 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging LLMs for Predictive Insights in Food Policy and Behavioral Interventions
Nov 13, 2024



Food consumption and production contribute significantly to global greenhouse gas emissions, making them crucial entry points for mitigating climate change and maintaining a liveable planet. Over the past two decades, food policy initiatives have explored interventions to reshape production and consumption patterns, focusing on reducing food waste and curbing ruminant meat consumption. While the evidence of "what works" improves, evaluating which policies are appropriate and effective in specific contexts remains difficult due to external validity challenges. This paper demonstrates that a fine-tuned large language model (LLM) can accurately predict the direction of outcomes in approximately 80\% of empirical studies measuring dietary-based impacts (e.g. food choices, sales, waste) resulting from behavioral interventions and policies. Approximately 75 prompts were required to achieve optimal results, with performance showing signs of catastrophic loss beyond this point. Our findings indicate that greater input detail enhances predictive accuracy, although the model still faces challenges with unseen studies, underscoring the importance of a representative training sample. As LLMs continue to improve and diversify, they hold promise for advancing data-driven, evidence-based policymaking.
Exploiting Phonological Similarities between African Languages to achieve Speech to Speech Translation
Oct 30, 2024



This paper presents a pilot study on direct speech-to-speech translation (S2ST) by leveraging linguistic similarities among selected African languages within the same phylum, particularly in cases where traditional data annotation is expensive or impractical. We propose a segment-based model that maps speech segments both within and across language phyla, effectively eliminating the need for large paired datasets. By utilizing paired segments and guided diffusion, our model enables translation between any two languages in the dataset. We evaluate the model on a proprietary dataset from the Kenya Broadcasting Corporation (KBC), which includes five languages: Swahili, Luo, Kikuyu, Nandi, and English. The model demonstrates competitive performance in segment pairing and translation quality, particularly for languages within the same phylum. Our experiments reveal that segment length significantly influences translation accuracy, with average-length segments yielding the highest pairing quality. Comparative analyses with traditional cascaded ASR-MT techniques show that the proposed model delivers nearly comparable translation performance. This study underscores the potential of exploiting linguistic similarities within language groups to perform efficient S2ST, especially in low-resource language contexts.
Speeding Up Speech Synthesis In Diffusion Models By Reducing Data Distribution Recovery Steps Via Content Transfer
Sep 18, 2023Diffusion based vocoders have been criticised for being slow due to the many steps required during sampling. Moreover, the model's loss function that is popularly implemented is designed such that the target is the original input $x_0$ or error $\epsilon_0$. For early time steps of the reverse process, this results in large prediction errors, which can lead to speech distortions and increase the learning time. We propose a setup where the targets are the different outputs of forward process time steps with a goal to reduce the magnitude of prediction errors and reduce the training time. We use the different layers of a neural network (NN) to perform denoising by training them to learn to generate representations similar to the noised outputs in the forward process of the diffusion. The NN layers learn to progressively denoise the input in the reverse process until finally the final layer estimates the clean speech. To avoid 1:1 mapping between layers of the neural network and the forward process steps, we define a skip parameter $\tau>1$ such that an NN layer is trained to cumulatively remove the noise injected in the $\tau$ steps in the forward process. This significantly reduces the number of data distribution recovery steps and, consequently, the time to generate speech. We show through extensive evaluation that the proposed technique generates high-fidelity speech in competitive time that outperforms current state-of-the-art tools. The proposed technique is also able to generalize well to unseen speech.
Are Large Language Models Fit For Guided Reading?
May 19, 2023This paper looks at the ability of large language models to participate in educational guided reading. We specifically, evaluate their ability to generate meaningful questions from the input text, generate diverse questions both in terms of content coverage and difficulty of the questions and evaluate their ability to recommend part of the text that a student should re-read based on the student's responses to the questions. Based on our evaluation of ChatGPT and Bard, we report that, 1) Large language models are able to generate high quality meaningful questions that have high correlation with the input text, 2) They generate diverse question that cover most topics in the input text even though this ability is significantly degraded as the input text increases, 3)The large language models are able to generate both low and high cognitive questions even though they are significantly biased toward low cognitive question, 4) They are able to effectively summarize responses and extract a portion of text that should be re-read.
Speech Separation based on Contrastive Learning and Deep Modularization
May 18, 2023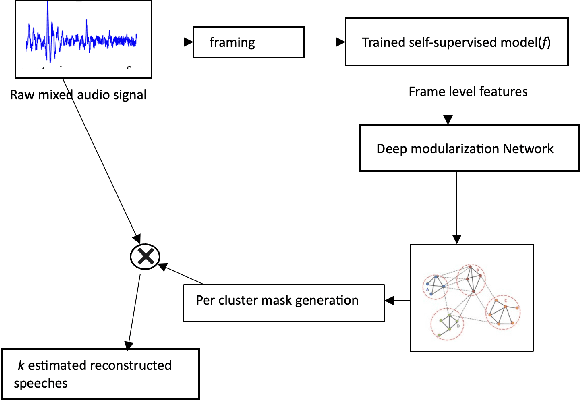
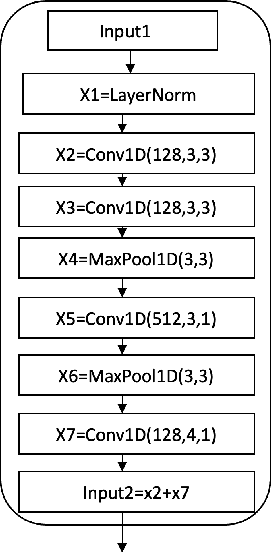
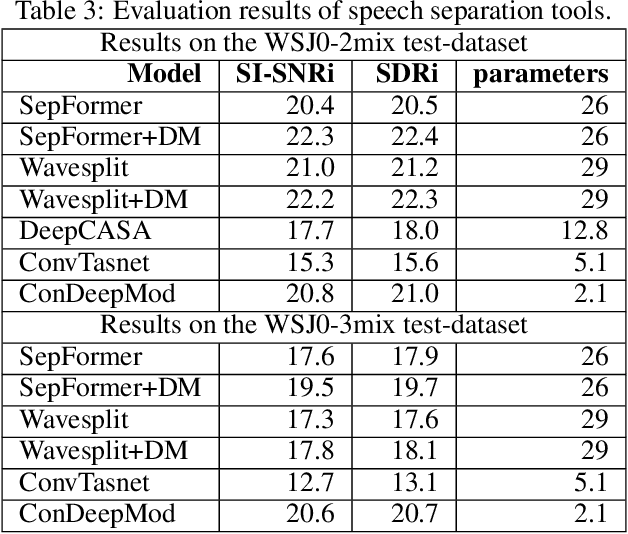
The current monaural state of the art tools for speech separation relies on supervised learning. This means that they must deal with permutation problem, they are impacted by the mismatch on the number of speakers used in training and inference. Moreover, their performance heavily relies on the presence of high-quality labelled data. These problems can be effectively addressed by employing a fully unsupervised technique for speech separation. In this paper, we use contrastive learning to establish the representations of frames then use the learned representations in the downstream deep modularization task. Concretely, we demonstrate experimentally that in speech separation, different frames of a speaker can be viewed as augmentations of a given hidden standard frame of that speaker. The frames of a speaker contain enough prosodic information overlap which is key in speech separation. Based on this, we implement a self-supervised learning to learn to minimize the distance between frames belonging to a given speaker. The learned representations are used in a downstream deep modularization task to cluster frames based on speaker identity. Evaluation of the developed technique on WSJ0-2mix and WSJ0-3mix shows that the technique attains SI-SNRi and SDRi of 20.8 and 21.0 respectively in WSJ0-2mix. In WSJ0-3mix, it attains SI-SNRi and SDRi of 20.7 and 20.7 respectively in WSJ0-2mix. Its greatest strength being that as the number of speakers increase, its performance does not degrade significantly.
Deep neural network techniques for monaural speech enhancement: state of the art analysis
Dec 01, 2022Deep neural networks (DNN) techniques have become pervasive in domains such as natural language processing and computer vision. They have achieved great success in these domains in task such as machine translation and image generation. Due to their success, these data driven techniques have been applied in audio domain. More specifically, DNN models have been applied in speech enhancement domain to achieve denosing, dereverberation and multi-speaker separation in monaural speech enhancement. In this paper, we review some dominant DNN techniques being employed to achieve speech separation. The review looks at the whole pipeline of speech enhancement from feature extraction, how DNN based tools are modelling both global and local features of speech and model training (supervised and unsupervised). We also review the use of speech-enhancement pre-trained models to boost speech enhancement process. The review is geared towards covering the dominant trends with regards to DNN application in speech enhancement in speech obtained via a single speaker.
Contrastive Environmental Sound Representation Learning
Jul 18, 2022
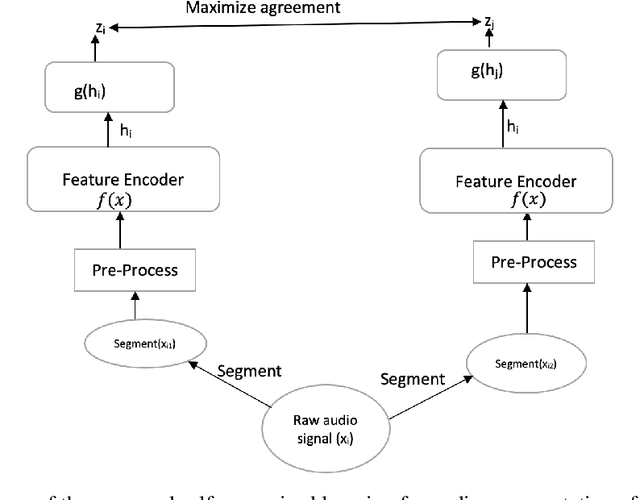
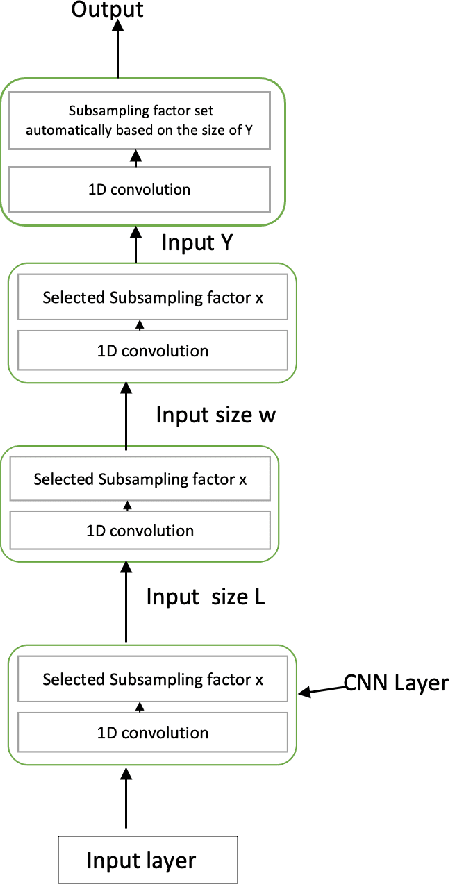
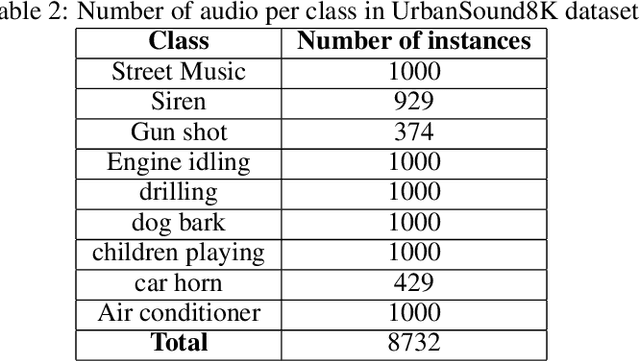
Machine hearing of the environmental sound is one of the important issues in the audio recognition domain. It gives the machine the ability to discriminate between the different input sounds that guides its decision making. In this work we exploit the self-supervised contrastive technique and a shallow 1D CNN to extract the distinctive audio features (audio representations) without using any explicit annotations.We generate representations of a given audio using both its raw audio waveform and spectrogram and evaluate if the proposed learner is agnostic to the type of audio input. We further use canonical correlation analysis (CCA) to fuse representations from the two types of input of a given audio and demonstrate that the fused global feature results in robust representation of the audio signal as compared to the individual representations. The evaluation of the proposed technique is done on both ESC-50 and UrbanSound8K. The results show that the proposed technique is able to extract most features of the environmental audio and gives an improvement of 12.8% and 0.9% on the ESC-50 and UrbanSound8K datasets respectively.
Unsupervised Technique To Conversational Machine Reading
Jun 29, 2021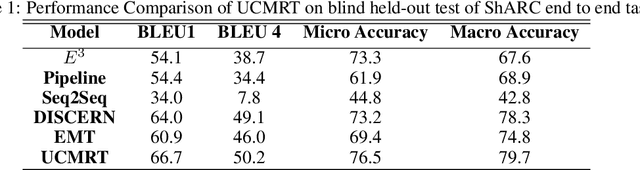

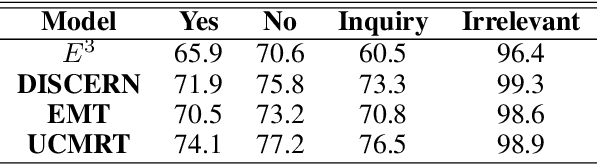
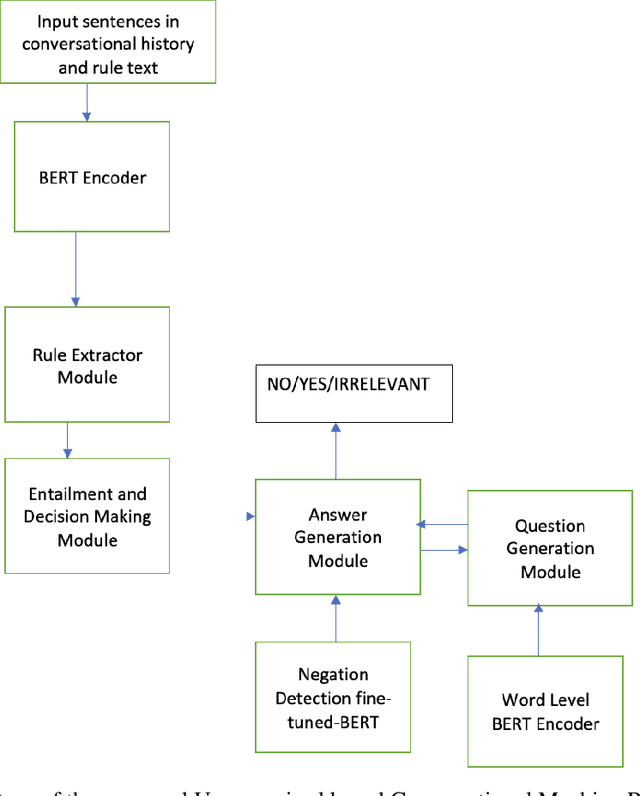
Conversational machine reading (CMR) tools have seen a rapid progress in the recent past. The current existing tools rely on the supervised learning technique which require labeled dataset for their training. The supervised technique necessitates that for every new rule text, a manually labeled dataset must be created. This is tedious and error prone. This paper introduces and demonstrates how unsupervised learning technique can be applied in the development of CMR. Specifically, we demonstrate how unsupervised learning can be used in rule extraction and entailment modules of CMR. Compared to the current best CMR tool, our developed framework reports 3.3% improvement in micro averaged accuracy and 1.4 % improvement in macro averaged accuracy.