 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeviations in Representations Induced by Adversarial Attacks
Nov 07, 2022


Deep learning has been a popular topic and has achieved success in many areas. It has drawn the attention of researchers and machine learning practitioners alike, with developed models deployed to a variety of settings. Along with its achievements, research has shown that deep learning models are vulnerable to adversarial attacks. This finding brought about a new direction in research, whereby algorithms were developed to attack and defend vulnerable networks. Our interest is in understanding how these attacks effect change on the intermediate representations of deep learning models. We present a method for measuring and analyzing the deviations in representations induced by adversarial attacks, progressively across a selected set of layers. Experiments are conducted using an assortment of attack algorithms, on the CIFAR-10 dataset, with plots created to visualize the impact of adversarial attacks across different layers in a network.
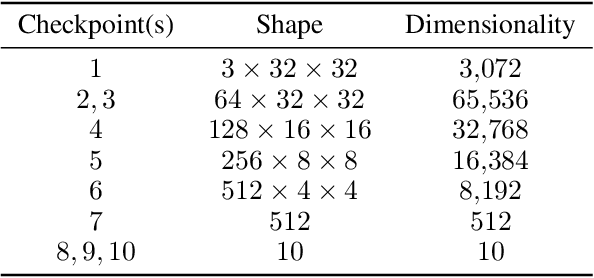
Measuring the Contribution of Multiple Model Representations in Detecting Adversarial Instances
Nov 13, 2021
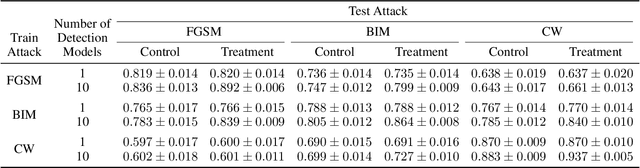
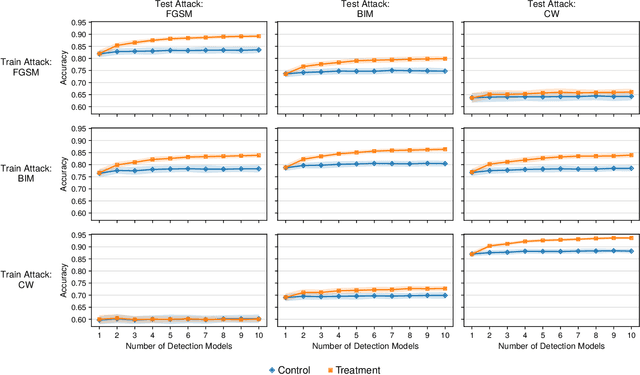
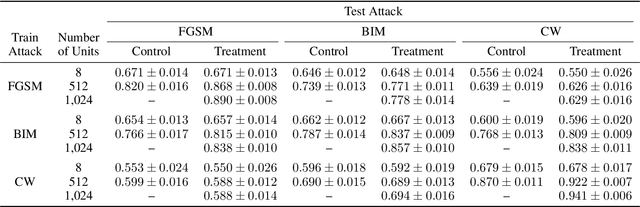
Deep learning models have been used for a wide variety of tasks. They are prevalent in computer vision, natural language processing, speech recognition, and other areas. While these models have worked well under many scenarios, it has been shown that they are vulnerable to adversarial attacks. This has led to a proliferation of research into ways that such attacks could be identified and/or defended against. Our goal is to explore the contribution that can be attributed to using multiple underlying models for the purpose of adversarial instance detection. Our paper describes two approaches that incorporate representations from multiple models for detecting adversarial examples. We devise controlled experiments for measuring the detection impact of incrementally utilizing additional models. For many of the scenarios we consider, the results show that performance increases with the number of underlying models used for extracting representations.
Visualizing Representations of Adversarially Perturbed Inputs
May 28, 2021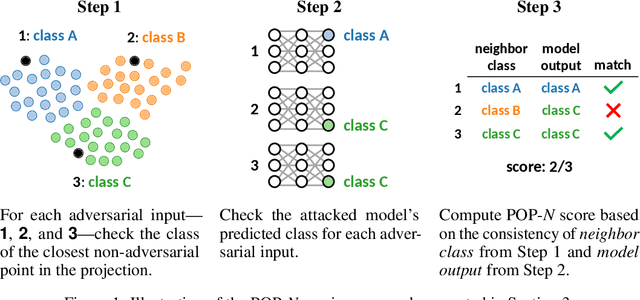
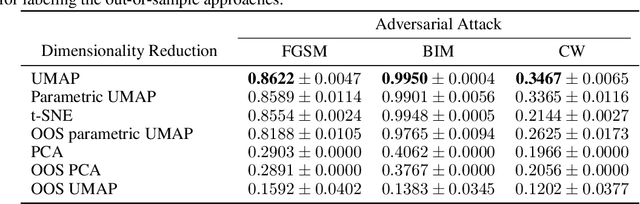

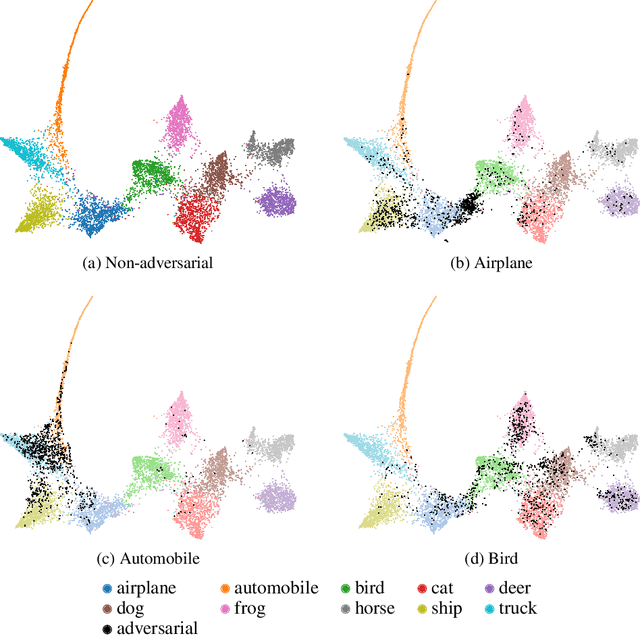
It has been shown that deep learning models are vulnerable to adversarial attacks. We seek to further understand the consequence of such attacks on the intermediate activations of neural networks. We present an evaluation metric, POP-N, which scores the effectiveness of projecting data to N dimensions under the context of visualizing representations of adversarially perturbed inputs. We conduct experiments on CIFAR-10 to compare the POP-2 score of several dimensionality reduction algorithms across various adversarial attacks. Finally, we utilize the 2D data corresponding to high POP-2 scores to generate example visualizations.
Modeling the Evolution of Retina Neural Network
Nov 24, 2020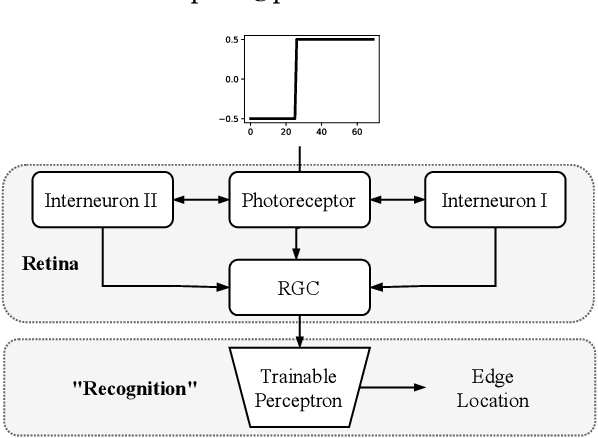
Vital to primary visual processing, retinal circuitry shows many similar structures across a very broad array of species, both vertebrate and non-vertebrate, especially functional components such as lateral inhibition. This surprisingly conservative pattern raises a question of how evolution leads to it, and whether there is any alternative that can also prompt helpful preprocessing. Here we design a state-of-the-art method using genetic algorithm that, with many degrees of freedom, leads to architectures whose functions are similar to biological retina, as well as effective alternatives that are different in structures and functions. We compare this state-of-the-art model to natural evolution and discuss how our framework can come into goal-driven search and sustainable enhancement of neural network models in machine learning.