 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning a Representation Map for Robot Navigation using Deep Variational Autoencoder
Sep 13, 2018
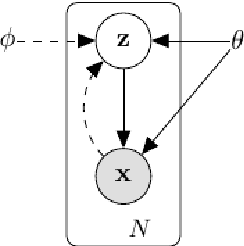

The aim of this work is to use Variational Autoencoder (VAE) to learn a representation of an indoor environment that can be used for robot navigation. We use images extracted from a video, in which a camera takes a tour around a house, for training the VAE model with a 4 dimensional latent space. After the model is trained, each real frame has a corresponding representation point on manifold in the latent space, and each representation point has corresponding reconstructed image. For the navigation problem, we map the starting image and destination image to the latent space, then optimize a path on the learned manifold connecting the two points, and finally map the path back through decoder to a sequence of images. The ideal sequence of images should correspond to a route that is spatially continuous - i.e. neighbor images in the route should correspond to neighbor locations in physical space. Such a route could be used for navigation with computer vision techniques, i.e. a robot could follow the image sequence from starting location to destination in the environment step by step. We implement this algorithm, but find in our experimental results that the resulting route is not satisfactory. The route consist of several discontinuous image frames along the ideal routes, so that the route could not be followed by a robot with computer vision techniques in practice. In our evaluation, we propose two reasons for our failure to automatically find continuous routes: (1) The VAE tends to capture global structures, but discard the details; (2) the Euclidean similarity metric used for measuring continuity between house images is sub-optimal. For further work, we propose: trying other generative models like VAE-GANs which may be better at reconstructing the details to learn the representation map, and adjusting the similarity metric in the path selecting algorithm.