 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Embedding for Spatial Role Labeling
Paper and Code
Mar 28, 2016


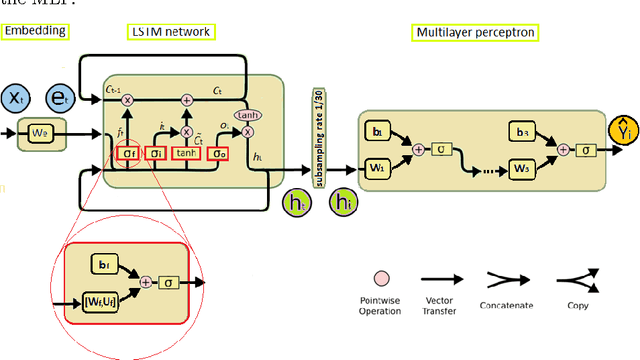
This paper introduces the visually informed embedding of word (VIEW), a continuous vector representation for a word extracted from a deep neural model trained using the Microsoft COCO data set to forecast the spatial arrangements between visual objects, given a textual description. The model is composed of a deep multilayer perceptron (MLP) stacked on the top of a Long Short Term Memory (LSTM) network, the latter being preceded by an embedding layer. The VIEW is applied to transferring multimodal background knowledge to Spatial Role Labeling (SpRL) algorithms, which recognize spatial relations between objects mentioned in the text. This work also contributes with a new method to select complementary features and a fine-tuning method for MLP that improves the $F1$ measure in classifying the words into spatial roles. The VIEW is evaluated with the Task 3 of SemEval-2013 benchmark data set, SpaceEval.