 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA comparative study of forecasting Corporate Credit Ratings using Neural Networks, Support Vector Machines, and Decision Trees
Jul 13, 2020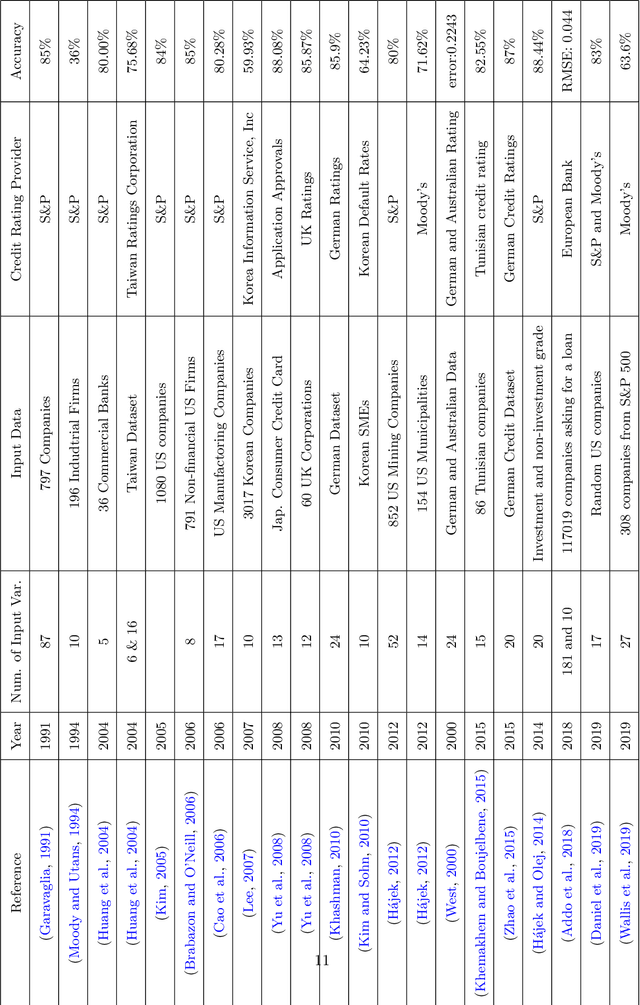
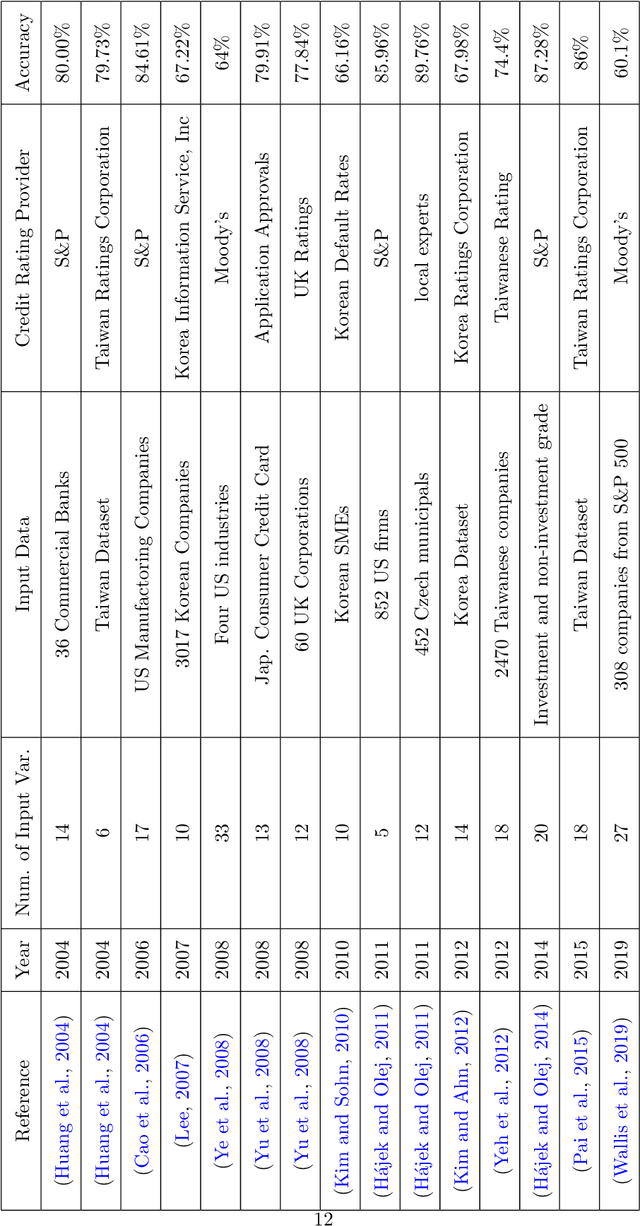

Credit ratings are one of the primary keys that reflect the level of riskiness and reliability of corporations to meet their financial obligations. Rating agencies tend to take extended periods of time to provide new ratings and update older ones. Therefore, credit scoring assessments using artificial intelligence has gained a lot of interest in recent years. Successful machine learning methods can provide rapid analysis of credit scores while updating older ones on a daily time scale. Related studies have shown that neural networks and support vector machines outperform other techniques by providing better prediction accuracy. The purpose of this paper is two fold. First, we provide a survey and a comparative analysis of results from literature applying machine learning techniques to predict credit rating. Second, we apply ourselves four machine learning techniques deemed useful from previous studies (Bagged Decision Trees, Random Forest, Support Vector Machine and Multilayer Perceptron) to the same datasets. We evaluate the results using a 10-fold cross validation technique. The results of the experiment for the datasets chosen show superior performance for decision tree based models. In addition to the conventional accuracy measure of classifiers, we introduce a measure of accuracy based on notches called "Notch Distance" to analyze the performance of the above classifiers in the specific context of credit rating. This measure tells us how far the predictions are from the true ratings. We further compare the performance of three major rating agencies, Standard $\&$ Poors, Moody's and Fitch where we show that the difference in their ratings is comparable with the decision tree prediction versus the actual rating on the test dataset.
Application of Deep Neural Networks to assess corporate Credit Rating
Mar 04, 2020

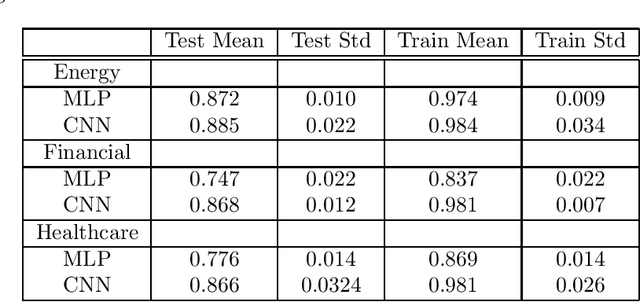
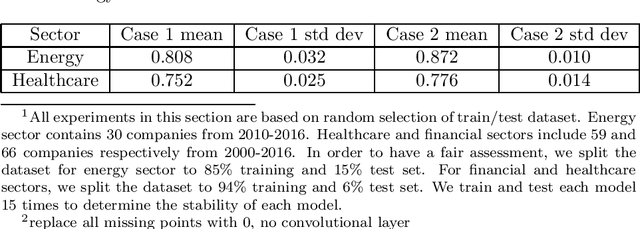
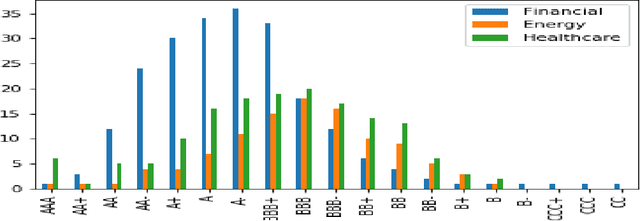
Recent literature implements machine learning techniques to assess corporate credit rating based on financial statement reports. In this work, we analyze the performance of four neural network architectures (MLP, CNN, CNN2D, LSTM) in predicting corporate credit rating as issued by Standard and Poor's. We analyze companies from the energy, financial and healthcare sectors in US. The goal of the analysis is to improve application of machine learning algorithms to credit assessment. To this end, we focus on three questions. First, we investigate if the algorithms perform better when using a selected subset of features, or if it is better to allow the algorithms to select features themselves. Second, is the temporal aspect inherent in financial data important for the results obtained by a machine learning algorithm? Third, is there a particular neural network architecture that consistently outperforms others with respect to input features, sectors and holdout set? We create several case studies to answer these questions and analyze the results using ANOVA and multiple comparison testing procedure.