 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeviations in Representations Induced by Adversarial Attacks
Paper and Code

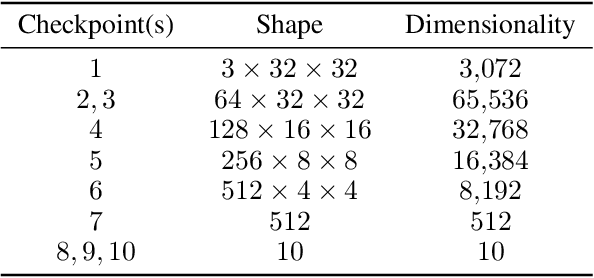


Deep learning has been a popular topic and has achieved success in many areas. It has drawn the attention of researchers and machine learning practitioners alike, with developed models deployed to a variety of settings. Along with its achievements, research has shown that deep learning models are vulnerable to adversarial attacks. This finding brought about a new direction in research, whereby algorithms were developed to attack and defend vulnerable networks. Our interest is in understanding how these attacks effect change on the intermediate representations of deep learning models. We present a method for measuring and analyzing the deviations in representations induced by adversarial attacks, progressively across a selected set of layers. Experiments are conducted using an assortment of attack algorithms, on the CIFAR-10 dataset, with plots created to visualize the impact of adversarial attacks across different layers in a network.