 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring the Redundancy of Decoder Layers in SpeechLLMs
Mar 05, 2026Speech Large Language Models route speech encoder representations into an LLM decoder that typically accounts for over 90% of total parameters. We study how much of this decoder capacity is actually needed for speech tasks. Across two LLM families and three scales (1-8B), we show that decoder redundancy is largely inherited from the pretrained LLM: text and speech inputs yield similar redundant blocks. We then measure excess capacity by pruning decoder layers and analysing post-pruning healing to increase robustness. Our findings show that 7-8B models retain good ASR performance with only 60% of decoder layers, and the same trend extends to smaller scales with reduced pruning tolerance. We then generalise to speech translation, and show that the same blocks of layers are redundant across speech encoders, tasks and languages, indicating that a more global redundancy structure exists, enabling a single pruned and multi-tasks SpeechLLM backbone to be deployed.
Conditional Diffusion Model for Target Speaker Extraction
Oct 07, 2023



We propose DiffSpEx, a generative target speaker extraction method based on score-based generative modelling through stochastic differential equations. DiffSpEx deploys a continuous-time stochastic diffusion process in the complex short-time Fourier transform domain, starting from the target speaker source and converging to a Gaussian distribution centred on the mixture of sources. For the reverse-time process, a parametrised score function is conditioned on a target speaker embedding to extract the target speaker from the mixture of sources. We utilise ECAPA-TDNN target speaker embeddings and condition the score function alternately on the SDE time embedding and the target speaker embedding. The potential of DiffSpEx is demonstrated with the WSJ0-2mix dataset, achieving an SI-SDR of 12.9 dB and a NISQA score of 3.56. Moreover, we show that fine-tuning a pre-trained DiffSpEx model to a specific speaker further improves performance, enabling personalisation in target speaker extraction.
Minimising Biasing Word Errors for Contextual ASR with the Tree-Constrained Pointer Generator
May 23, 2022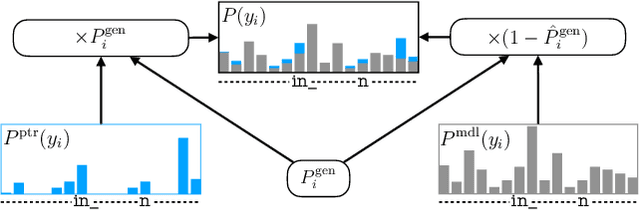
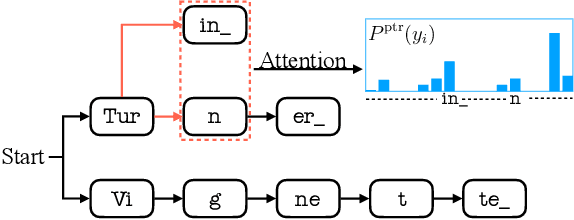


Contextual knowledge is essential for reducing speech recognition errors on high-valued long-tail words. This paper proposes a novel tree-constrained pointer generator (TCPGen) component that enables end-to-end ASR models to bias towards a list of long-tail words obtained using external contextual information. With only a small overhead in memory use and computation cost, TCPGen can structure thousands of biasing words efficiently into a symbolic prefix-tree and creates a neural shortcut between the tree and the final ASR output to facilitate the recognition of the biasing words. To enhance TCPGen, we further propose a novel minimum biasing word error (MBWE) loss that directly optimises biasing word errors during training, along with a biasing-word-driven language model discounting (BLMD) method during the test. All contextual ASR systems were evaluated on the public Librispeech audiobook corpus and the data from the dialogue state tracking challenges (DSTC) with the biasing lists extracted from the dialogue-system ontology. Consistent word error rate (WER) reductions were achieved with TCPGen, which were particularly significant on the biasing words with around 40\% relative reductions in the recognition error rates. MBWE and BLMD further improved the effectiveness of TCPGen and achieved more significant WER reductions on the biasing words. TCPGen also achieved zero-shot learning of words not in the audio training set with large WER reductions on the out-of-vocabulary words in the biasing list.
Very Deep Convolutional Neural Networks for Robust Speech Recognition
Oct 02, 2016

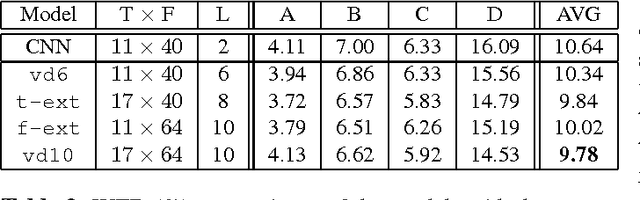
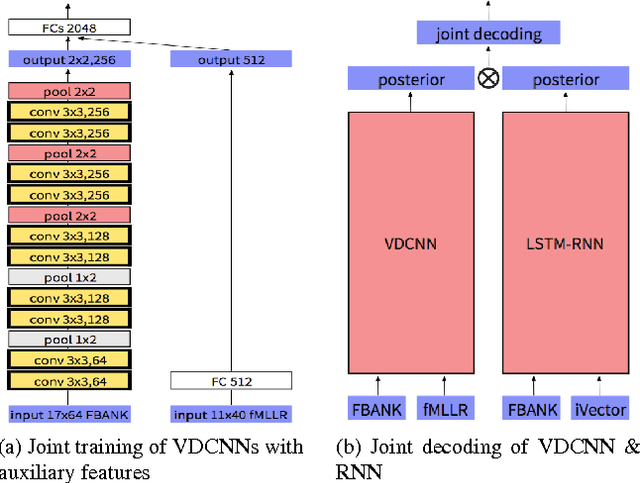
This paper describes the extension and optimization of our previous work on very deep convolutional neural networks (CNNs) for effective recognition of noisy speech in the Aurora 4 task. The appropriate number of convolutional layers, the sizes of the filters, pooling operations and input feature maps are all modified: the filter and pooling sizes are reduced and dimensions of input feature maps are extended to allow adding more convolutional layers. Furthermore appropriate input padding and input feature map selection strategies are developed. In addition, an adaptation framework using joint training of very deep CNN with auxiliary features i-vector and fMLLR features is developed. These modifications give substantial word error rate reductions over the standard CNN used as baseline. Finally the very deep CNN is combined with an LSTM-RNN acoustic model and it is shown that state-level weighted log likelihood score combination in a joint acoustic model decoding scheme is very effective. On the Aurora 4 task, the very deep CNN achieves a WER of 8.81%, further 7.99% with auxiliary feature joint training, and 7.09% with LSTM-RNN joint decoding.