 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn The Utility of Conditional Generation Based Mutual Information for Characterizing Adversarial Subspaces
Sep 24, 2018


Recent studies have found that deep learning systems are vulnerable to adversarial examples; e.g., visually unrecognizable adversarial images can easily be crafted to result in misclassification. The robustness of neural networks has been studied extensively in the context of adversary detection, which compares a metric that exhibits strong discriminate power between natural and adversarial examples. In this paper, we propose to characterize the adversarial subspaces through the lens of mutual information (MI) approximated by conditional generation methods. We use MI as an information-theoretic metric to strengthen existing defenses and improve the performance of adversary detection. Experimental results on MagNet defense demonstrate that our proposed MI detector can strengthen its robustness against powerful adversarial attacks.
On the Limitation of MagNet Defense against $L_1$-based Adversarial Examples
May 09, 2018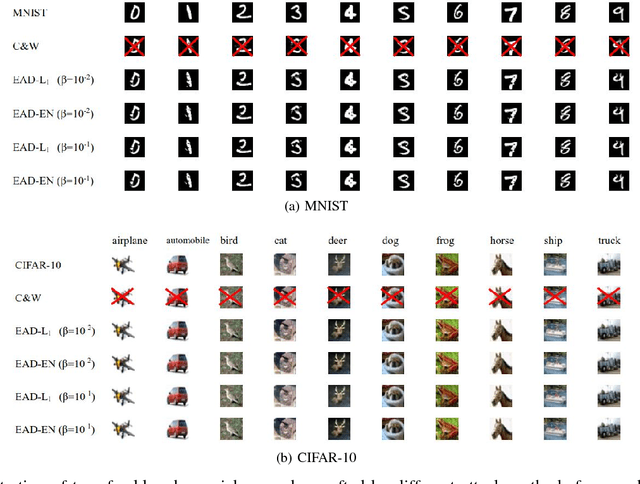
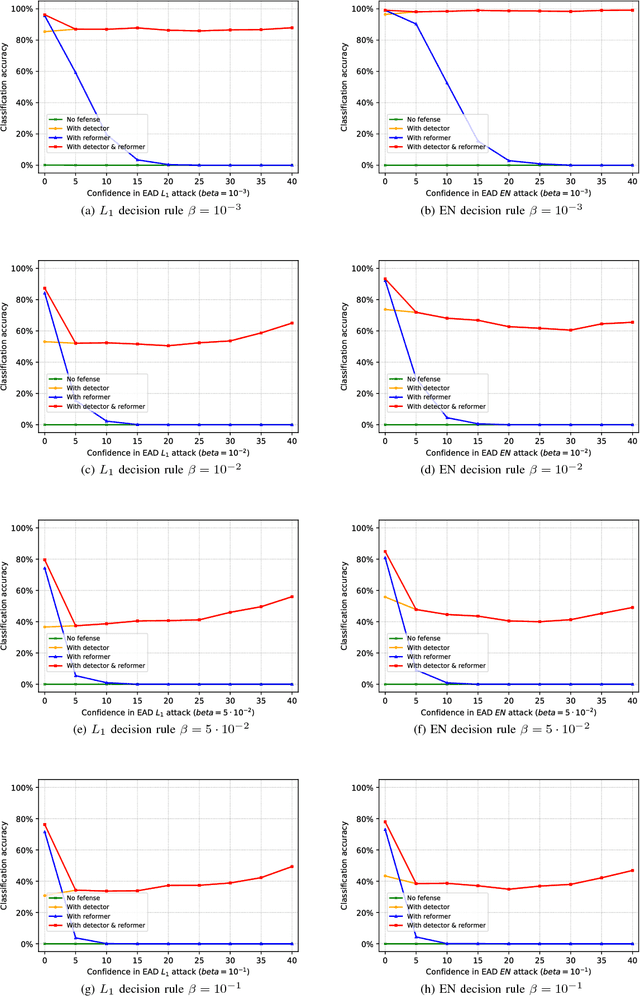
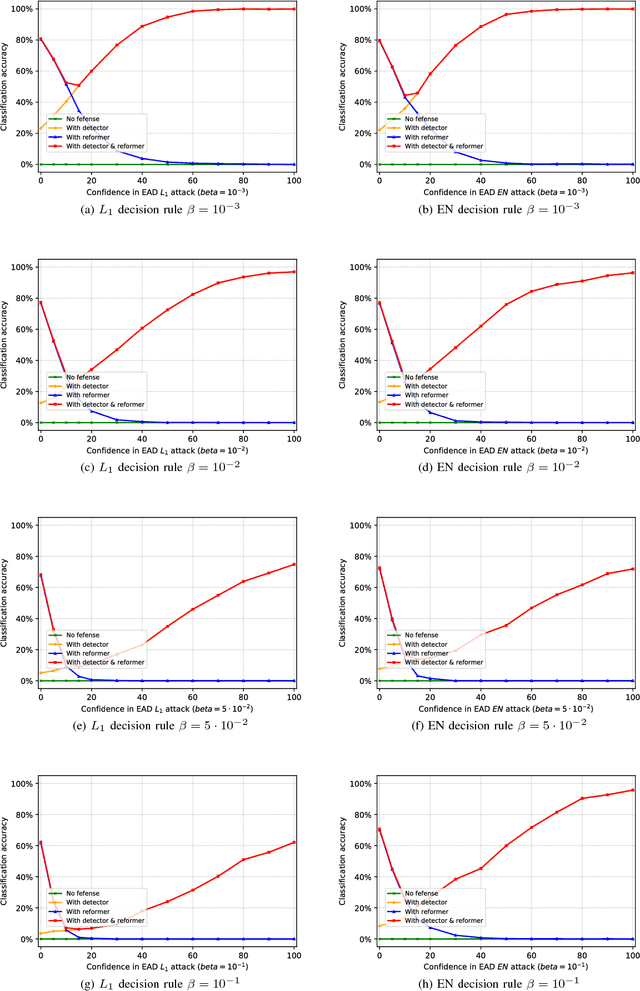

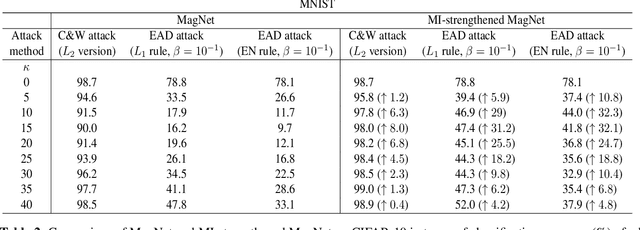
In recent years, defending adversarial perturbations to natural examples in order to build robust machine learning models trained by deep neural networks (DNNs) has become an emerging research field in the conjunction of deep learning and security. In particular, MagNet consisting of an adversary detector and a data reformer is by far one of the strongest defenses in the black-box oblivious attack setting, where the attacker aims to craft transferable adversarial examples from an undefended DNN model to bypass an unknown defense module deployed on the same DNN model. Under this setting, MagNet can successfully defend a variety of attacks in DNNs, including the high-confidence adversarial examples generated by the Carlini and Wagner's attack based on the $L_2$ distortion metric. However, in this paper, under the same attack setting we show that adversarial examples crafted based on the $L_1$ distortion metric can easily bypass MagNet and mislead the target DNN image classifiers on MNIST and CIFAR-10. We also provide explanations on why the considered approach can yield adversarial examples with superior attack performance and conduct extensive experiments on variants of MagNet to verify its lack of robustness to $L_1$ distortion based attacks. Notably, our results substantially weaken the assumption of effective threat models on MagNet that require knowing the deployed defense technique when attacking DNNs (i.e., the gray-box attack setting).
On the Limitation of Local Intrinsic Dimensionality for Characterizing the Subspaces of Adversarial Examples
Mar 26, 2018
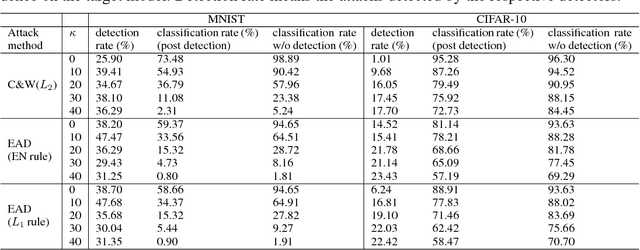
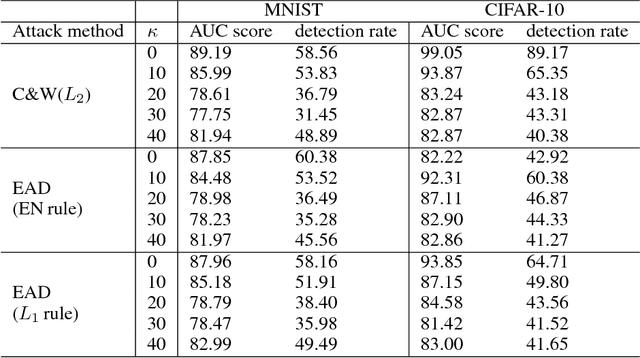

Understanding and characterizing the subspaces of adversarial examples aid in studying the robustness of deep neural networks (DNNs) to adversarial perturbations. Very recently, Ma et al. (ICLR 2018) proposed to use local intrinsic dimensionality (LID) in layer-wise hidden representations of DNNs to study adversarial subspaces. It was demonstrated that LID can be used to characterize the adversarial subspaces associated with different attack methods, e.g., the Carlini and Wagner's (C&W) attack and the fast gradient sign attack. In this paper, we use MNIST and CIFAR-10 to conduct two new sets of experiments that are absent in existing LID analysis and report the limitation of LID in characterizing the corresponding adversarial subspaces, which are (i) oblivious attacks and LID analysis using adversarial examples with different confidence levels; and (ii) black-box transfer attacks. For (i), we find that the performance of LID is very sensitive to the confidence parameter deployed by an attack, and the LID learned from ensembles of adversarial examples with varying confidence levels surprisingly gives poor performance. For (ii), we find that when adversarial examples are crafted from another DNN model, LID is ineffective in characterizing their adversarial subspaces. These two findings together suggest the limited capability of LID in characterizing the subspaces of adversarial examples.