 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccenture at CheckThat! 2021: Interesting claim identification and ranking with contextually sensitive lexical training data augmentation
Jul 12, 2021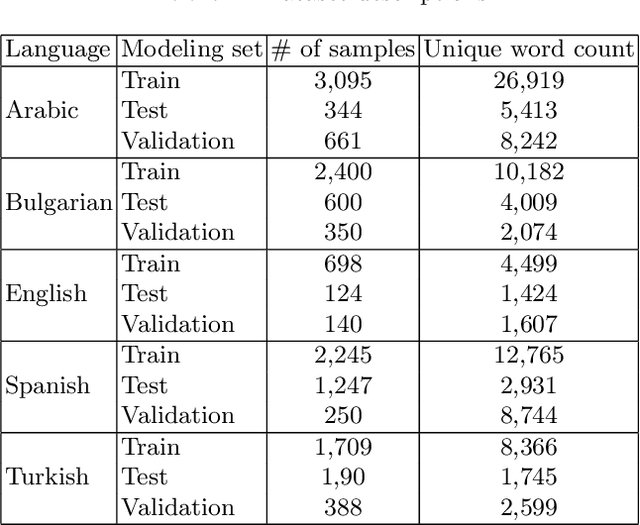

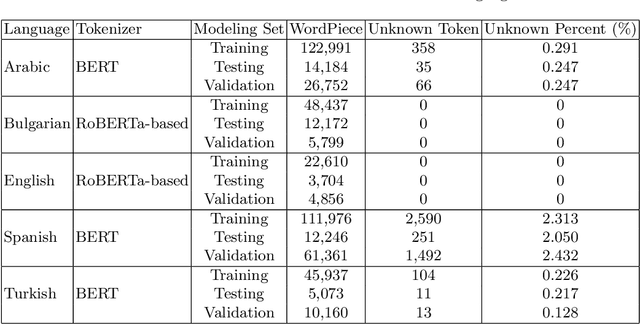
This paper discusses the approach used by the Accenture Team for CLEF2021 CheckThat! Lab, Task 1, to identify whether a claim made in social media would be interesting to a wide audience and should be fact-checked. Twitter training and test data were provided in English, Arabic, Spanish, Turkish, and Bulgarian. Claims were to be classified (check-worthy/not check-worthy) and ranked in priority order for the fact-checker. Our method used deep neural network transformer models with contextually sensitive lexical augmentation applied on the supplied training datasets to create additional training samples. This augmentation approach improved the performance for all languages. Overall, our architecture and data augmentation pipeline produced the best submitted system for Arabic, and performance scales according to the quantity of provided training data for English, Spanish, Turkish, and Bulgarian. This paper investigates the deep neural network architectures for each language as well as the provided data to examine why the approach worked so effectively for Arabic, and discusses additional data augmentation measures that should could be useful to this problem.
Accenture at CheckThat! 2020: If you say so: Post-hoc fact-checking of claims using transformer-based models
Sep 05, 2020We introduce the strategies used by the Accenture Team for the CLEF2020 CheckThat! Lab, Task 1, on English and Arabic. This shared task evaluated whether a claim in social media text should be professionally fact checked. To a journalist, a statement presented as fact, which would be of interest to a large audience, requires professional fact-checking before dissemination. We utilized BERT and RoBERTa models to identify claims in social media text a professional fact-checker should review, and rank these in priority order for the fact-checker. For the English challenge, we fine-tuned a RoBERTa model and added an extra mean pooling layer and a dropout layer to enhance generalizability to unseen text. For the Arabic task, we fine-tuned Arabic-language BERT models and demonstrate the use of back-translation to amplify the minority class and balance the dataset. The work presented here was scored 1st place in the English track, and 1st, 2nd, 3rd, and 4th place in the Arabic track.