 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Semantic Modeling for Building Energy Management
Apr 17, 2024



Buildings account for a substantial portion of global energy consumption. Reducing buildings' energy usage primarily involves obtaining data from building systems and environment, which are instrumental in assessing and optimizing the building's performance. However, as devices from various manufacturers represent their data in unique ways, this disparity introduces challenges for semantic interoperability and creates obstacles in developing scalable building applications. This survey explores the leading semantic modeling techniques deployed for energy management in buildings. Furthermore, it aims to offer tangible use cases for applying semantic models, shedding light on the pivotal concepts and limitations intrinsic to each model. Our findings will assist researchers in discerning the appropriate circumstances and methodologies for employing these models in various use cases.
Evaluation of LLM Chatbots for OSINT-based Cyberthreat Awareness
Jan 26, 2024Knowledge sharing about emerging threats is crucial in the rapidly advancing field of cybersecurity and forms the foundation of Cyber Threat Intelligence. In this context, Large Language Models are becoming increasingly significant in the field of cybersecurity, presenting a wide range of opportunities. This study explores the capability of chatbots such as ChatGPT, GPT4all, Dolly,Stanford Alpaca, Alpaca-LoRA, and Falcon to identify cybersecurity-related text within Open Source Intelligence. We assess the capabilities of existing chatbot models for Natural Language Processing tasks. We consider binary classification and Named Entity Recognition as tasks. This study analyzes well-established data collected from Twitter, derived from previous research efforts. Regarding cybersecurity binary classification, Chatbot GPT-4 as a commercial model achieved an acceptable F1-score of 0.94, and the open-source GPT4all model achieved an F1-score of 0.90. However, concerning cybersecurity entity recognition, chatbot models have limitations and are less effective. This study demonstrates the capability of these chatbots only for specific tasks, such as cybersecurity binary classification, while highlighting the need for further refinement in other tasks, such as Named Entity Recognition tasks.
Processing Tweets for Cybersecurity Threat Awareness
Apr 03, 2019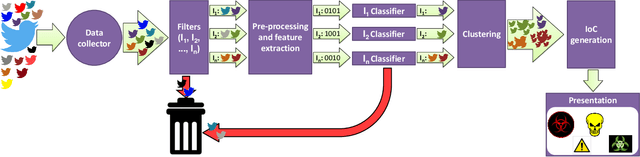

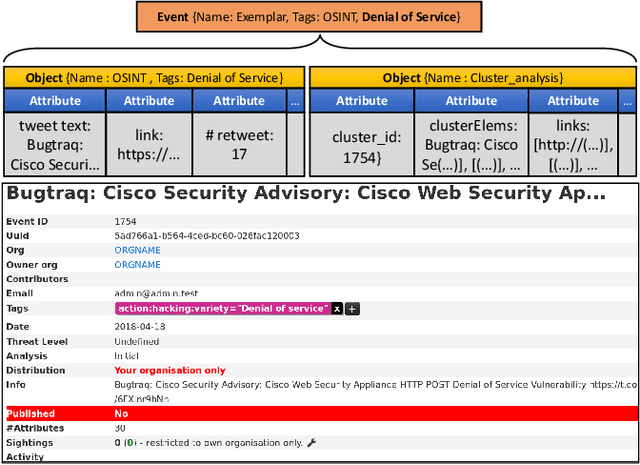

Receiving timely and relevant security information is crucial for maintaining a high-security level on an IT infrastructure. This information can be extracted from Open Source Intelligence published daily by users, security organisations, and researchers. In particular, Twitter has become an information hub for obtaining cutting-edge information about many subjects, including cybersecurity. This work proposes SYNAPSE, a Twitter-based streaming threat monitor that generates a continuously updated summary of the threat landscape related to a monitored infrastructure. Its tweet-processing pipeline is composed of filtering, feature extraction, binary classification, an innovative clustering strategy, and generation of Indicators of Compromise (IoCs). A quantitative evaluation considering all tweets from 80 accounts over more than 8 months (over 195.000 tweets), shows that our approach timely and successfully finds the majority of security-related tweets concerning an example IT infrastructure (true positive rate above 90%), incorrectly selects a small number of tweets as relevant (false positive rate under 10%), and summarises the results to very few IoCs per day. A qualitative evaluation of the IoCs generated by SYNAPSE demonstrates their relevance (based on the CVSS score and the availability of patches or exploits), and timeliness (based on threat disclosure dates from NVD).
Cyberthreat Detection from Twitter using Deep Neural Networks
Apr 01, 2019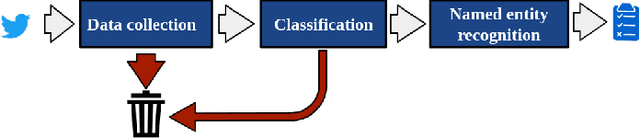
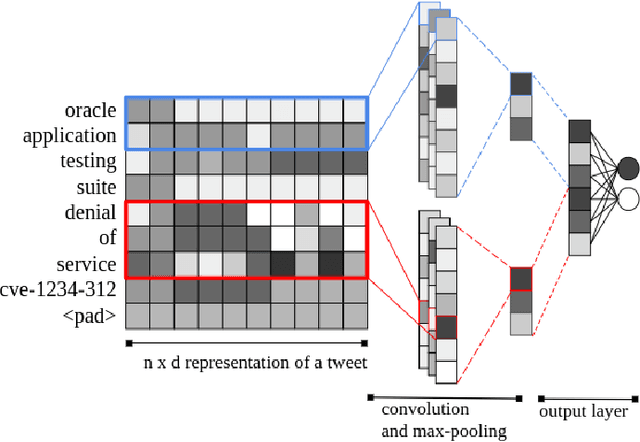
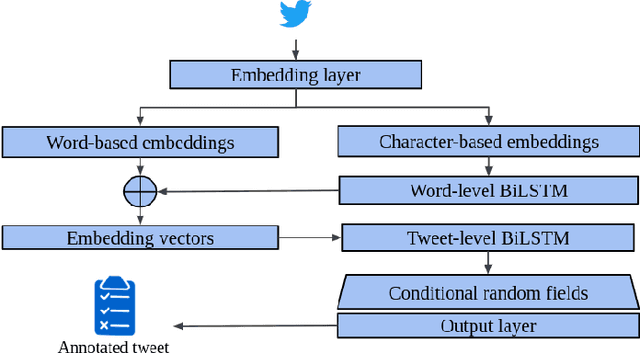
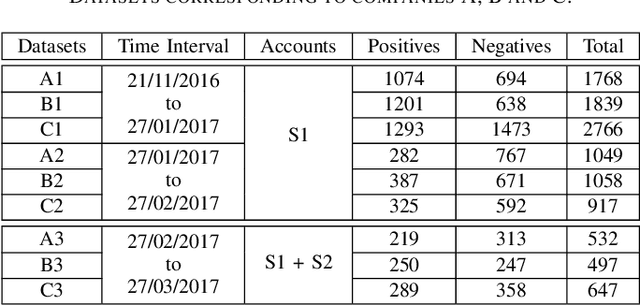
To be prepared against cyberattacks, most organizations resort to security information and event management systems to monitor their infrastructures. These systems depend on the timeliness and relevance of the latest updates, patches and threats provided by cyberthreat intelligence feeds. Open source intelligence platforms, namely social media networks such as Twitter, are capable of aggregating a vast amount of cybersecurity-related sources. To process such information streams, we require scalable and efficient tools capable of identifying and summarizing relevant information for specified assets. This paper presents the processing pipeline of a novel tool that uses deep neural networks to process cybersecurity information received from Twitter. A convolutional neural network identifies tweets containing security-related information relevant to assets in an IT infrastructure. Then, a bidirectional long short-term memory network extracts named entities from these tweets to form a security alert or to fill an indicator of compromise. The proposed pipeline achieves an average 94% true positive rate and 91% true negative rate for the classification task and an average F1-score of 92% for the named entity recognition task, across three case study infrastructures.
Dimensional emotion recognition using visual and textual cues
May 03, 2018


This paper addresses the problem of automatic emotion recognition in the scope of the One-Minute Gradual-Emotional Behavior challenge (OMG-Emotion challenge). The underlying objective of the challenge is the automatic estimation of emotion expressions in the two-dimensional emotion representation space (i.e., arousal and valence). The adopted methodology is a weighted ensemble of several models from both video and text modalities. For video-based recognition, two different types of visual cues (i.e., face and facial landmarks) were considered to feed a multi-input deep neural network. Regarding the text modality, a sequential model based on a simple recurrent architecture was implemented. In addition, we also introduce a model based on high-level features in order to embed domain knowledge in the learning process. Experimental results on the OMG-Emotion validation set demonstrate the effectiveness of the implemented ensemble model as it clearly outperforms the current baseline methods.