 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Evaluation for Domain Identification of Unknown Classes in Open-World Recognition: A Proposal
Dec 09, 2023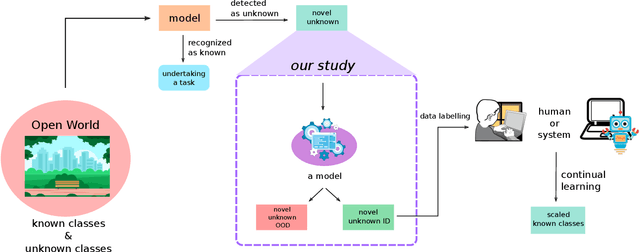
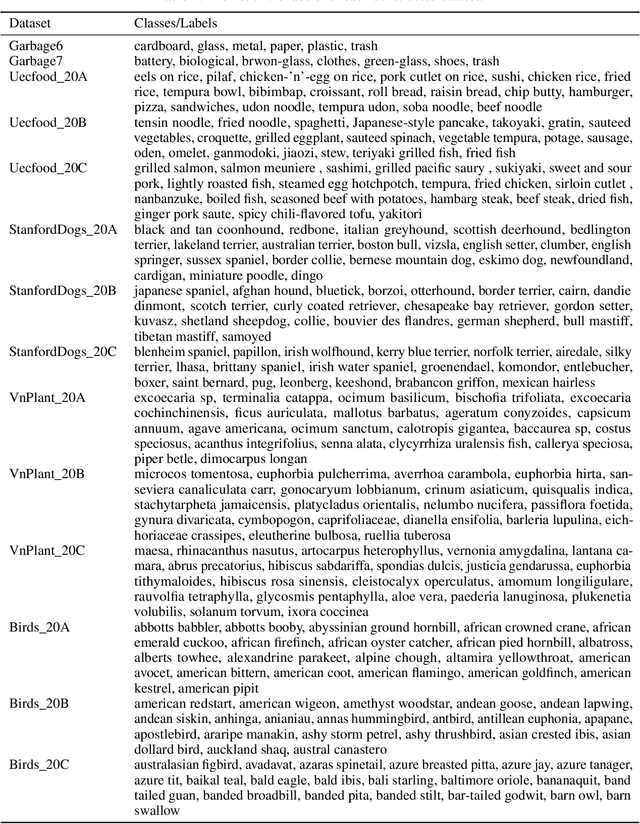
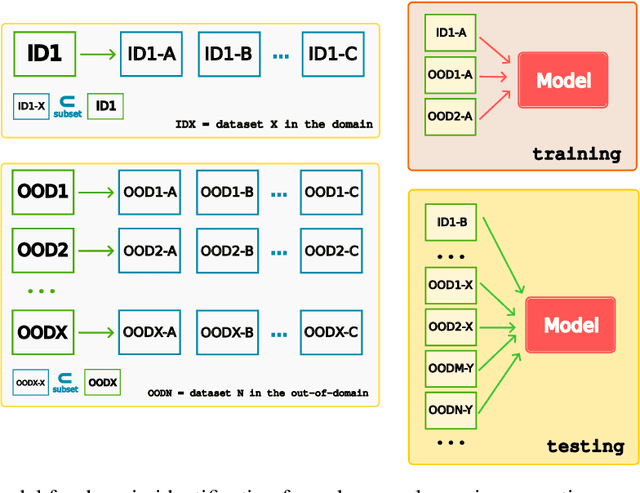
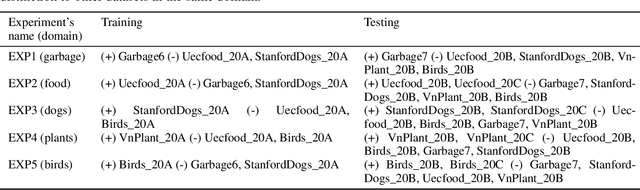
Open-World Recognition (OWR) is an emerging field that makes a machine learning model competent in rejecting the unknowns, managing them, and incrementally adding novel samples to the base knowledge. However, this broad objective is not practical for an agent that works on a specific task. Not all rejected samples will be used for learning continually in the future. Some novel images in the open environment may not belong to the domain of interest. Hence, identifying the unknown in the domain of interest is essential for a machine learning model to learn merely the important samples. In this study, we propose an evaluation protocol for estimating a model's capability in separating unknown in-domain (ID) and unknown out-of-domain (OOD). We evaluated using three approaches with an unknown domain and demonstrated the possibility of identifying the domain of interest using the pre-trained parameters through traditional transfer learning, Automated Machine Learning (AutoML), and Nearest Class Mean (NCM) classifier with First Integer Neighbor Clustering Hierarchy (FINCH). We experimented with five different domains: garbage, food, dogs, plants, and birds. The results show that all approaches can be used as an initial baseline yielding a good accuracy. In addition, a Balanced Accuracy (BACCU) score from a pre-trained model indicates a tendency to excel in one or more domains of interest. We observed that MobileNetV3 yielded the highest BACCU score for the garbage domain and surpassed complex models such as the transformer network. Meanwhile, our results also suggest that a strong representation in the pre-trained model is important for identifying unknown classes in the same domain. This study could open the bridge toward open-world recognition in domain-specific tasks where the relevancy of the unknown classes is vital.
Deep Reinforcement Learning-Based Mapless Crowd Navigation with Perceived Risk of the Moving Crowd for Mobile Robots
Apr 07, 2023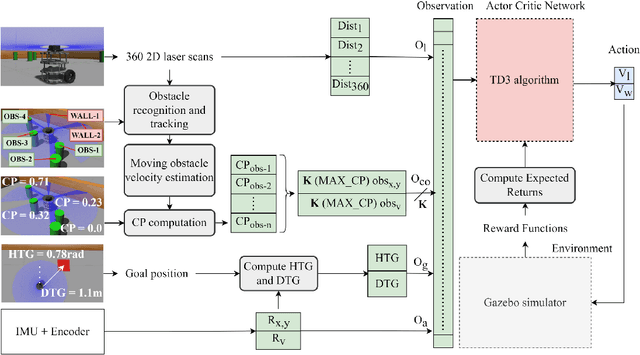
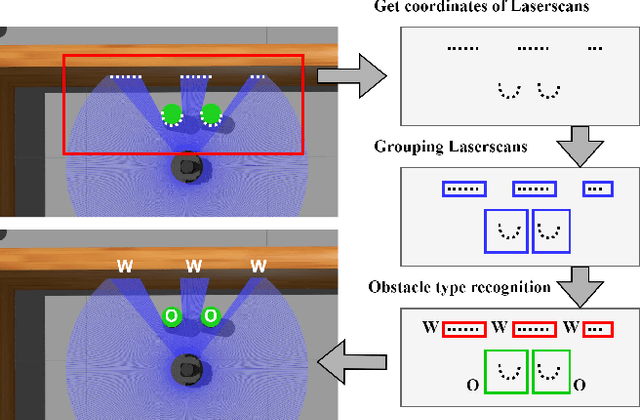
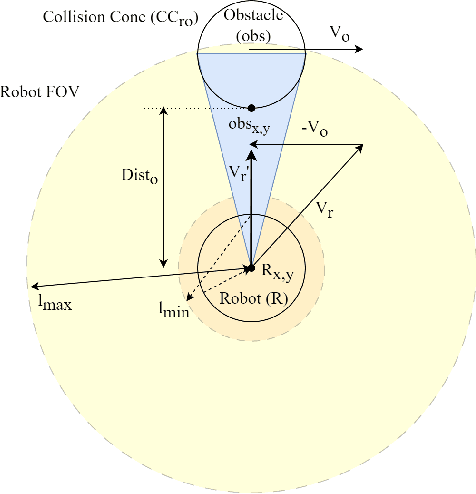
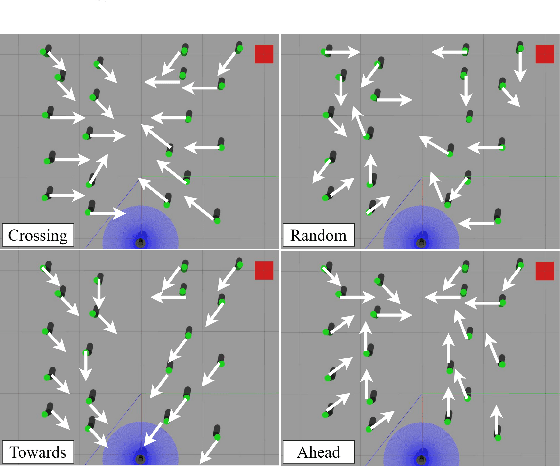
Classical map-based navigation methods are commonly used for robot navigation, but they often struggle in crowded environments due to the Frozen Robot Problem (FRP). Deep reinforcement learning-based methods address the FRP problem, however, suffer from the issues of generalization and scalability. To overcome these challenges, we propose a method that uses Collision Probability (CP) to help the robot navigate safely through crowds. The inclusion of CP in the observation space gives the robot a sense of the level of danger of the moving crowd. The robot will navigate through the crowd when it appears safe but will take a detour when the crowd is moving aggressively. By focusing on the most dangerous obstacle, the robot will not be confused when the crowd density is high, ensuring scalability of the model. Our approach was developed using deep reinforcement learning (DRL) and trained using the Gazebo simulator in a non cooperative crowd environment with obstacles moving at randomized speeds and directions. We then evaluated our model on four different crowd-behavior scenarios with varying densities of crowds. The results shown that our method achieved a 100% success rate in all test settings. We compared our approach with a current state-of-the-art DRLbased approach, and our approach has performed significantly better. Importantly, our method is highly generalizable and requires no fine-tuning after being trained once. We further demonstrated the crowd navigation capability of our model in real-world tests.
Profiling Obese Subgroups in National Health and Nutritional Status Survey Data using Machine Learning Techniques: A Case Study from Brunei Darussalam
Nov 09, 2022National Health and Nutritional Status Survey (NHANSS) is conducted annually by the Ministry of Health in Negara Brunei Darussalam to assess the population health and nutritional patterns and characteristics. The main aim of this study was to discover meaningful patterns (groups) from the obese sample of NHANSS data by applying data reduction and interpretation techniques. The mixed nature of the variables (qualitative and quantitative) in the data set added novelty to the study. Accordingly, the Categorical Principal Component (CATPCA) technique was chosen to interpret the meaningful results. The relationships between obesity and the lifestyle factors like demography, socioeconomic status, physical activity, dietary behavior, history of blood pressure, diabetes, etc., were determined based on the principal components generated by CATPCA. The results were validated with the help of the split method technique to counter verify the authenticity of the generated groups. Based on the analysis and results, two subgroups were found in the data set, and the salient features of these subgroups have been reported. These results can be proposed for the betterment of the healthcare industry.
Application of Computer Vision and Machine Learning for Digitized Herbarium Specimens: A Systematic Literature Review
Apr 18, 2021


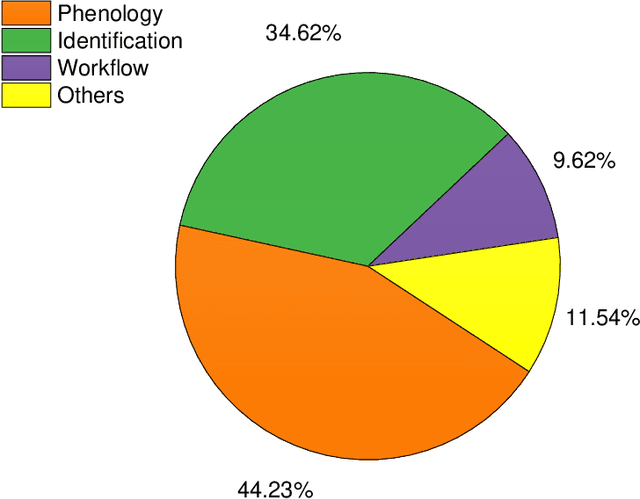
Herbarium contains treasures of millions of specimens which have been preserved for several years for scientific studies. To speed up more scientific discoveries, a digitization of these specimens is currently on going to facilitate easy access and sharing of its data to a wider scientific community. Online digital repositories such as IDigBio and GBIF have already accumulated millions of specimen images yet to be explored. This presents a perfect time to automate and speed up more novel discoveries using machine learning and computer vision. In this study, a thorough analysis and comparison of more than 50 peer-reviewed studies which focus on application of computer vision and machine learning techniques to digitized herbarium specimen have been examined. The study categorizes different techniques and applications which have been commonly used and it also highlights existing challenges together with their possible solutions. It is our hope that the outcome of this study will serve as a strong foundation for beginners of the relevant field and will also shed more light for both computer science and ecology experts.