 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYCB-Ev SD: Synthetic event-vision dataset for 6DoF object pose estimation
Nov 14, 2025We introduce YCB-Ev SD, a synthetic dataset of event-camera data at standard definition (SD) resolution for 6DoF object pose estimation. While synthetic data has become fundamental in frame-based computer vision, event-based vision lacks comparable comprehensive resources. Addressing this gap, we present 50,000 event sequences of 34 ms duration each, synthesized from Physically Based Rendering (PBR) scenes of YCB-Video objects following the Benchmark for 6D Object Pose (BOP) methodology. Our generation framework employs simulated linear camera motion to ensure complete scene coverage, including background activity. Through systematic evaluation of event representations for CNN-based inference, we demonstrate that time-surfaces with linear decay and dual-channel polarity encoding achieve superior pose estimation performance, outperforming exponential decay and single-channel alternatives by significant margins. Our analysis reveals that polarity information contributes most substantially to performance gains, while linear temporal encoding preserves critical motion information more effectively than exponential decay. The dataset is provided in a structured format with both raw event streams and precomputed optimal representations to facilitate immediate research use and reproducible benchmarking. The dataset is publicly available at https://huggingface.co/datasets/paroj/ycbev_sd.
YCB-Ev: Event-vision dataset for 6DoF object pose estimation
Sep 15, 2023Our work introduces the YCB-Ev dataset, which contains synchronized RGB-D frames and event data that enables evaluating 6DoF object pose estimation algorithms using these modalities. This dataset provides ground truth 6DoF object poses for the same 21 YCB objects \cite{calli2017yale} that were used in the YCB-Video (YCB-V) dataset, enabling the evaluation of algorithm performance when transferred across datasets. The dataset consists of 21 synchronized event and RGB-D sequences, amounting to a total of 7:43 minutes of video. Notably, 12 of these sequences feature the same object arrangement as the YCB-V subset used in the BOP challenge. Our dataset is the first to provide ground truth 6DoF pose data for event streams. Furthermore, we evaluate the generalization capabilities of two state-of-the-art algorithms, which were pre-trained for the BOP challenge, using our novel YCB-V sequences. The proposed dataset is available at https://github.com/paroj/ycbev.
Transferring dense object detection models to event-based data
Oct 05, 2022
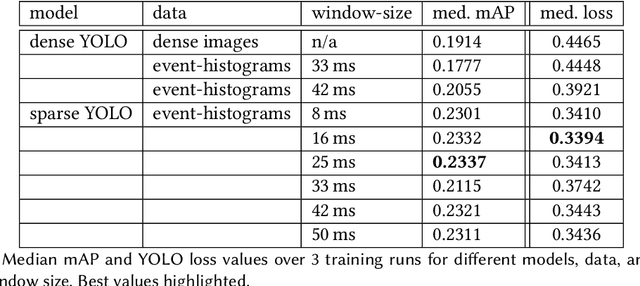
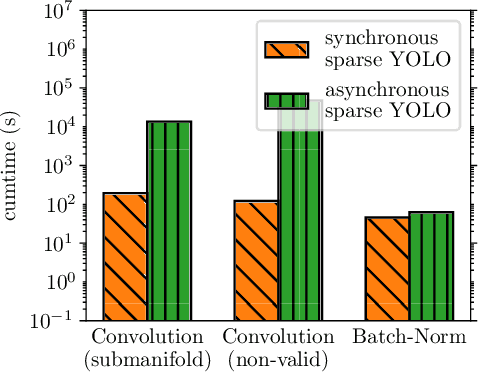
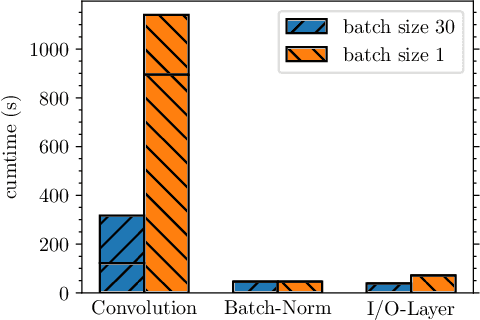
Event-based image representations are fundamentally different to traditional dense images. This poses a challenge to apply current state-of-the-art models for object detection as they are designed for dense images. In this work we evaluate the YOLO object detection model on event data. To this end we replace dense-convolution layers by either sparse convolutions or asynchronous sparse convolutions which enables direct processing of event-based images and compare the performance and runtime to feeding event-histograms into dense-convolutions. Here, hyper-parameters are shared across all variants to isolate the effect sparse-representation has on detection performance. At this, we show that current sparse-convolution implementations cannot translate their theoretical lower computation requirements into an improved runtime.
Style-transfer GANs for bridging the domain gap in synthetic pose estimator training
Apr 28, 2020


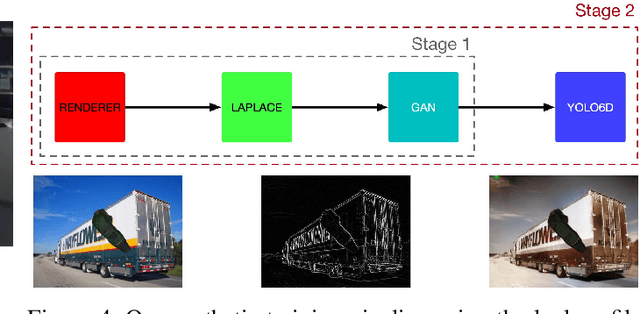
Given the dependency of current CNN architectures on a large training set, the possibility of using synthetic data is alluring as it allows generating a virtually infinite amount of labeled training data. However, producing such data is a non-trivial task as current CNN architectures are sensitive to the domain gap between real and synthetic data. We propose to adopt general-purpose GAN models for pixel-level image translation, allowing to formulate the domain gap itself as a learning problem. Here, we focus on training the single-stage YOLO6D object pose estimator on synthetic CAD geometry only, where not even approximate surface information is available. Our evaluation shows a considerable improvement in model performance when compared to a model trained with the same degree of domain randomization, while requiring only very little additional effort.
Real-time texturing for 6D object instance detection from RGB Images
Dec 13, 2019
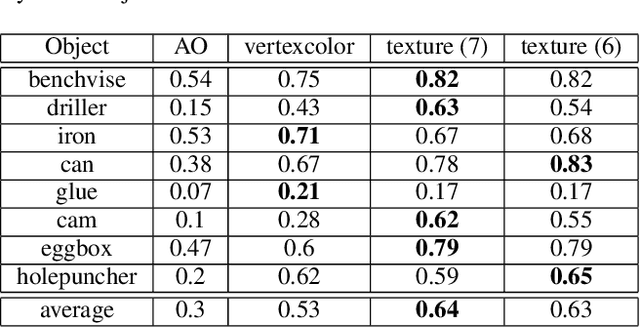

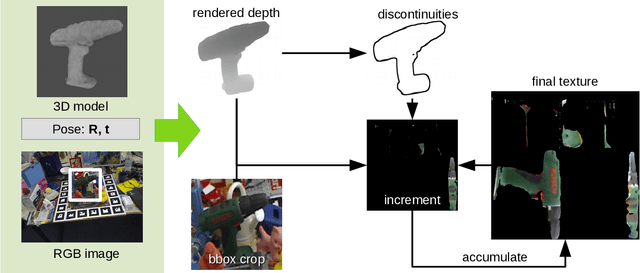
For objected detection, the availability of color cues strongly influences detection rates and is even a prerequisite for many methods. However, when training on synthetic CAD data, this information is not available. We therefore present a method for generating a texture-map from image sequences in real-time. The method relies on 6 degree-of-freedom poses and a 3D-model being available. In contrast to previous works this allows interleaving detection and texturing for upgrading the detector on-the-fly. Our evaluation shows that the acquired texture-map significantly improves detection rates using the LINEMOD detector on RGB images only. Additionally, we use the texture-map to differentiate instances of the same object by surface color.
calibDB: enabling web based computer vision through on-the-fly camera calibration
Aug 15, 2019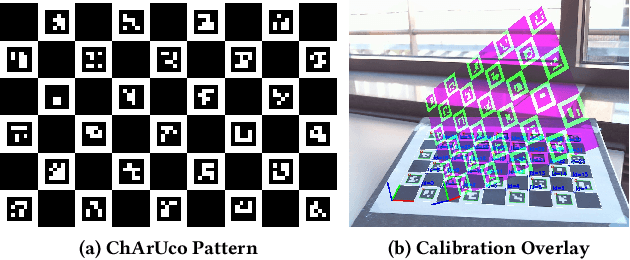
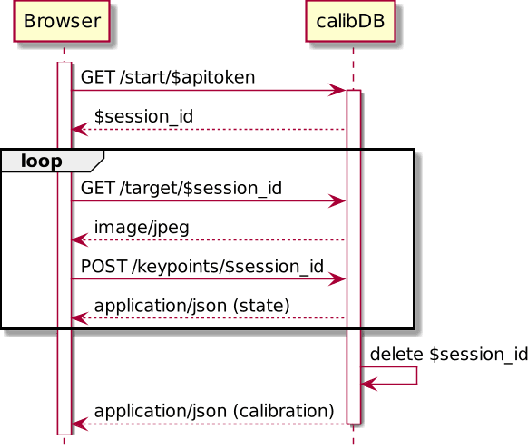

For many computer vision applications, the availability of camera calibration data is crucial as overall quality heavily depends on it. While calibration data is available on some devices through Augmented Reality (AR) frameworks like ARCore and ARKit, for most cameras this information is not available. Therefore, we propose a web based calibration service that not only aggregates calibration data, but also allows calibrating new cameras on-the-fly. We build upon a novel camera calibration framework that enables even novice users to perform a precise camera calibration in about 2 minutes. This allows general deployment of computer vision algorithms on the web, which was previously not possible due to lack of calibration data.
Efficient Pose Selection for Interactive Camera Calibration
Jul 09, 2019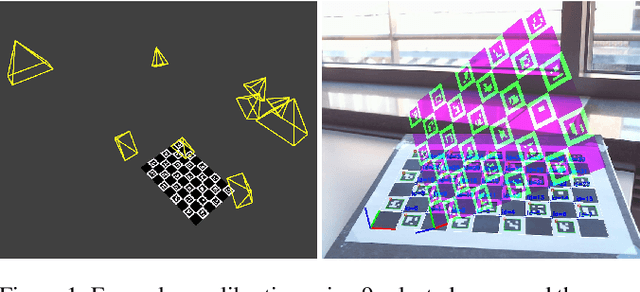
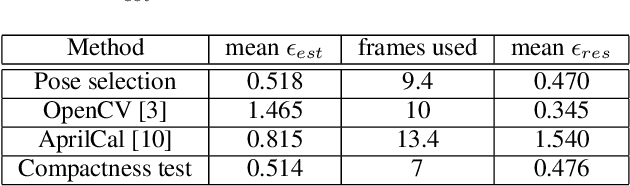
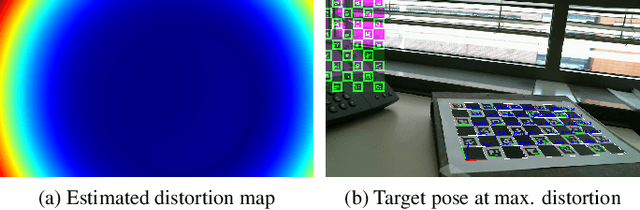
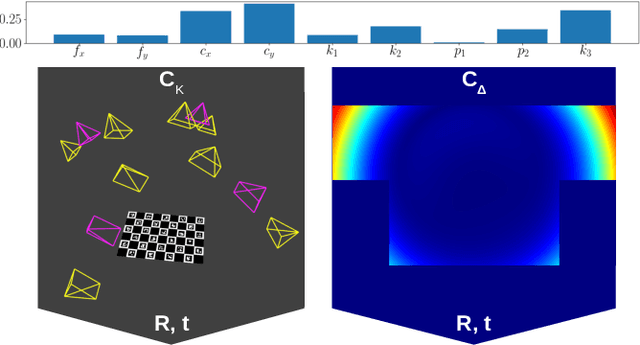
The choice of poses for camera calibration with planar patterns is only rarely considered - yet the calibration precision heavily depends on it. This work presents a pose selection method that finds a compact and robust set of calibration poses and is suitable for interactive calibration. Consequently, singular poses that would lead to an unreliable solution are avoided explicitly, while poses reducing the uncertainty of the calibration are favoured. For this, we use uncertainty propagation. Our method takes advantage of a self-identifying calibration pattern to track the camera pose in real-time. This allows to iteratively guide the user to the target poses, until the desired quality level is reached. Therefore, only a sparse set of key-frames is needed for calibration. The method is evaluated on separate training and testing sets, as well as on synthetic data. Our approach performs better than comparable solutions while requiring 30% less calibration frames.