 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring the Contribution of Multiple Model Representations in Detecting Adversarial Instances
Paper and Code

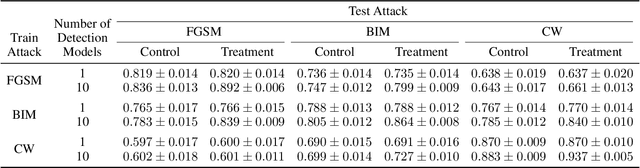
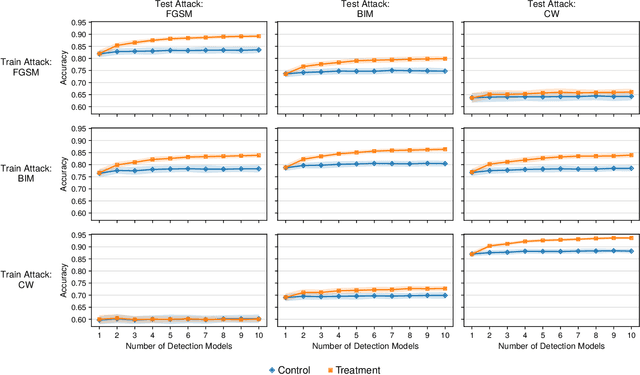
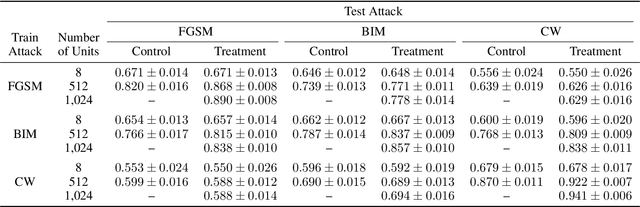
Deep learning models have been used for a wide variety of tasks. They are prevalent in computer vision, natural language processing, speech recognition, and other areas. While these models have worked well under many scenarios, it has been shown that they are vulnerable to adversarial attacks. This has led to a proliferation of research into ways that such attacks could be identified and/or defended against. Our goal is to explore the contribution that can be attributed to using multiple underlying models for the purpose of adversarial instance detection. Our paper describes two approaches that incorporate representations from multiple models for detecting adversarial examples. We devise controlled experiments for measuring the detection impact of incrementally utilizing additional models. For many of the scenarios we consider, the results show that performance increases with the number of underlying models used for extracting representations.