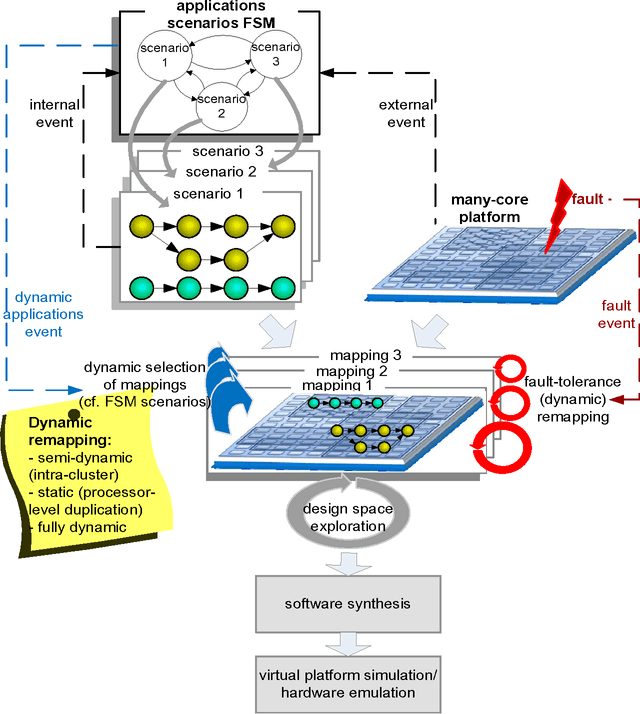
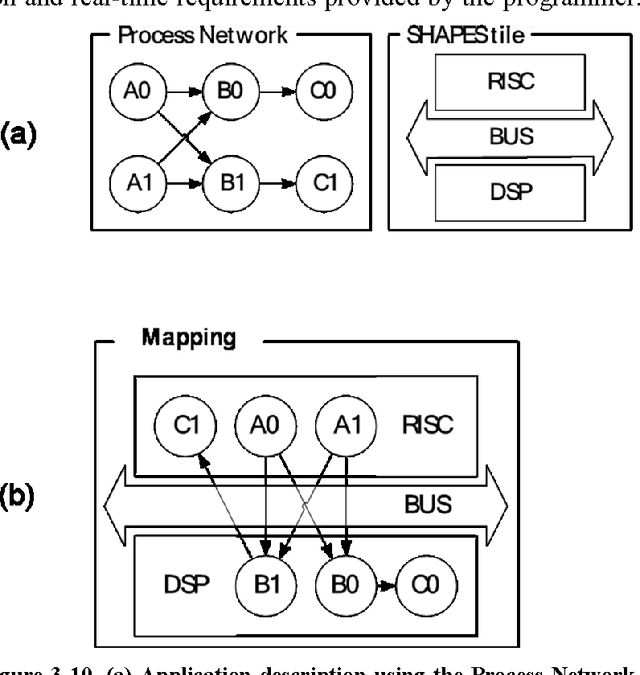
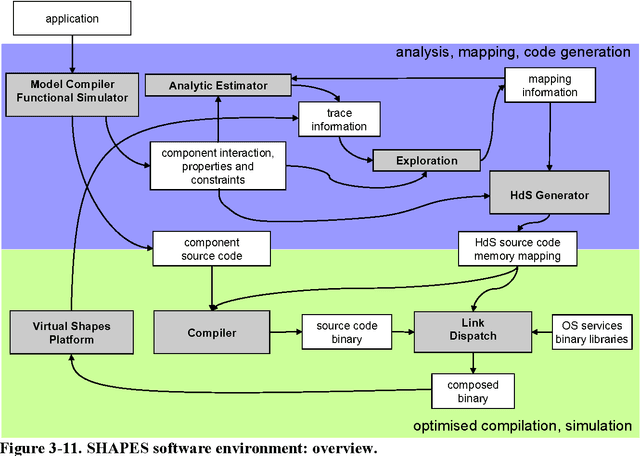
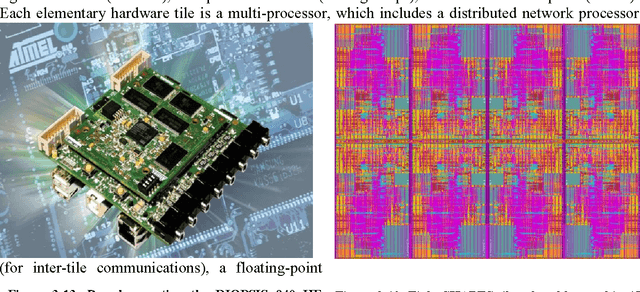
This is the summary of first three years of activity of the EURETILE FP7 project 247846. EURETILE investigates and implements brain-inspired and fault-tolerant foundational innovations to the system architecture of massively parallel tiled computer architectures and the corresponding programming paradigm. The execution targets are a many-tile HW platform, and a many-tile simulator. A set of SW process - HW tile mapping candidates is generated by the holistic SW tool-chain using a combination of analytic and bio-inspired methods. The Hardware dependent Software is then generated, providing OS services with maximum efficiency/minimal overhead. The many-tile simulator collects profiling data, closing the loop of the SW tool chain. Fine-grain parallelism inside processes is exploited by optimized intra-tile compilation techniques, but the project focus is above the level of the elementary tile. The elementary HW tile is a multi-processor, which includes a fault tolerant Distributed Network Processor (for inter-tile communication) and ASIP accelerators. Furthermore, EURETILE investigates and implements the innovations for equipping the elementary HW tile with high-bandwidth, low-latency brain-like inter-tile communication emulating 3 levels of connection hierarchy, namely neural columns, cortical areas and cortex, and develops a dedicated cortical simulation benchmark: DPSNN-STDP (Distributed Polychronous Spiking Neural Net with synaptic Spiking Time Dependent Plasticity). EURETILE leverages on the multi-tile HW paradigm and SW tool-chain developed by the FET-ACA SHAPES Integrated Project (2006-2009).