Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Attacks on Variational Autoencoders
Paper and Code

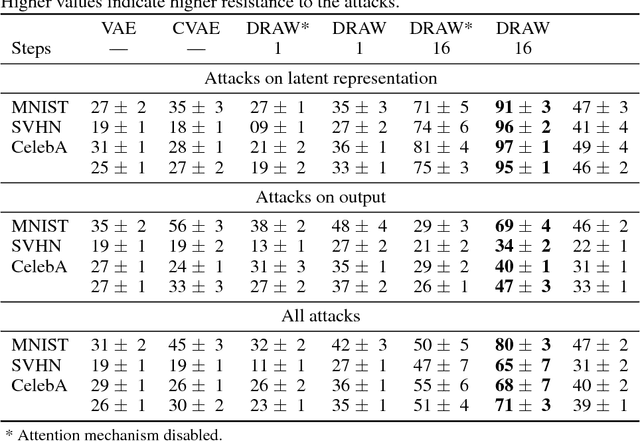

Adversarial attacks are malicious inputs that derail machine-learning models. We propose a scheme to attack autoencoders, as well as a quantitative evaluation framework that correlates well with the qualitative assessment of the attacks. We assess --- with statistically validated experiments --- the resistance to attacks of three variational autoencoders (simple, convolutional, and DRAW) in three datasets (MNIST, SVHN, CelebA), showing that both DRAW's recurrence and attention mechanism lead to better resistance. As autoencoders are proposed for compressing data --- a scenario in which their safety is paramount --- we expect more attention will be given to adversarial attacks on them.
View paper on