 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Information Transfer for Pre-Ranking Systems
Jul 07, 2022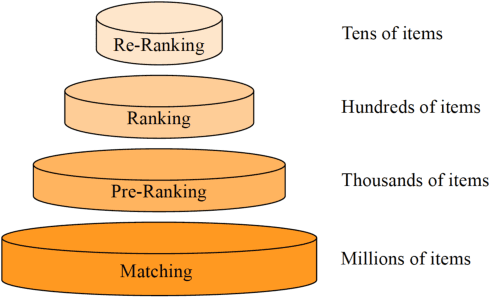
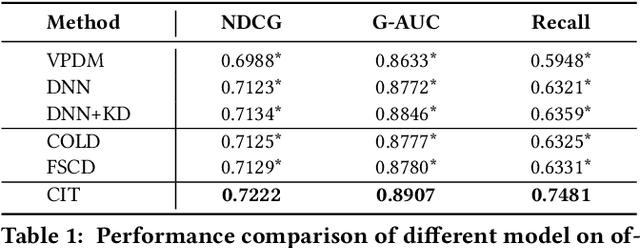
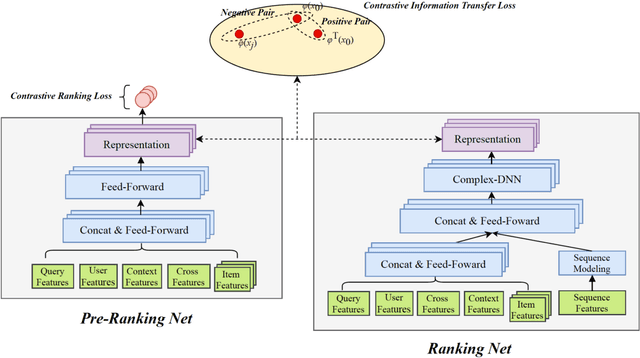
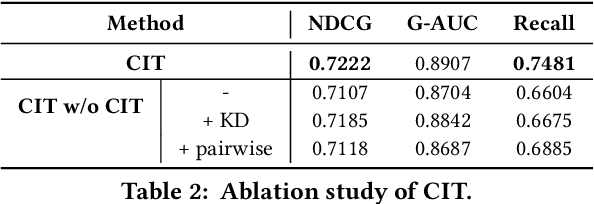
Real-word search and recommender systems usually adopt a multi-stage ranking architecture, including matching, pre-ranking, ranking, and re-ranking. Previous works mainly focus on the ranking stage while very few focus on the pre-ranking stage. In this paper, we focus on the information transfer from ranking to pre-ranking stage. We propose a new Contrastive Information Transfer (CIT) framework to transfer useful information from ranking model to pre-ranking model. We train the pre-ranking model to distinguish the positive pair of representation from a set of positive and negative pairs with a contrastive objective. As a consequence, the pre-ranking model can make full use of rich information in ranking model's representations. The CIT framework also has the advantage of alleviating selection bias and improving the performance of recall metrics, which is crucial for pre-ranking models. We conduct extensive experiments including offline datasets and online A/B testing. Experimental results show that CIT achieves superior results than competitive models. In addition, a strict online A/B testing at one of the world's largest E-commercial platforms shows that the proposed model achieves 0.63\% improvements on CTR and 1.64\% improvements on VBR. The proposed model now has been deployed online and serves the main traffic of this system, contributing a remarkable business growth.
Sampling Is All You Need on Modeling Long-Term User Behaviors for CTR Prediction
May 20, 2022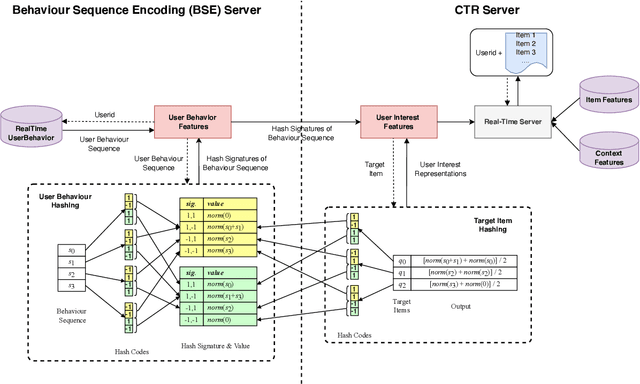

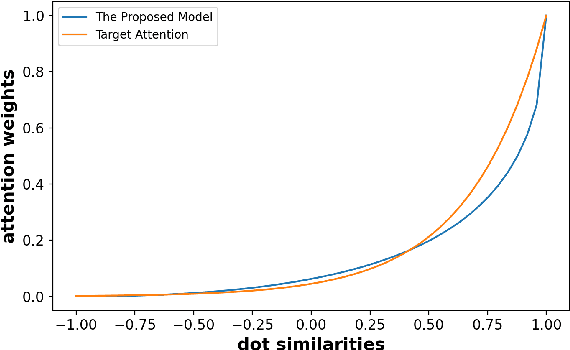
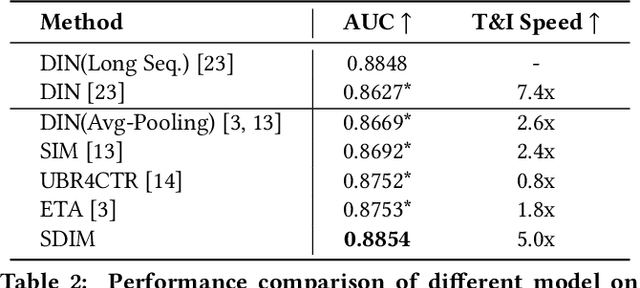
Rich user behavior data has been proven to be of great value for Click-Through Rate (CTR) prediction applications, especially in industrial recommender, search, or advertising systems. However, it's non-trivial for real-world systems to make full use of long-term user behaviors due to the strict requirements of online serving time. Most previous works adopt the retrieval-based strategy, where a small number of user behaviors are retrieved first for subsequent attention. However, the retrieval-based methods are sub-optimal and would cause more or less information losses, and it's difficult to balance the effectiveness and efficiency of the retrieval algorithm. In this paper, we propose \textbf{SDIM} (\textbf{S}ampling-based \textbf{D}eep \textbf{I}nterest \textbf{M}odeling), a simple yet effective sampling-based end-to-end approach for modeling long-term user behaviors. We sample from multiple hash functions to generate hash signatures of the candidate item and each item in the user behavior sequence, and obtain the user interest by directly gathering behavior items associated with the candidate item with the same hash signature. We show theoretically and experimentally that the proposed method performs on par with standard attention-based models on modeling long-term user behaviors, while being sizable times faster. We also introduce the deployment of SDIM in our system. Specifically, we decouple the behavior sequence hashing, which is the most time-consuming part, from the CTR model by designing a separate module named BSE (behavior Sequence Encoding). BSE is latency-free for the CTR server, enabling us to model extremely long user behaviors. Both offline and online experiments are conducted to demonstrate the effectiveness of SDIM. SDIM now has been deployed online in the search system of Meituan APP.
AutoFAS: Automatic Feature and Architecture Selection for Pre-Ranking System
May 19, 2022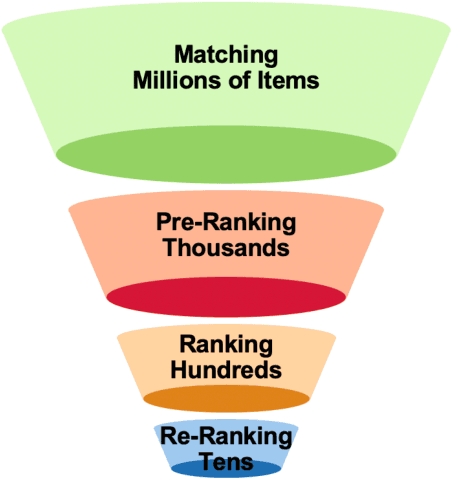

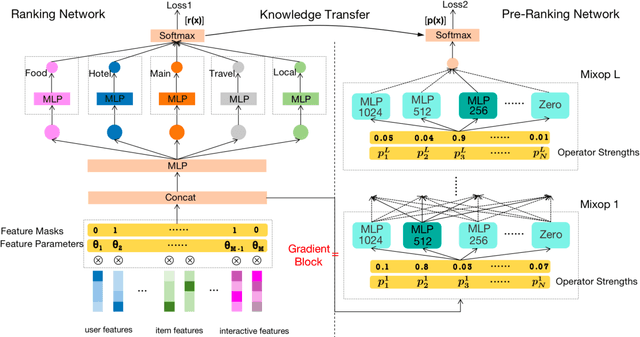

Industrial search and recommendation systems mostly follow the classic multi-stage information retrieval paradigm: matching, pre-ranking, ranking, and re-ranking stages. To account for system efficiency, simple vector-product based models are commonly deployed in the pre-ranking stage. Recent works consider distilling the high knowledge of large ranking models to small pre-ranking models for better effectiveness. However, two major challenges in pre-ranking system still exist: (i) without explicitly modeling the performance gain versus computation cost, the predefined latency constraint in the pre-ranking stage inevitably leads to suboptimal solutions; (ii) transferring the ranking teacher's knowledge to a pre-ranking student with a predetermined handcrafted architecture still suffers from the loss of model performance. In this work, a novel framework AutoFAS is proposed which jointly optimizes the efficiency and effectiveness of the pre-ranking model: (i) AutoFAS for the first time simultaneously selects the most valuable features and network architectures using Neural Architecture Search (NAS) technique; (ii) equipped with ranking model guided reward during NAS procedure, AutoFAS can select the best pre-ranking architecture for a given ranking teacher without any computation overhead. Experimental results in our real world search system show AutoFAS consistently outperforms the previous state-of-the-art (SOTA) approaches at a lower computing cost. Notably, our model has been adopted in the pre-ranking module in the search system of Meituan, bringing significant improvements.