 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Tracking Transformers
Mar 24, 2022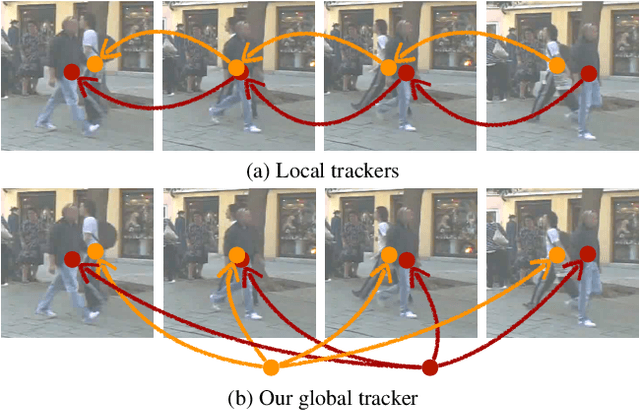
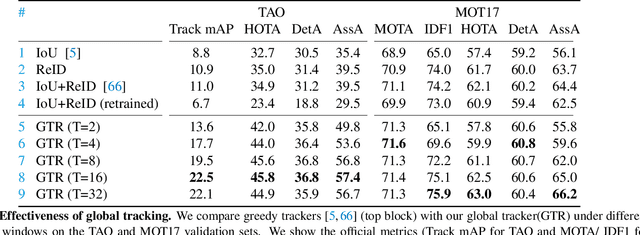
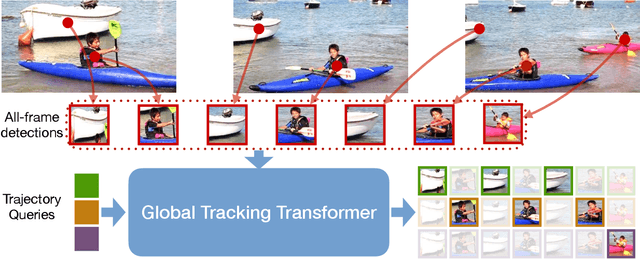
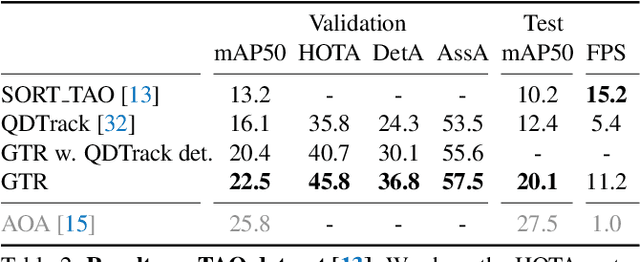
We present a novel transformer-based architecture for global multi-object tracking. Our network takes a short sequence of frames as input and produces global trajectories for all objects. The core component is a global tracking transformer that operates on objects from all frames in the sequence. The transformer encodes object features from all frames, and uses trajectory queries to group them into trajectories. The trajectory queries are object features from a single frame and naturally produce unique trajectories. Our global tracking transformer does not require intermediate pairwise grouping or combinatorial association, and can be jointly trained with an object detector. It achieves competitive performance on the popular MOT17 benchmark, with 75.3 MOTA and 59.1 HOTA. More importantly, our framework seamlessly integrates into state-of-the-art large-vocabulary detectors to track any objects. Experiments on the challenging TAO dataset show that our framework consistently improves upon baselines that are based on pairwise association, outperforming published works by a significant 7.7 tracking mAP. Code is available at https://github.com/xingyizhou/GTR.
Detecting Twenty-thousand Classes using Image-level Supervision
Jan 10, 2022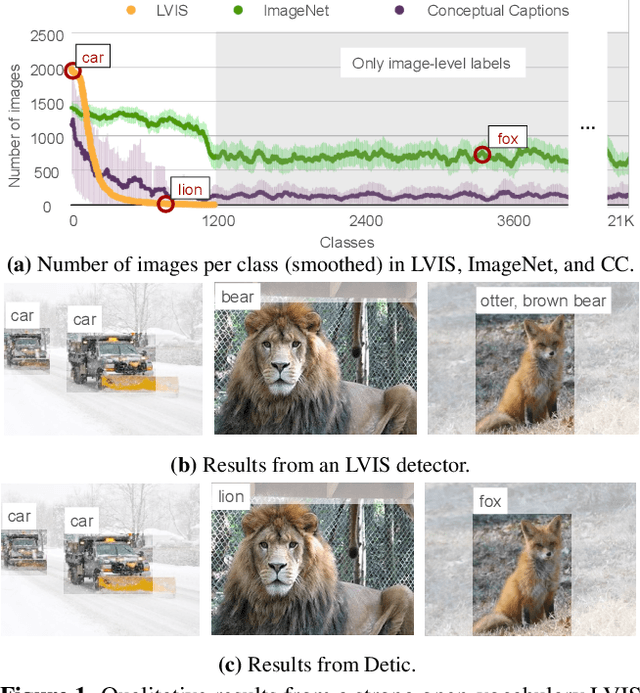
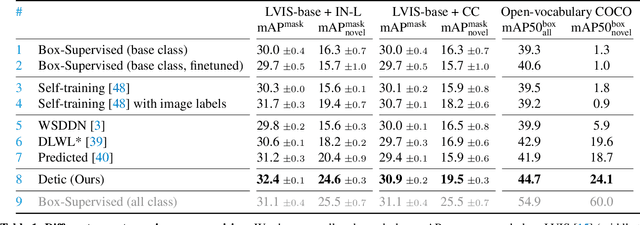


Current object detectors are limited in vocabulary size due to the small scale of detection datasets. Image classifiers, on the other hand, reason about much larger vocabularies, as their datasets are larger and easier to collect. We propose Detic, which simply trains the classifiers of a detector on image classification data and thus expands the vocabulary of detectors to tens of thousands of concepts. Unlike prior work, Detic does not assign image labels to boxes based on model predictions, making it much easier to implement and compatible with a range of detection architectures and backbones. Our results show that Detic yields excellent detectors even for classes without box annotations. It outperforms prior work on both open-vocabulary and long-tail detection benchmarks. Detic provides a gain of 2.4 mAP for all classes and 8.3 mAP for novel classes on the open-vocabulary LVIS benchmark. On the standard LVIS benchmark, Detic reaches 41.7 mAP for all classes and 41.7 mAP for rare classes. For the first time, we train a detector with all the twenty-one-thousand classes of the ImageNet dataset and show that it generalizes to new datasets without fine-tuning. Code is available at https://github.com/facebookresearch/Detic.