 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVery Deep Convolutional Neural Networks for Robust Speech Recognition
Paper and Code
Oct 02, 2016

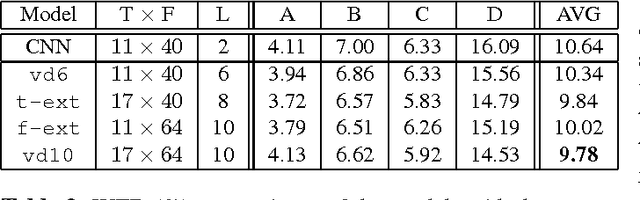
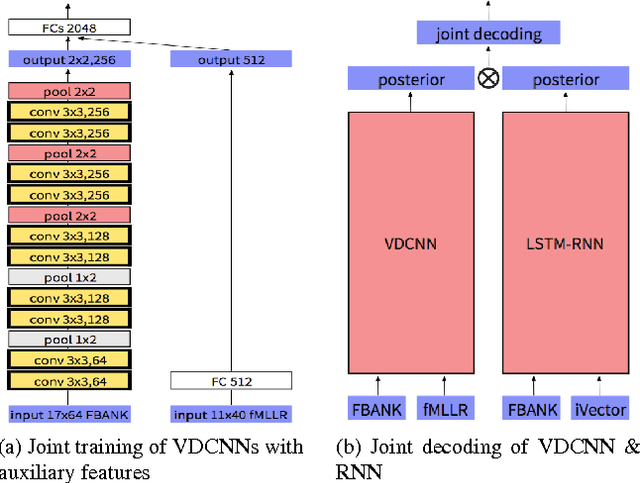
This paper describes the extension and optimization of our previous work on very deep convolutional neural networks (CNNs) for effective recognition of noisy speech in the Aurora 4 task. The appropriate number of convolutional layers, the sizes of the filters, pooling operations and input feature maps are all modified: the filter and pooling sizes are reduced and dimensions of input feature maps are extended to allow adding more convolutional layers. Furthermore appropriate input padding and input feature map selection strategies are developed. In addition, an adaptation framework using joint training of very deep CNN with auxiliary features i-vector and fMLLR features is developed. These modifications give substantial word error rate reductions over the standard CNN used as baseline. Finally the very deep CNN is combined with an LSTM-RNN acoustic model and it is shown that state-level weighted log likelihood score combination in a joint acoustic model decoding scheme is very effective. On the Aurora 4 task, the very deep CNN achieves a WER of 8.81%, further 7.99% with auxiliary feature joint training, and 7.09% with LSTM-RNN joint decoding.