 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbability Calibration for Knowledge Graph Embedding Models
Feb 13, 2020
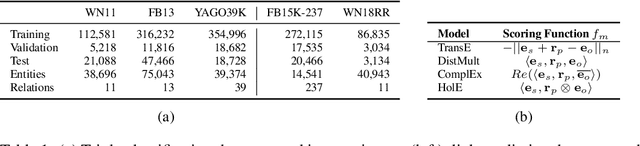
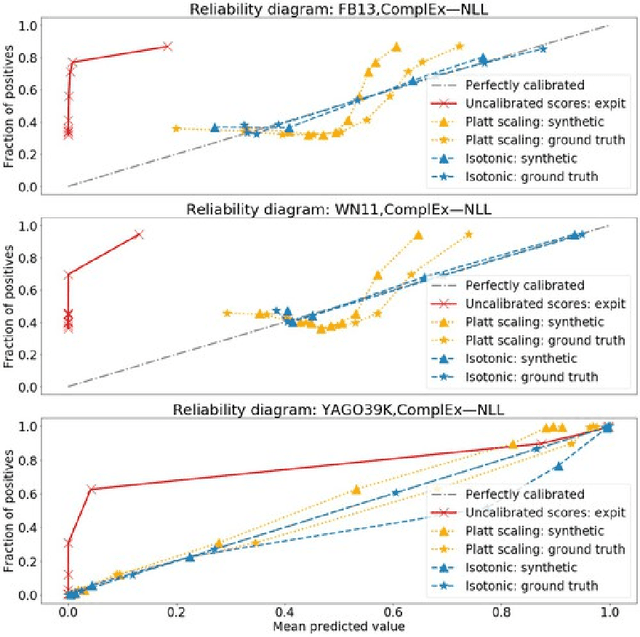

Knowledge graph embedding research has overlooked the problem of probability calibration. We show popular embedding models are indeed uncalibrated. That means probability estimates associated to predicted triples are unreliable. We present a novel method to calibrate a model when ground truth negatives are not available, which is the usual case in knowledge graphs. We propose to use Platt scaling and isotonic regression alongside our method. Experiments on three datasets with ground truth negatives show our contribution leads to well-calibrated models when compared to the gold standard of using negatives. We get significantly better results than the uncalibrated models from all calibration methods. We show isotonic regression offers the best the performance overall, not without trade-offs. We also show that calibrated models reach state-of-the-art accuracy without the need to define relation-specific decision thresholds.
Adversarial Attacks on Variational Autoencoders
Jun 12, 2018
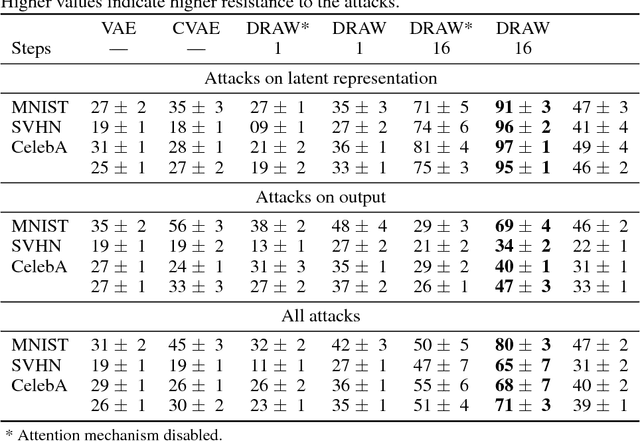
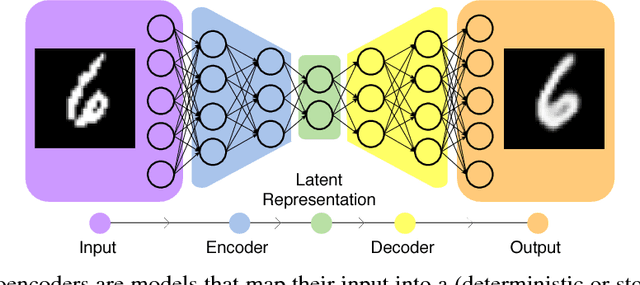

Adversarial attacks are malicious inputs that derail machine-learning models. We propose a scheme to attack autoencoders, as well as a quantitative evaluation framework that correlates well with the qualitative assessment of the attacks. We assess --- with statistically validated experiments --- the resistance to attacks of three variational autoencoders (simple, convolutional, and DRAW) in three datasets (MNIST, SVHN, CelebA), showing that both DRAW's recurrence and attention mechanism lead to better resistance. As autoencoders are proposed for compressing data --- a scenario in which their safety is paramount --- we expect more attention will be given to adversarial attacks on them.
Known Unknowns: Uncertainty Quality in Bayesian Neural Networks
Dec 23, 2016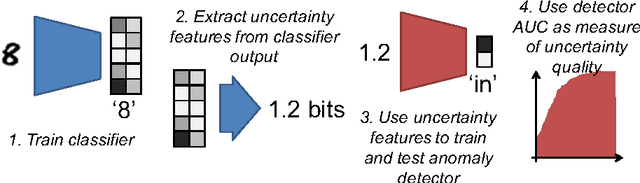


We evaluate the uncertainty quality in neural networks using anomaly detection. We extract uncertainty measures (e.g. entropy) from the predictions of candidate models, use those measures as features for an anomaly detector, and gauge how well the detector differentiates known from unknown classes. We assign higher uncertainty quality to candidate models that lead to better detectors. We also propose a novel method for sampling a variational approximation of a Bayesian neural network, called One-Sample Bayesian Approximation (OSBA). We experiment on two datasets, MNIST and CIFAR10. We compare the following candidate neural network models: Maximum Likelihood, Bayesian Dropout, OSBA, and --- for MNIST --- the standard variational approximation. We show that Bayesian Dropout and OSBA provide better uncertainty information than Maximum Likelihood, and are essentially equivalent to the standard variational approximation, but much faster.
Adversarial Images for Variational Autoencoders
Dec 01, 2016


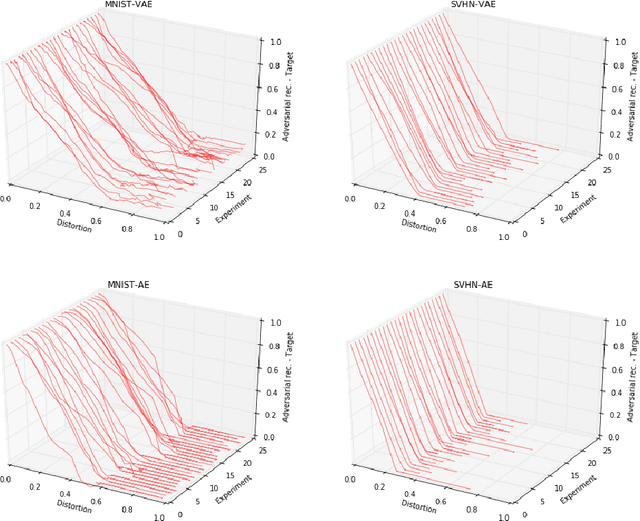
We investigate adversarial attacks for autoencoders. We propose a procedure that distorts the input image to mislead the autoencoder in reconstructing a completely different target image. We attack the internal latent representations, attempting to make the adversarial input produce an internal representation as similar as possible as the target's. We find that autoencoders are much more robust to the attack than classifiers: while some examples have tolerably small input distortion, and reasonable similarity to the target image, there is a quasi-linear trade-off between those aims. We report results on MNIST and SVHN datasets, and also test regular deterministic autoencoders, reaching similar conclusions in all cases. Finally, we show that the usual adversarial attack for classifiers, while being much easier, also presents a direct proportion between distortion on the input, and misdirection on the output. That proportionality however is hidden by the normalization of the output, which maps a linear layer into non-linear probabilities.
Exploring the Space of Adversarial Images
Jun 23, 2016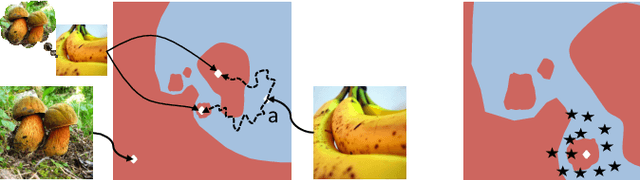

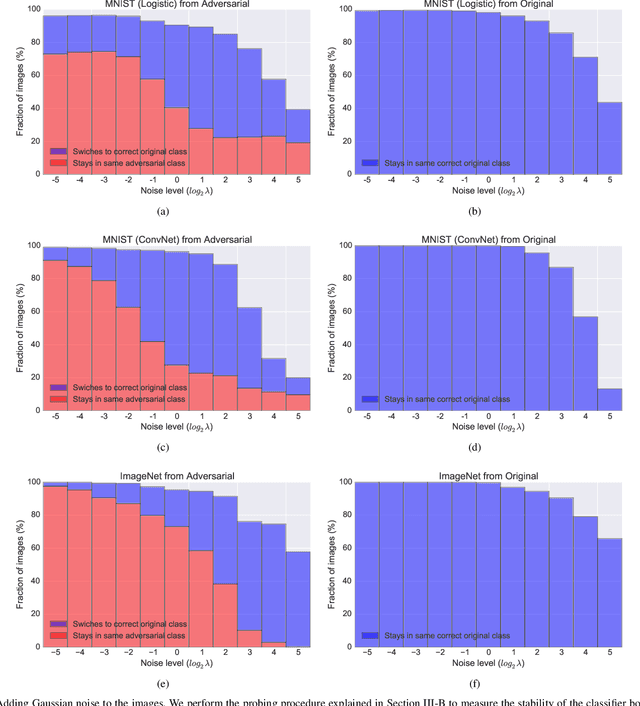
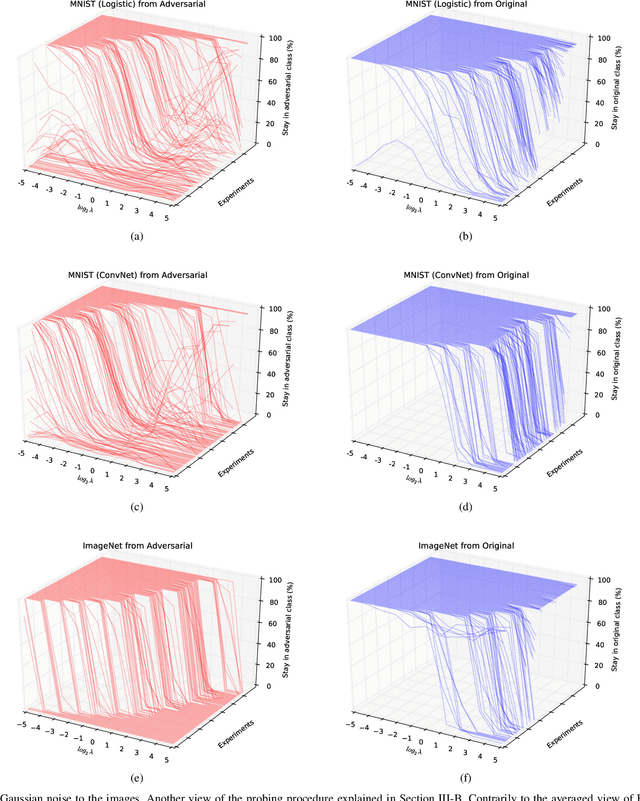
Adversarial examples have raised questions regarding the robustness and security of deep neural networks. In this work we formalize the problem of adversarial images given a pretrained classifier, showing that even in the linear case the resulting optimization problem is nonconvex. We generate adversarial images using shallow and deep classifiers on the MNIST and ImageNet datasets. We probe the pixel space of adversarial images using noise of varying intensity and distribution. We bring novel visualizations that showcase the phenomenon and its high variability. We show that adversarial images appear in large regions in the pixel space, but that, for the same task, a shallow classifier seems more robust to adversarial images than a deep convolutional network.