 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Deep Ensemble Method for Real-world Image Denoising
Jun 08, 2022

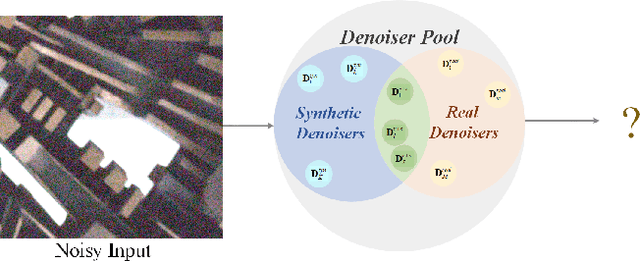
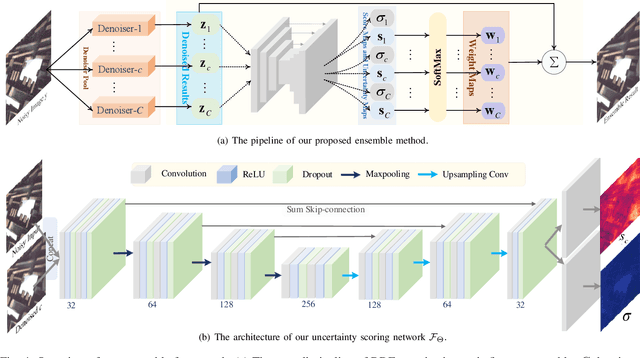
Recently, deep learning-based image denoising methods have achieved promising performance on test data with the same distribution as training set, where various denoising models based on synthetic or collected real-world training data have been learned. However, when handling real-world noisy images, the denoising performance is still limited. In this paper, we propose a simple yet effective Bayesian deep ensemble (BDE) method for real-world image denoising, where several representative deep denoisers pre-trained with various training data settings can be fused to improve robustness. The foundation of BDE is that real-world image noises are highly signal-dependent, and heterogeneous noises in a real-world noisy image can be separately handled by different denoisers. In particular, we take well-trained CBDNet, NBNet, HINet, Uformer and GMSNet into denoiser pool, and a U-Net is adopted to predict pixel-wise weighting maps to fuse these denoisers. Instead of solely learning pixel-wise weighting maps, Bayesian deep learning strategy is introduced to predict weighting uncertainty as well as weighting map, by which prediction variance can be modeled for improving robustness on real-world noisy images. Extensive experiments have shown that real-world noises can be better removed by fusing existing denoisers instead of training a big denoiser with expensive cost. On DND dataset, our BDE achieves +0.28~dB PSNR gain over the state-of-the-art denoising method. Moreover, we note that our BDE denoiser based on different Gaussian noise levels outperforms state-of-the-art CBDNet when applying to real-world noisy images. Furthermore, our BDE can be extended to other image restoration tasks, and achieves +0.30dB, +0.18dB and +0.12dB PSNR gains on benchmark datasets for image deblurring, image deraining and single image super-resolution, respectively.
Multi-level Wavelet Convolutional Neural Networks
Jul 06, 2019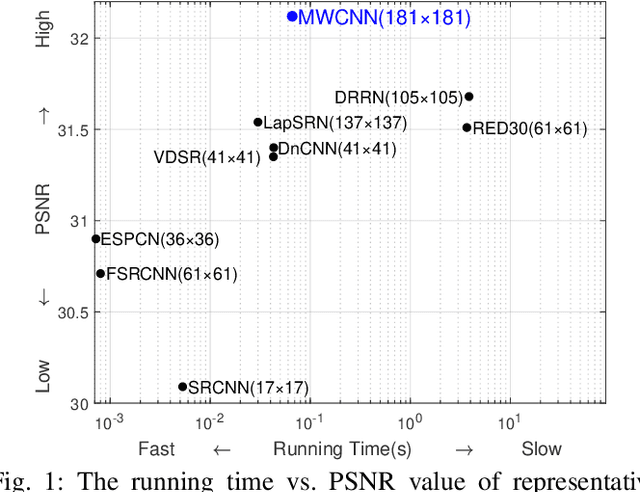
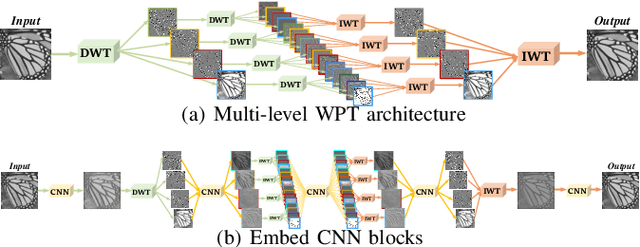
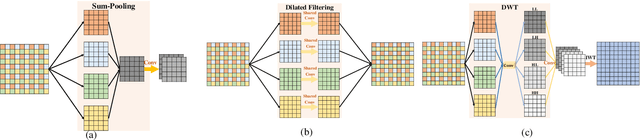
In computer vision, convolutional networks (CNNs) often adopts pooling to enlarge receptive field which has the advantage of low computational complexity. However, pooling can cause information loss and thus is detrimental to further operations such as features extraction and analysis. Recently, dilated filter has been proposed to trade off between receptive field size and efficiency. But the accompanying gridding effect can cause a sparse sampling of input images with checkerboard patterns. To address this problem, in this paper, we propose a novel multi-level wavelet CNN (MWCNN) model to achieve better trade-off between receptive field size and computational efficiency. The core idea is to embed wavelet transform into CNN architecture to reduce the resolution of feature maps while at the same time, increasing receptive field. Specifically, MWCNN for image restoration is based on U-Net architecture, and inverse wavelet transform (IWT) is deployed to reconstruct the high resolution (HR) feature maps. The proposed MWCNN can also be viewed as an improvement of dilated filter and a generalization of average pooling, and can be applied to not only image restoration tasks, but also any CNNs requiring a pooling operation. The experimental results demonstrate effectiveness of the proposed MWCNN for tasks such as image denoising, single image super-resolution, JPEG image artifacts removal and object classification.
Multi-level Wavelet-CNN for Image Restoration
May 22, 2018
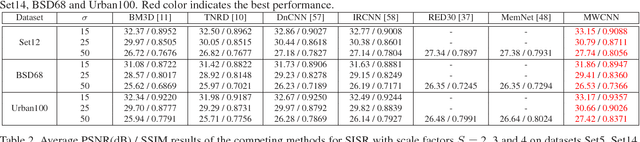
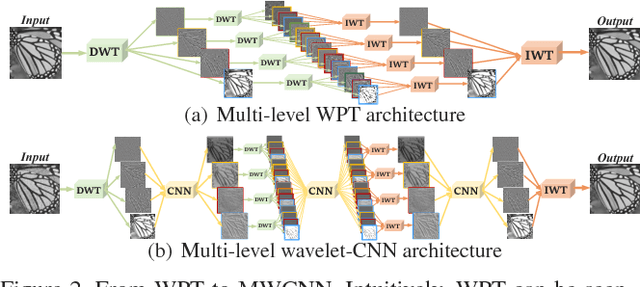
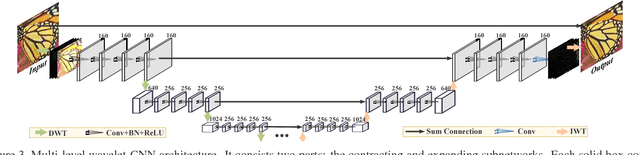
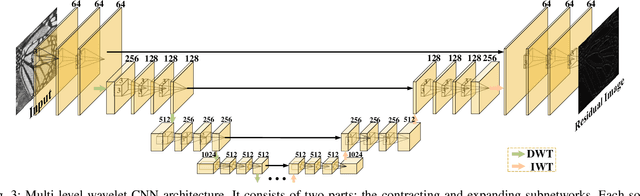
The tradeoff between receptive field size and efficiency is a crucial issue in low level vision. Plain convolutional networks (CNNs) generally enlarge the receptive field at the expense of computational cost. Recently, dilated filtering has been adopted to address this issue. But it suffers from gridding effect, and the resulting receptive field is only a sparse sampling of input image with checkerboard patterns. In this paper, we present a novel multi-level wavelet CNN (MWCNN) model for better tradeoff between receptive field size and computational efficiency. With the modified U-Net architecture, wavelet transform is introduced to reduce the size of feature maps in the contracting subnetwork. Furthermore, another convolutional layer is further used to decrease the channels of feature maps. In the expanding subnetwork, inverse wavelet transform is then deployed to reconstruct the high resolution feature maps. Our MWCNN can also be explained as the generalization of dilated filtering and subsampling, and can be applied to many image restoration tasks. The experimental results clearly show the effectiveness of MWCNN for image denoising, single image super-resolution, and JPEG image artifacts removal.