 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLASSP: a Biologically-Inspired Approach to Continual Learning through Adjustment Suppression and Sparsity Promotion
Apr 29, 2024This paper introduces a new biologically-inspired training method named Continual Learning through Adjustment Suppression and Sparsity Promotion (CLASSP). CLASSP is based on two main principles observed in neuroscience, particularly in the context of synaptic transmission and Long-Term Potentiation (LTP). The first principle is a decay rate over the weight adjustment, which is implemented as a generalization of the AdaGrad optimization algorithm. This means that weights that have received many updates should have lower learning rates as they likely encode important information about previously seen data. However, this principle results in a diffuse distribution of updates throughout the model, as it promotes updates for weights that haven't been previously updated, while a sparse update distribution is preferred to leave weights unassigned for future tasks. Therefore, the second principle introduces a threshold on the loss gradient. This promotes sparse learning by updating a weight only if the loss gradient with respect to that weight is above a certain threshold, i.e. only updating weights with a significant impact on the current loss. Both principles reflect phenomena observed in LTP, where a threshold effect and a gradual saturation of potentiation have been observed. CLASSP is implemented in a Python/PyTorch class, making it applicable to any model. When compared with Elastic Weight Consolidation (EWC) using Computer Vision datasets, CLASSP demonstrates superior performance in terms of accuracy and memory footprint.
End-to-end Adversarial Learning for Generative Conversational Agents
Jan 08, 2018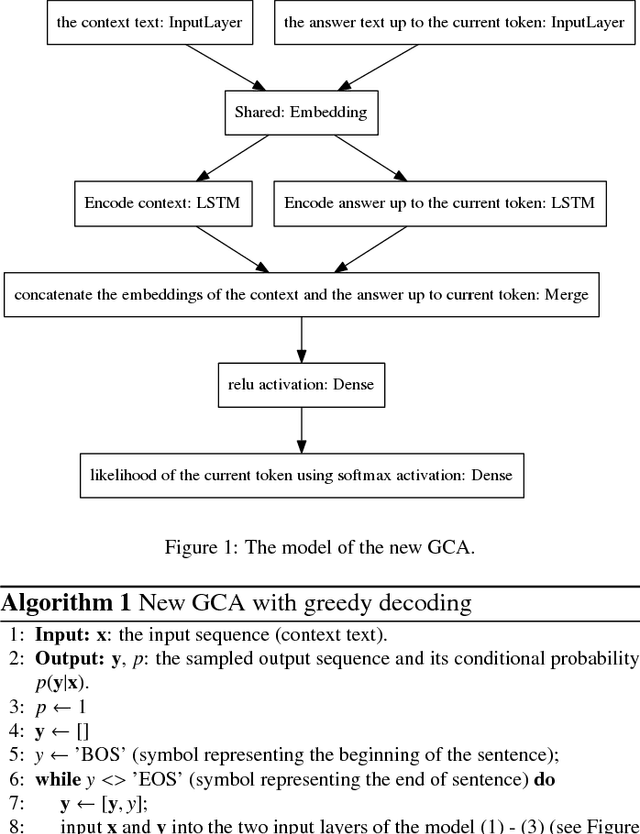
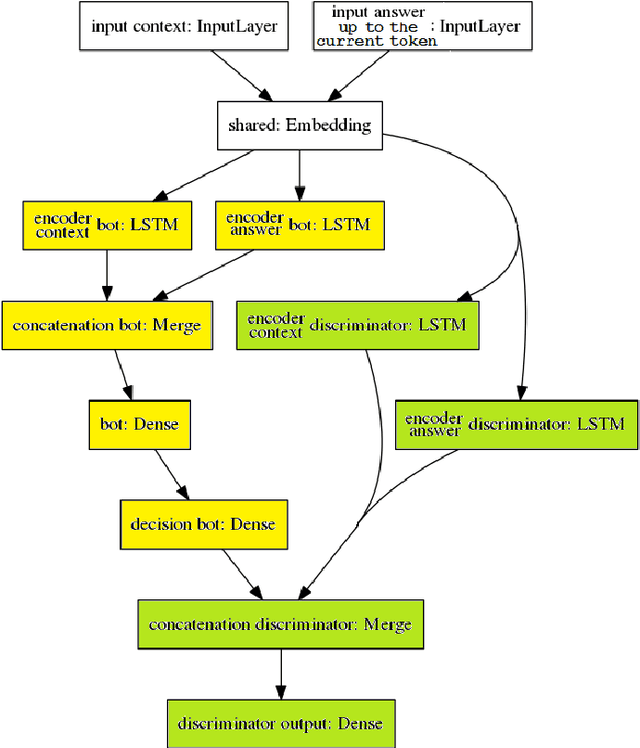
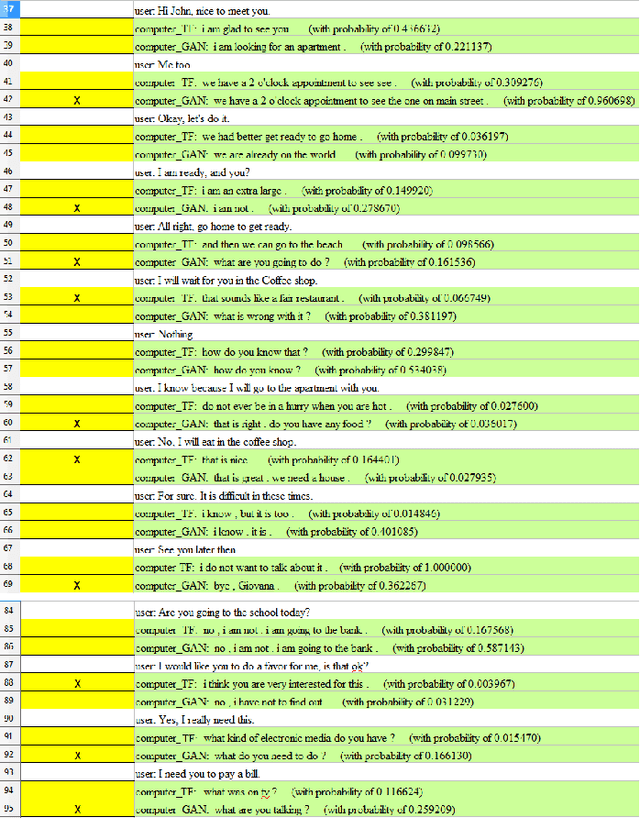
This paper presents a new adversarial learning method for generative conversational agents (GCA) besides a new model of GCA. Similar to previous works on adversarial learning for dialogue generation, our method assumes the GCA as a generator that aims at fooling a discriminator that labels dialogues as human-generated or machine-generated; however, in our approach, the discriminator performs token-level classification, i.e. it indicates whether the current token was generated by humans or machines. To do so, the discriminator also receives the context utterances (the dialogue history) and the incomplete answer up to the current token as input. This new approach makes possible the end-to-end training by backpropagation. A self-conversation process enables to produce a set of generated data with more diversity for the adversarial training. This approach improves the performance on questions not related to the training data. Experimental results with human and adversarial evaluations show that the adversarial method yields significant performance gains over the usual teacher forcing training.
Deep Learning with Eigenvalue Decay Regularizer
May 08, 2016

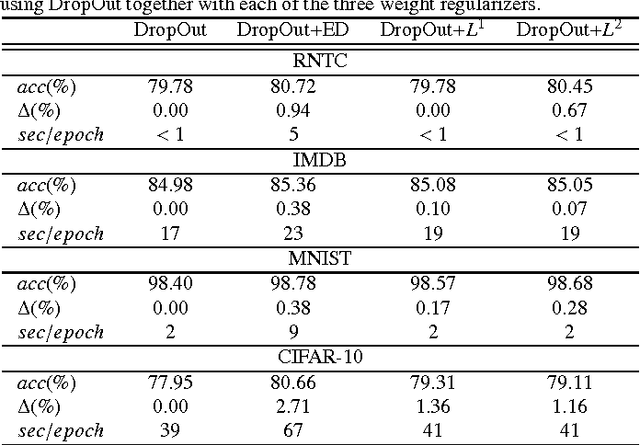
This paper extends our previous work on regularization of neural networks using Eigenvalue Decay by employing a soft approximation of the dominant eigenvalue in order to enable the calculation of its derivatives in relation to the synaptic weights, and therefore the application of back-propagation, which is a primary demand for deep learning. Moreover, we extend our previous theoretical analysis to deep neural networks and multiclass classification problems. Our method is implemented as an additional regularizer in Keras, a modular neural networks library written in Python, and evaluated in the benchmark data sets Reuters Newswire Topics Classification, IMDB database for binary sentiment classification, MNIST database of handwritten digits and CIFAR-10 data set for image classification.
Deep Embedding for Spatial Role Labeling
Mar 28, 2016


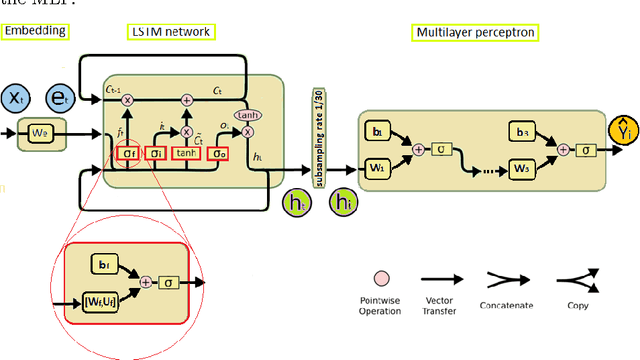
This paper introduces the visually informed embedding of word (VIEW), a continuous vector representation for a word extracted from a deep neural model trained using the Microsoft COCO data set to forecast the spatial arrangements between visual objects, given a textual description. The model is composed of a deep multilayer perceptron (MLP) stacked on the top of a Long Short Term Memory (LSTM) network, the latter being preceded by an embedding layer. The VIEW is applied to transferring multimodal background knowledge to Spatial Role Labeling (SpRL) algorithms, which recognize spatial relations between objects mentioned in the text. This work also contributes with a new method to select complementary features and a fine-tuning method for MLP that improves the $F1$ measure in classifying the words into spatial roles. The VIEW is evaluated with the Task 3 of SemEval-2013 benchmark data set, SpaceEval.