 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Limitation of Local Intrinsic Dimensionality for Characterizing the Subspaces of Adversarial Examples
Paper and Code

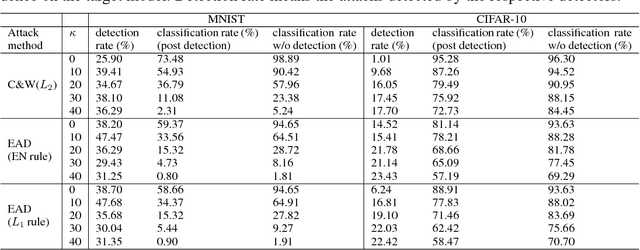
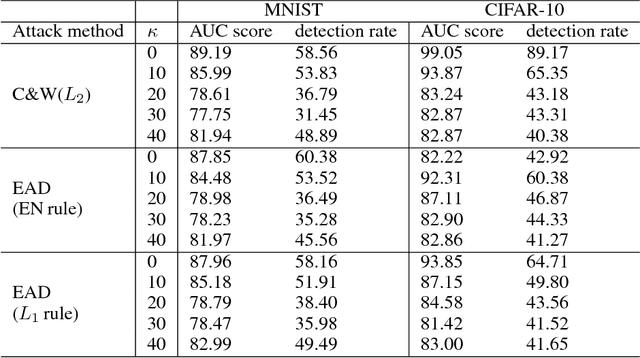

Understanding and characterizing the subspaces of adversarial examples aid in studying the robustness of deep neural networks (DNNs) to adversarial perturbations. Very recently, Ma et al. (ICLR 2018) proposed to use local intrinsic dimensionality (LID) in layer-wise hidden representations of DNNs to study adversarial subspaces. It was demonstrated that LID can be used to characterize the adversarial subspaces associated with different attack methods, e.g., the Carlini and Wagner's (C&W) attack and the fast gradient sign attack. In this paper, we use MNIST and CIFAR-10 to conduct two new sets of experiments that are absent in existing LID analysis and report the limitation of LID in characterizing the corresponding adversarial subspaces, which are (i) oblivious attacks and LID analysis using adversarial examples with different confidence levels; and (ii) black-box transfer attacks. For (i), we find that the performance of LID is very sensitive to the confidence parameter deployed by an attack, and the LID learned from ensembles of adversarial examples with varying confidence levels surprisingly gives poor performance. For (ii), we find that when adversarial examples are crafted from another DNN model, LID is ineffective in characterizing their adversarial subspaces. These two findings together suggest the limited capability of LID in characterizing the subspaces of adversarial examples.