 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-adapting Robustness in Demand Learning
Nov 21, 2020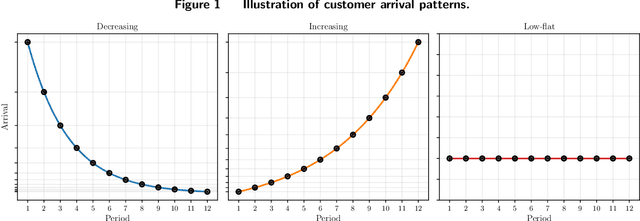
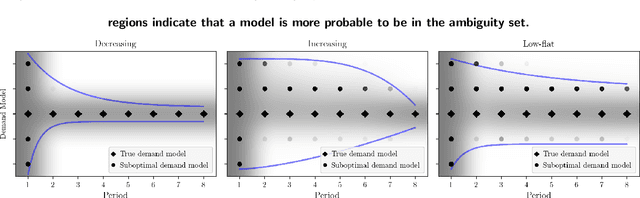
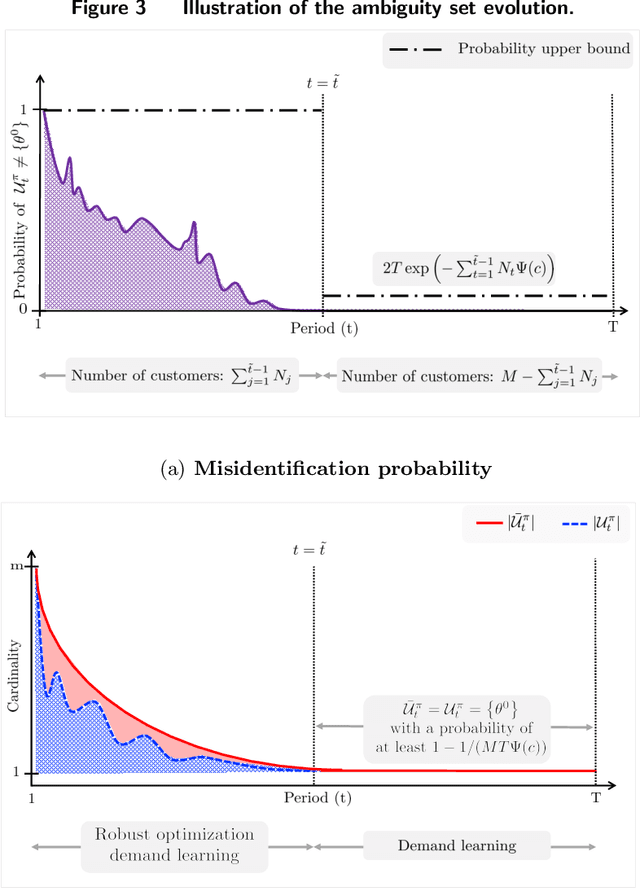
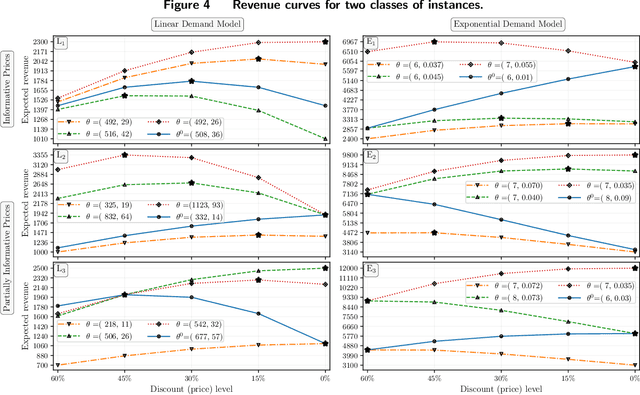
We study dynamic pricing over a finite number of periods in the presence of demand model ambiguity. Departing from the typical no-regret learning environment, where price changes are allowed at any time, pricing decisions are made at pre-specified points in time and each price can be applied to a large number of arrivals. In this environment, which arises in retailing, a pricing decision based on an incorrect demand model can significantly impact cumulative revenue. We develop an adaptively-robust-learning (ARL) pricing policy that learns the true model parameters from the data while actively managing demand model ambiguity. It optimizes an objective that is robust with respect to a self-adapting set of demand models, where a given model is included in this set only if the sales data revealed from prior pricing decisions makes it "probable". As a result, it gracefully transitions from being robust when demand model ambiguity is high to minimizing regret when this ambiguity diminishes upon receiving more data. We characterize the stochastic behavior of ARL's self-adapting ambiguity sets and derive a regret bound that highlights the link between the scale of revenue loss and the customer arrival pattern. We also show that ARL, by being conscious of both model ambiguity and revenue, bridges the gap between a distributionally robust policy and a follow-the-leader policy, which focus on model ambiguity and revenue, respectively. We numerically find that the ARL policy, or its extension thereof, exhibits superior performance compared to distributionally robust, follow-the-leader, and upper-confidence-bound policies in terms of expected revenue and/or value at risk.
Self-guided Approximate Linear Programs
Jan 09, 2020



Approximate linear programs (ALPs) are well-known models based on value function approximations (VFAs) to obtain heuristic policies and lower bounds on the optimal policy cost of Markov decision processes (MDPs). The ALP VFA is a linear combination of predefined basis functions that are chosen using domain knowledge and updated heuristically if the ALP optimality gap is large. We side-step the need for such basis function engineering in ALP -- an implementation bottleneck -- by proposing a sequence of ALPs that embed increasing numbers of random basis functions obtained via inexpensive sampling. We provide a sampling guarantee and show that the VFAs from this sequence of models converge to the exact value function. Nevertheless, the performance of the ALP policy can fluctuate significantly as more basis functions are sampled. To mitigate these fluctuations, we "self-guide" our convergent sequence of ALPs using past VFA information such that a worst-case measure of policy performance is improved. We perform numerical experiments on perishable inventory control and generalized joint replenishment applications, which, respectively, give rise to challenging discounted-cost MDPs and average-cost semi-MDPs. We find that self-guided ALPs (i) significantly reduce policy cost fluctuations and improve the optimality gaps from an ALP approach that employs basis functions tailored to the former application, and (ii) deliver optimality gaps that are comparable to a known adaptive basis function generation approach targeting the latter application. More broadly, our methodology provides application-agnostic policies and lower bounds to benchmark approaches that exploit application structure.