 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Quantum Learning without Measurements
Oct 23, 2017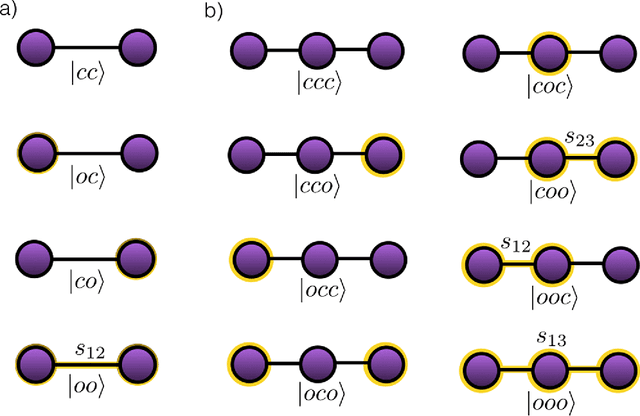
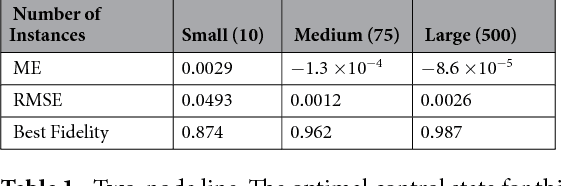
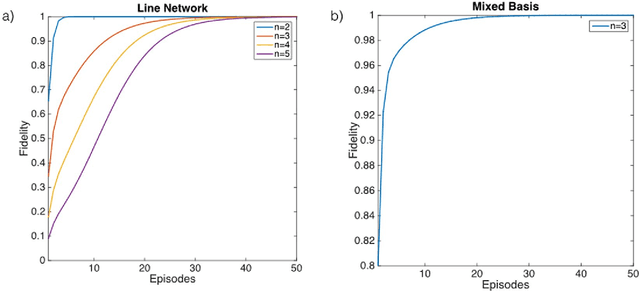
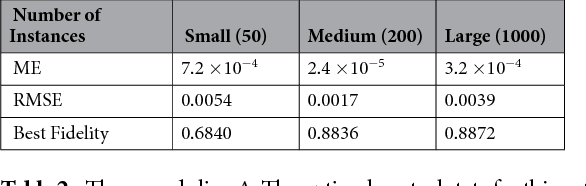
We propose a quantum machine learning algorithm for efficiently solving a class of problems encoded in quantum controlled unitary operations. The central physical mechanism of the protocol is the iteration of a quantum time-delayed equation that introduces feedback in the dynamics and eliminates the necessity of intermediate measurements. The performance of the quantum algorithm is analyzed by comparing the results obtained in numerical simulations with the outcome of classical machine learning methods for the same problem. The use of time-delayed equations enhances the toolbox of the field of quantum machine learning, which may enable unprecedented applications in quantum technologies.
Optimization of anemia treatment in hemodialysis patients via reinforcement learning
Sep 14, 2015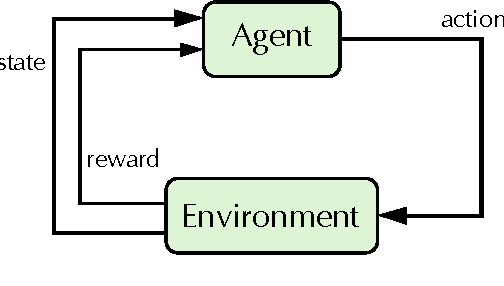
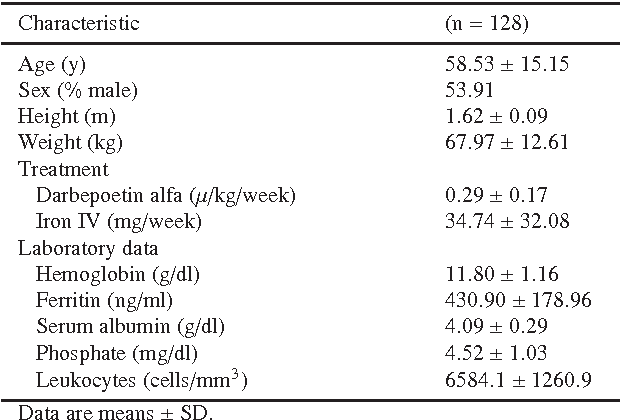

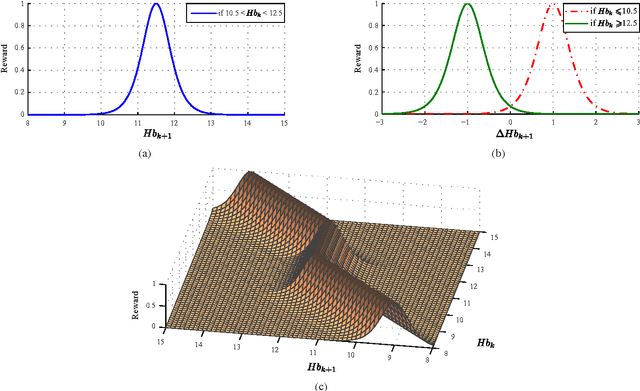
Objective: Anemia is a frequent comorbidity in hemodialysis patients that can be successfully treated by administering erythropoiesis-stimulating agents (ESAs). ESAs dosing is currently based on clinical protocols that often do not account for the high inter- and intra-individual variability in the patient's response. As a result, the hemoglobin level of some patients oscillates around the target range, which is associated with multiple risks and side-effects. This work proposes a methodology based on reinforcement learning (RL) to optimize ESA therapy. Methods: RL is a data-driven approach for solving sequential decision-making problems that are formulated as Markov decision processes (MDPs). Computing optimal drug administration strategies for chronic diseases is a sequential decision-making problem in which the goal is to find the best sequence of drug doses. MDPs are particularly suitable for modeling these problems due to their ability to capture the uncertainty associated with the outcome of the treatment and the stochastic nature of the underlying process. The RL algorithm employed in the proposed methodology is fitted Q iteration, which stands out for its ability to make an efficient use of data. Results: The experiments reported here are based on a computational model that describes the effect of ESAs on the hemoglobin level. The performance of the proposed method is evaluated and compared with the well-known Q-learning algorithm and with a standard protocol. Simulation results show that the performance of Q-learning is substantially lower than FQI and the protocol. Conclusion: Although prospective validation is required, promising results demonstrate the potential of RL to become an alternative to current protocols.
* 17 pages, 10 figures