Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisualizing Representations of Adversarially Perturbed Inputs
Paper and Code
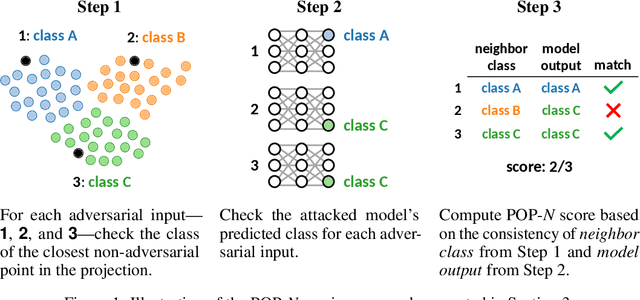
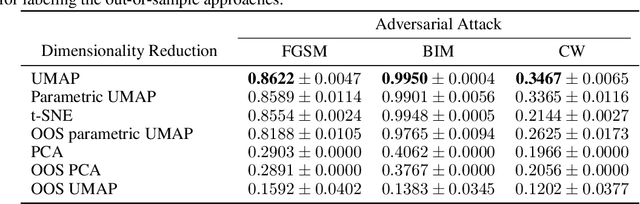

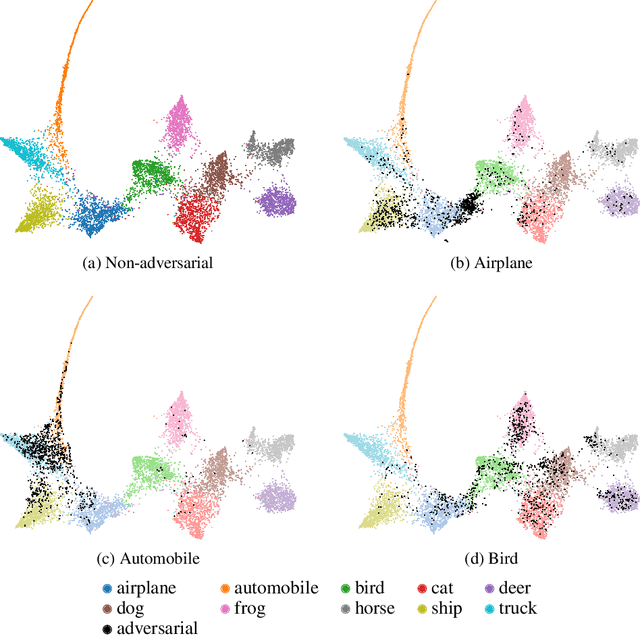
It has been shown that deep learning models are vulnerable to adversarial attacks. We seek to further understand the consequence of such attacks on the intermediate activations of neural networks. We present an evaluation metric, POP-N, which scores the effectiveness of projecting data to N dimensions under the context of visualizing representations of adversarially perturbed inputs. We conduct experiments on CIFAR-10 to compare the POP-2 score of several dimensionality reduction algorithms across various adversarial attacks. Finally, we utilize the 2D data corresponding to high POP-2 scores to generate example visualizations.
View paper on