 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX2C: A Dataset Featuring Nuanced Facial Expressions for Realistic Humanoid Imitation
May 16, 2025The ability to imitate realistic facial expressions is essential for humanoid robots engaged in affective human-robot communication. However, the lack of datasets containing diverse humanoid facial expressions with proper annotations hinders progress in realistic humanoid facial expression imitation. To address these challenges, we introduce X2C (Anything to Control), a dataset featuring nuanced facial expressions for realistic humanoid imitation. With X2C, we contribute: 1) a high-quality, high-diversity, large-scale dataset comprising 100,000 (image, control value) pairs. Each image depicts a humanoid robot displaying a diverse range of facial expressions, annotated with 30 control values representing the ground-truth expression configuration; 2) X2CNet, a novel human-to-humanoid facial expression imitation framework that learns the correspondence between nuanced humanoid expressions and their underlying control values from X2C. It enables facial expression imitation in the wild for different human performers, providing a baseline for the imitation task, showcasing the potential value of our dataset; 3) real-world demonstrations on a physical humanoid robot, highlighting its capability to advance realistic humanoid facial expression imitation. Code and Data: https://lipzh5.github.io/X2CNet/
UGotMe: An Embodied System for Affective Human-Robot Interaction
Oct 24, 2024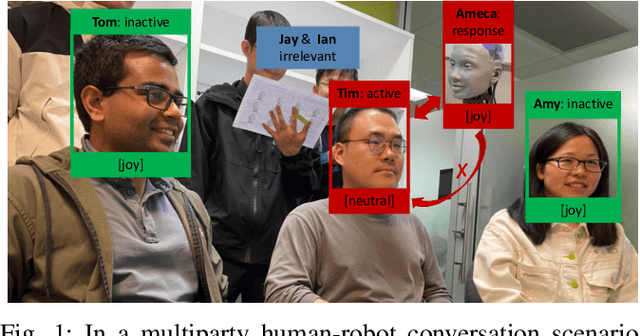



Equipping humanoid robots with the capability to understand emotional states of human interactants and express emotions appropriately according to situations is essential for affective human-robot interaction. However, enabling current vision-aware multimodal emotion recognition models for affective human-robot interaction in the real-world raises embodiment challenges: addressing the environmental noise issue and meeting real-time requirements. First, in multiparty conversation scenarios, the noises inherited in the visual observation of the robot, which may come from either 1) distracting objects in the scene or 2) inactive speakers appearing in the field of view of the robot, hinder the models from extracting emotional cues from vision inputs. Secondly, realtime response, a desired feature for an interactive system, is also challenging to achieve. To tackle both challenges, we introduce an affective human-robot interaction system called UGotMe designed specifically for multiparty conversations. Two denoising strategies are proposed and incorporated into the system to solve the first issue. Specifically, to filter out distracting objects in the scene, we propose extracting face images of the speakers from the raw images and introduce a customized active face extraction strategy to rule out inactive speakers. As for the second issue, we employ efficient data transmission from the robot to the local server to improve realtime response capability. We deploy UGotMe on a human robot named Ameca to validate its real-time inference capabilities in practical scenarios. Videos demonstrating real-world deployment are available at https://pi3-141592653.github.io/UGotMe/.