 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreedy InfoMax for Biologically Plausible Self-Supervised Representation Learning
May 28, 2019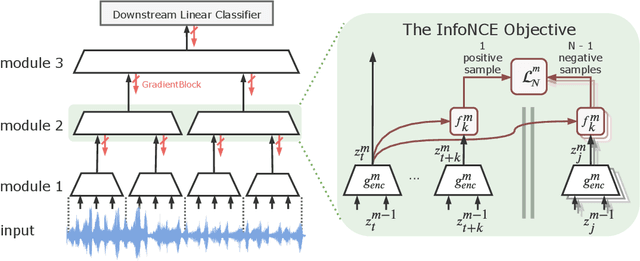
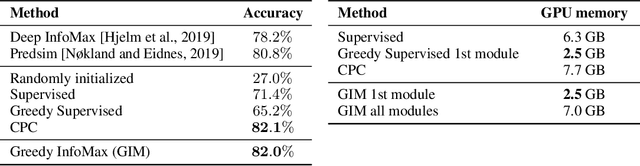

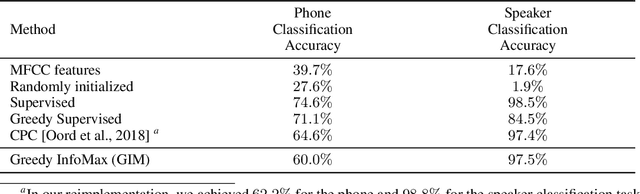
We propose a novel deep learning method for local self-supervised representation learning that does not require labels nor end-to-end backpropagation but exploits the natural order in data instead. Inspired by the observation that biological neural networks appear to learn without backpropagating a global error signal, we split a deep neural network into a stack of gradient-isolated modules. Each module is trained to maximize the mutual information between its consecutive outputs using the InfoNCE bound from Oord et al. [2018]. Despite this greedy training, we demonstrate that each module improves upon the output of its predecessor, and that the representations created by the top module yield highly competitive results on downstream classification tasks in the audio and visual domain. The proposal enables optimizing modules asynchronously, allowing large-scale distributed training of very deep neural networks on unlabelled datasets.
Learning a Representation Map for Robot Navigation using Deep Variational Autoencoder
Sep 13, 2018
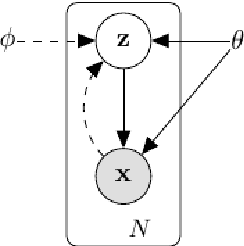

The aim of this work is to use Variational Autoencoder (VAE) to learn a representation of an indoor environment that can be used for robot navigation. We use images extracted from a video, in which a camera takes a tour around a house, for training the VAE model with a 4 dimensional latent space. After the model is trained, each real frame has a corresponding representation point on manifold in the latent space, and each representation point has corresponding reconstructed image. For the navigation problem, we map the starting image and destination image to the latent space, then optimize a path on the learned manifold connecting the two points, and finally map the path back through decoder to a sequence of images. The ideal sequence of images should correspond to a route that is spatially continuous - i.e. neighbor images in the route should correspond to neighbor locations in physical space. Such a route could be used for navigation with computer vision techniques, i.e. a robot could follow the image sequence from starting location to destination in the environment step by step. We implement this algorithm, but find in our experimental results that the resulting route is not satisfactory. The route consist of several discontinuous image frames along the ideal routes, so that the route could not be followed by a robot with computer vision techniques in practice. In our evaluation, we propose two reasons for our failure to automatically find continuous routes: (1) The VAE tends to capture global structures, but discard the details; (2) the Euclidean similarity metric used for measuring continuity between house images is sub-optimal. For further work, we propose: trying other generative models like VAE-GANs which may be better at reconstructing the details to learn the representation map, and adjusting the similarity metric in the path selecting algorithm.
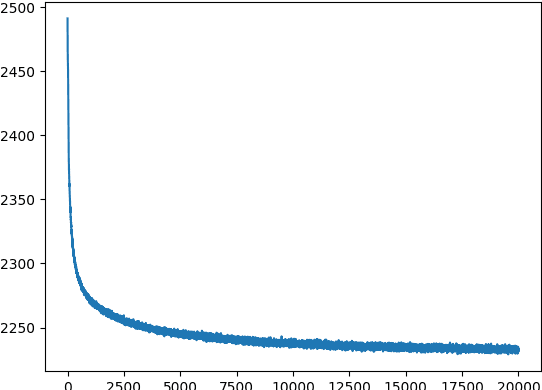
Temporally Efficient Deep Learning with Spikes
Jun 13, 2017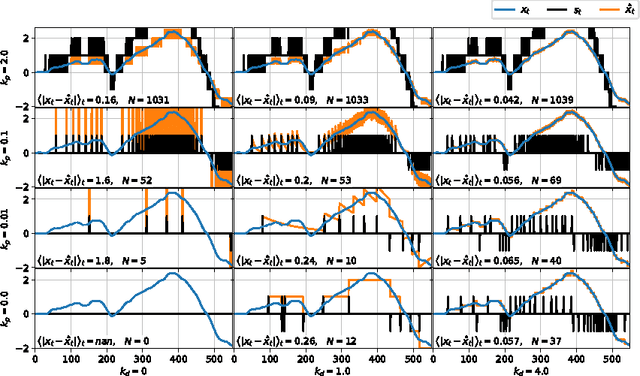
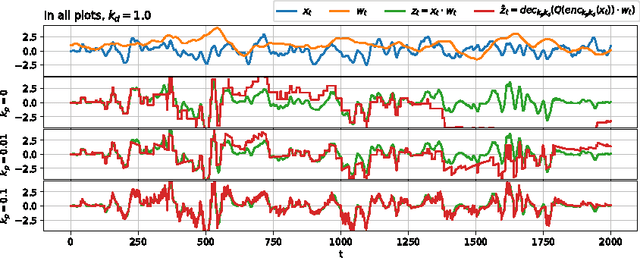
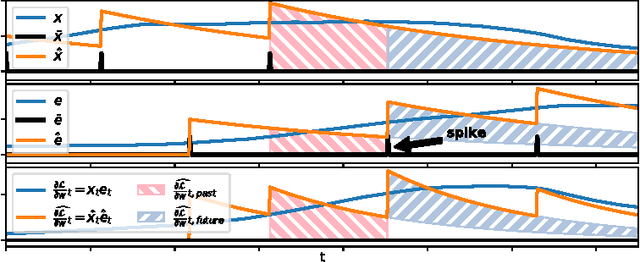
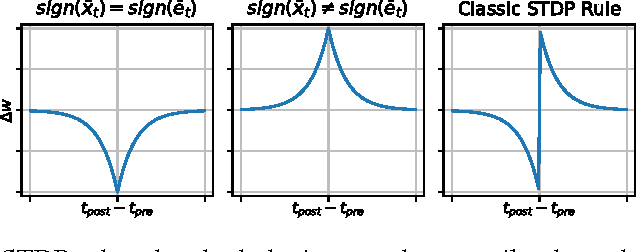
The vast majority of natural sensory data is temporally redundant. Video frames or audio samples which are sampled at nearby points in time tend to have similar values. Typically, deep learning algorithms take no advantage of this redundancy to reduce computation. This can be an obscene waste of energy. We present a variant on backpropagation for neural networks in which computation scales with the rate of change of the data - not the rate at which we process the data. We do this by having neurons communicate a combination of their state, and their temporal change in state. Intriguingly, this simple communication rule give rise to units that resemble biologically-inspired leaky integrate-and-fire neurons, and to a weight-update rule that is equivalent to a form of Spike-Timing Dependent Plasticity (STDP), a synaptic learning rule observed in the brain. We demonstrate that on MNIST and a temporal variant of MNIST, our algorithm performs about as well as a Multilayer Perceptron trained with backpropagation, despite only communicating discrete values between layers.
Sigma Delta Quantized Networks
Nov 10, 2016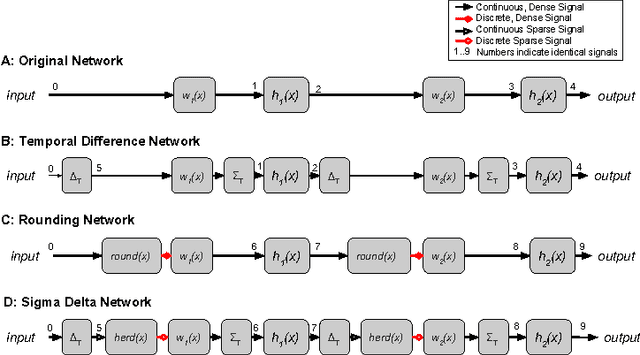
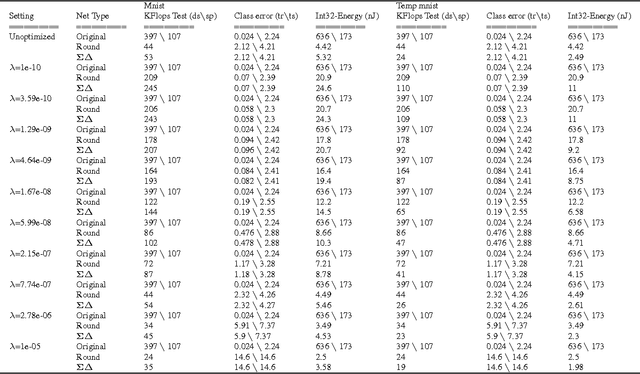
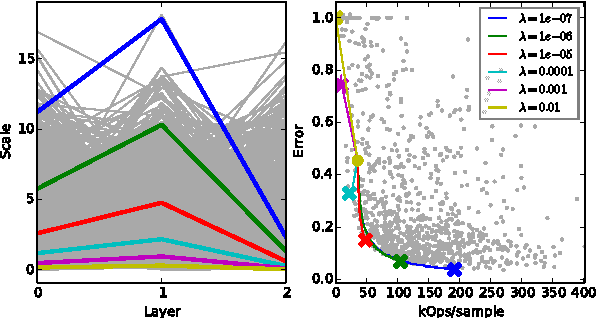

Deep neural networks can be obscenely wasteful. When processing video, a convolutional network expends a fixed amount of computation for each frame with no regard to the similarity between neighbouring frames. As a result, it ends up repeatedly doing very similar computations. To put an end to such waste, we introduce Sigma-Delta networks. With each new input, each layer in this network sends a discretized form of its change in activation to the next layer. Thus the amount of computation that the network does scales with the amount of change in the input and layer activations, rather than the size of the network. We introduce an optimization method for converting any pre-trained deep network into an optimally efficient Sigma-Delta network, and show that our algorithm, if run on the appropriate hardware, could cut at least an order of magnitude from the computational cost of processing video data.
Deep Spiking Networks
Nov 07, 2016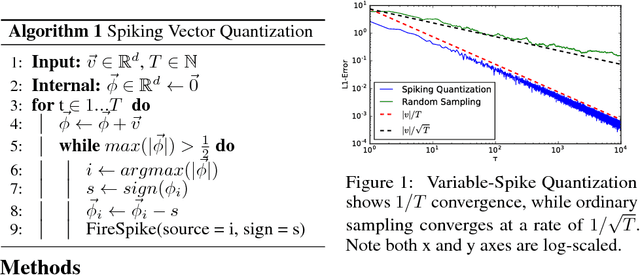
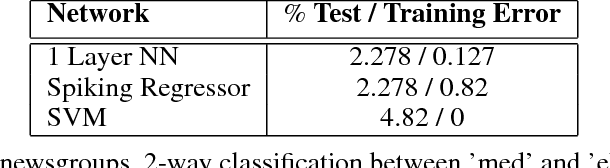
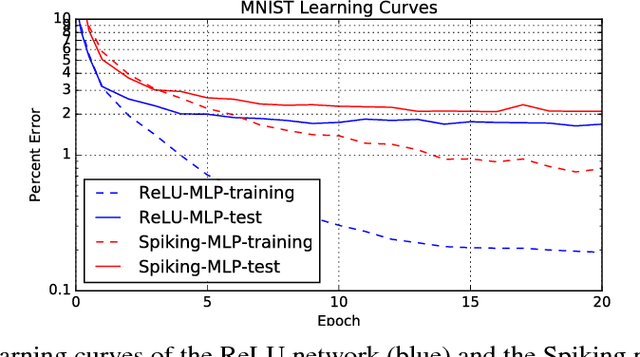
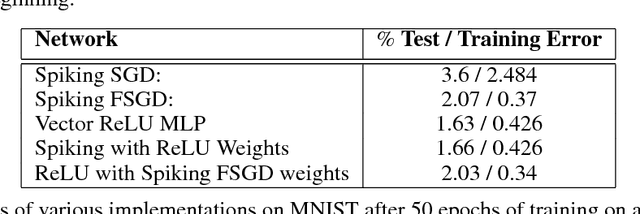
We introduce an algorithm to do backpropagation on a spiking network. Our network is "spiking" in the sense that our neurons accumulate their activation into a potential over time, and only send out a signal (a "spike") when this potential crosses a threshold and the neuron is reset. Neurons only update their states when receiving signals from other neurons. Total computation of the network thus scales with the number of spikes caused by an input rather than network size. We show that the spiking Multi-Layer Perceptron behaves identically, during both prediction and training, to a conventional deep network of rectified-linear units, in the limiting case where we run the spiking network for a long time. We apply this architecture to a conventional classification problem (MNIST) and achieve performance very close to that of a conventional Multi-Layer Perceptron with the same architecture. Our network is a natural architecture for learning based on streaming event-based data, and is a stepping stone towards using spiking neural networks to learn efficiently on streaming data.