 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Weighted Vision Transformer-Based Multi-Task Learning Framework for Predicting ADAS-Cog Scores
Aug 25, 2025Prognostic modeling is essential for forecasting future clinical scores and enabling early detection of Alzheimers disease (AD). While most existing methods focus on predicting the ADAS-Cog global score, they often overlook the predictive value of its 13 sub-scores, which reflect distinct cognitive domains. Some sub-scores may exert greater influence on determining global scores. Assigning higher loss weights to these clinically meaningful sub-scores can guide the model to focus on more relevant cognitive domains, enhancing both predictive accuracy and interpretability. In this study, we propose a weighted Vision Transformer (ViT)-based multi-task learning (MTL) framework to jointly predict the ADAS-Cog global score using baseline MRI scans and its 13 sub-scores at Month 24. Our framework integrates ViT as a feature extractor and systematically investigates the impact of sub-score-specific loss weighting on model performance. Results show that our proposed weighting strategies are group-dependent: strong weighting improves performance for MCI subjects with more heterogeneous MRI patterns, while moderate weighting is more effective for CN subjects with lower variability. Our findings suggest that uniform weighting underutilizes key sub-scores and limits generalization. The proposed framework offers a flexible, interpretable approach to AD prognosis using end-to-end MRI-based learning. (Github repo link will be provided after review)
Improving Interpretability in Alzheimer's Prediction via Joint Learning of ADAS-Cog Scores
Aug 25, 2025Accurate prediction of clinical scores is critical for early detection and prognosis of Alzheimers disease (AD). While existing approaches primarily focus on forecasting the ADAS-Cog global score, they often overlook the predictive value of its sub-scores (13 items), which capture domain-specific cognitive decline. In this study, we propose a multi task learning (MTL) framework that jointly predicts the global ADAS-Cog score and its sub-scores (13 items) at Month 24 using baseline MRI and longitudinal clinical scores from baseline and Month 6. The main goal is to examine how each sub scores particularly those associated with MRI features contribute to the prediction of the global score, an aspect largely neglected in prior MTL studies. We employ Vision Transformer (ViT) and Swin Transformer architectures to extract imaging features, which are fused with longitudinal clinical inputs to model cognitive progression. Our results show that incorporating sub-score learning improves global score prediction. Subscore level analysis reveals that a small subset especially Q1 (Word Recall), Q4 (Delayed Recall), and Q8 (Word Recognition) consistently dominates the predicted global score. However, some of these influential sub-scores exhibit high prediction errors, pointing to model instability. Further analysis suggests that this is caused by clinical feature dominance, where the model prioritizes easily predictable clinical scores over more complex MRI derived features. These findings emphasize the need for improved multimodal fusion and adaptive loss weighting to achieve more balanced learning. Our study demonstrates the value of sub score informed modeling and provides insights into building more interpretable and clinically robust AD prediction frameworks. (Github repo provided)
Hybrid Fuzzy-Crisp Clustering Algorithm: Theory and Experiments
Mar 25, 2023With the membership function being strictly positive, the conventional fuzzy c-means clustering method sometimes causes imbalanced influence when clusters of vastly different sizes exist. That is, an outstandingly large cluster drags to its center all the other clusters, however far they are separated. To solve this problem, we propose a hybrid fuzzy-crisp clustering algorithm based on a target function combining linear and quadratic terms of the membership function. In this algorithm, the membership of a data point to a cluster is automatically set to exactly zero if the data point is ``sufficiently'' far from the cluster center. In this paper, we present a new algorithm for hybrid fuzzy-crisp clustering along with its geometric interpretation. The algorithm is tested on twenty simulated data generated and five real-world datasets from the UCI repository and compared with conventional fuzzy and crisp clustering methods. The proposed algorithm is demonstrated to outperform the conventional methods on imbalanced datasets and can be competitive on more balanced datasets.
Profiling Obese Subgroups in National Health and Nutritional Status Survey Data using Machine Learning Techniques: A Case Study from Brunei Darussalam
Nov 09, 2022National Health and Nutritional Status Survey (NHANSS) is conducted annually by the Ministry of Health in Negara Brunei Darussalam to assess the population health and nutritional patterns and characteristics. The main aim of this study was to discover meaningful patterns (groups) from the obese sample of NHANSS data by applying data reduction and interpretation techniques. The mixed nature of the variables (qualitative and quantitative) in the data set added novelty to the study. Accordingly, the Categorical Principal Component (CATPCA) technique was chosen to interpret the meaningful results. The relationships between obesity and the lifestyle factors like demography, socioeconomic status, physical activity, dietary behavior, history of blood pressure, diabetes, etc., were determined based on the principal components generated by CATPCA. The results were validated with the help of the split method technique to counter verify the authenticity of the generated groups. Based on the analysis and results, two subgroups were found in the data set, and the salient features of these subgroups have been reported. These results can be proposed for the betterment of the healthcare industry.
A Novel Skeleton-Based Human Activity Discovery Technique Using Particle Swarm Optimization with Gaussian Mutation
Jan 14, 2022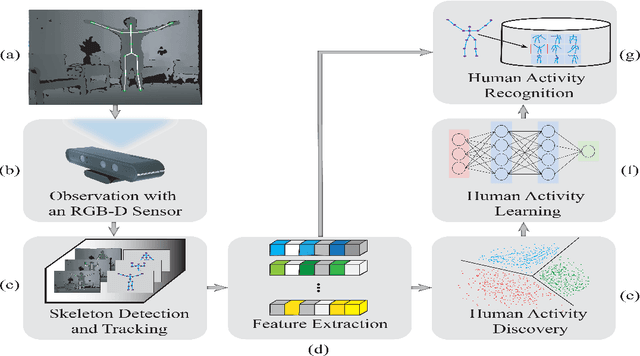

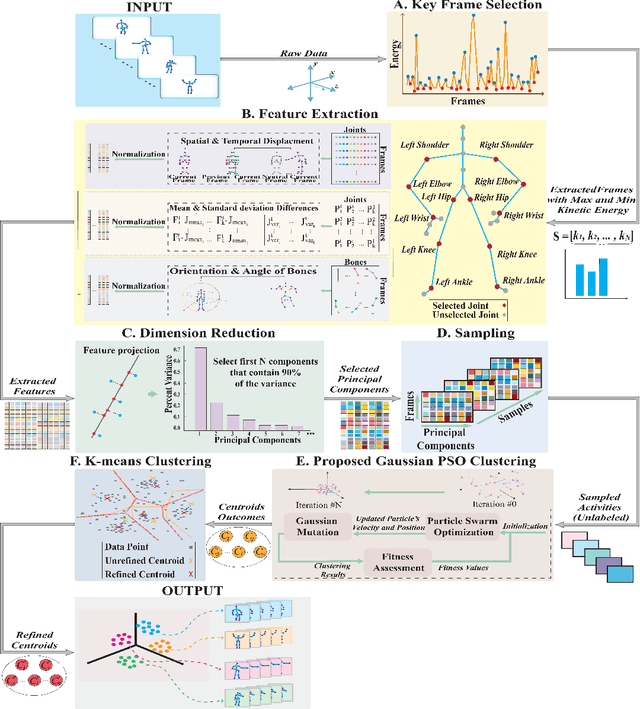
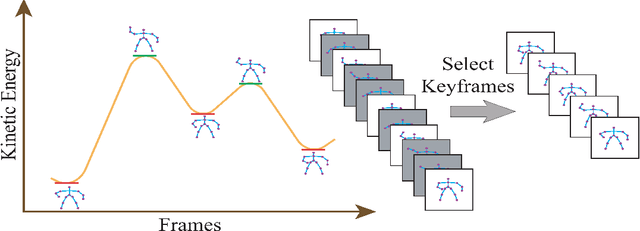
Human activity discovery aims to distinguish the activities performed by humans, without any prior information of what defines each activity. Most methods presented in human activity recognition are supervised, where there are labeled inputs to train the system. In reality, it is difficult to label data because of its huge volume and the variety of activities performed by humans. In this paper, a novel unsupervised approach is proposed to perform human activity discovery in 3D skeleton sequences. First, important frames are selected based on kinetic energy. Next, the displacement of joints, set of statistical, angles, and orientation features are extracted to represent the activities information. Since not all extracted features have useful information, the dimension of features is reduced using PCA. Most human activity discovery proposed are not fully unsupervised. They use pre-segmented videos before categorizing activities. To deal with this, we used the fragmented sliding time window method to segment the time series of activities with some overlapping. Then, activities are discovered by a novel hybrid particle swarm optimization with a Gaussian mutation algorithm to avoid getting stuck in the local optimum. Finally, k-means is applied to the outcome centroids to overcome the slow rate of PSO. Experiments on three datasets have been presented and the results show the proposed method has superior performance in discovering activities in all evaluation parameters compared to the other state-of-the-art methods and has increased accuracy of at least 4 % on average. The code is available here: https://github.com/parhamhadikhani/Human-Activity-Discovery-HPGMK