 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccenture at CheckThat! 2021: Interesting claim identification and ranking with contextually sensitive lexical training data augmentation
Jul 12, 2021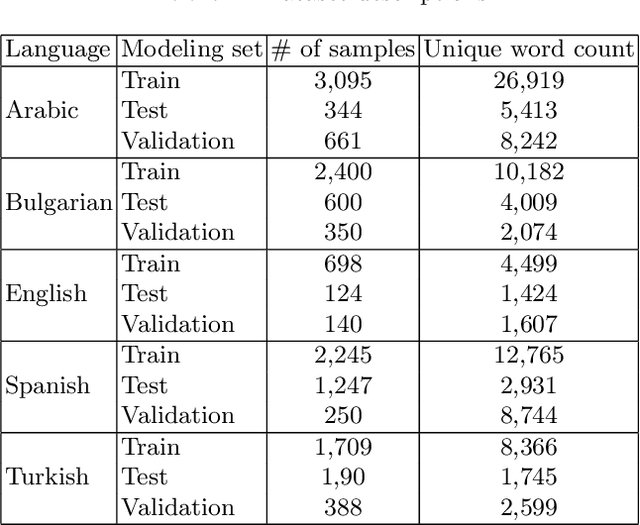

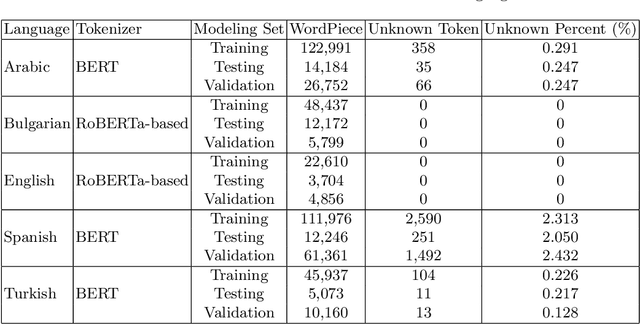
This paper discusses the approach used by the Accenture Team for CLEF2021 CheckThat! Lab, Task 1, to identify whether a claim made in social media would be interesting to a wide audience and should be fact-checked. Twitter training and test data were provided in English, Arabic, Spanish, Turkish, and Bulgarian. Claims were to be classified (check-worthy/not check-worthy) and ranked in priority order for the fact-checker. Our method used deep neural network transformer models with contextually sensitive lexical augmentation applied on the supplied training datasets to create additional training samples. This augmentation approach improved the performance for all languages. Overall, our architecture and data augmentation pipeline produced the best submitted system for Arabic, and performance scales according to the quantity of provided training data for English, Spanish, Turkish, and Bulgarian. This paper investigates the deep neural network architectures for each language as well as the provided data to examine why the approach worked so effectively for Arabic, and discusses additional data augmentation measures that should could be useful to this problem.
Accenture at CheckThat! 2020: If you say so: Post-hoc fact-checking of claims using transformer-based models
Sep 05, 2020We introduce the strategies used by the Accenture Team for the CLEF2020 CheckThat! Lab, Task 1, on English and Arabic. This shared task evaluated whether a claim in social media text should be professionally fact checked. To a journalist, a statement presented as fact, which would be of interest to a large audience, requires professional fact-checking before dissemination. We utilized BERT and RoBERTa models to identify claims in social media text a professional fact-checker should review, and rank these in priority order for the fact-checker. For the English challenge, we fine-tuned a RoBERTa model and added an extra mean pooling layer and a dropout layer to enhance generalizability to unseen text. For the Arabic task, we fine-tuned Arabic-language BERT models and demonstrate the use of back-translation to amplify the minority class and balance the dataset. The work presented here was scored 1st place in the English track, and 1st, 2nd, 3rd, and 4th place in the Arabic track.
A random forest system combination approach for error detection in digital dictionaries
Oct 30, 2014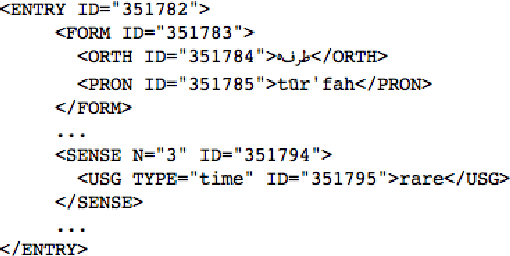
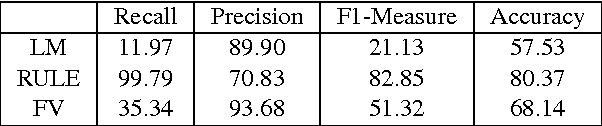

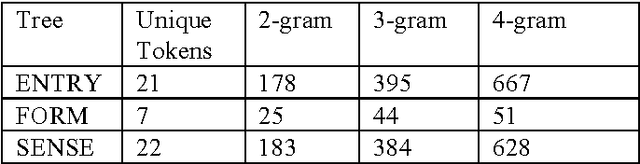
When digitizing a print bilingual dictionary, whether via optical character recognition or manual entry, it is inevitable that errors are introduced into the electronic version that is created. We investigate automating the process of detecting errors in an XML representation of a digitized print dictionary using a hybrid approach that combines rule-based, feature-based, and language model-based methods. We investigate combining methods and show that using random forests is a promising approach. We find that in isolation, unsupervised methods rival the performance of supervised methods. Random forests typically require training data so we investigate how we can apply random forests to combine individual base methods that are themselves unsupervised without requiring large amounts of training data. Experiments reveal empirically that a relatively small amount of data is sufficient and can potentially be further reduced through specific selection criteria.
* 9 pages, 7 figures, 10 tables; appeared in Proceedings of the Workshop on Innovative Hybrid Approaches to the Processing of Textual Data, April 2012
Detecting Structural Irregularity in Electronic Dictionaries Using Language Modeling
Oct 29, 2014


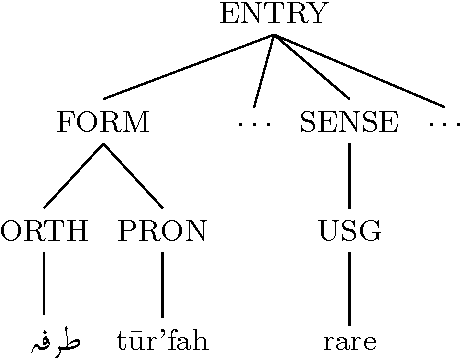
Dictionaries are often developed using tools that save to Extensible Markup Language (XML)-based standards. These standards often allow high-level repeating elements to represent lexical entries, and utilize descendants of these repeating elements to represent the structure within each lexical entry, in the form of an XML tree. In many cases, dictionaries are published that have errors and inconsistencies that are expensive to find manually. This paper discusses a method for dictionary writers to quickly audit structural regularity across entries in a dictionary by using statistical language modeling. The approach learns the patterns of XML nodes that could occur within an XML tree, and then calculates the probability of each XML tree in the dictionary against these patterns to look for entries that diverge from the norm.
* 6 pages, 2 figures, 11 tables; appeared in Proceedings of Electronic Lexicography in the 21st Century (eLex), November 2011
Correcting Errors in Digital Lexicographic Resources Using a Dictionary Manipulation Language
Oct 28, 2014
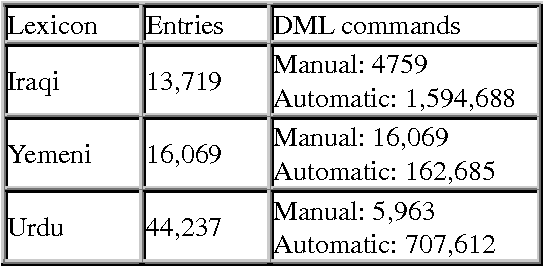

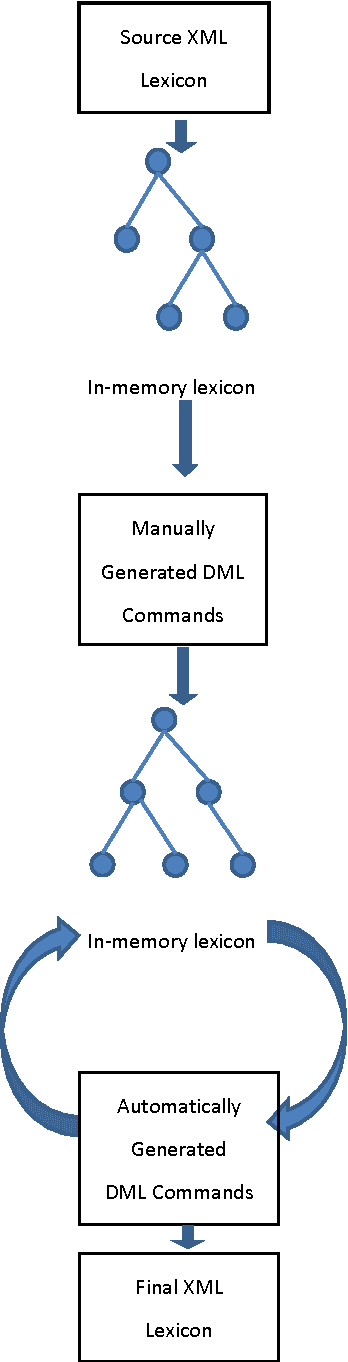
We describe a paradigm for combining manual and automatic error correction of noisy structured lexicographic data. Modifications to the structure and underlying text of the lexicographic data are expressed in a simple, interpreted programming language. Dictionary Manipulation Language (DML) commands identify nodes by unique identifiers, and manipulations are performed using simple commands such as create, move, set text, etc. Corrected lexicons are produced by applying sequences of DML commands to the source version of the lexicon. DML commands can be written manually to repair one-off errors or generated automatically to correct recurring problems. We discuss advantages of the paradigm for the task of editing digital bilingual dictionaries.
* 5 pages, 3 figures, 1 table; appeared in Proceedings of Electronic Lexicography in the 21st Century (eLex), November 2011